
 Logo:
Logo:  Areas Served:
Areas Served: Synthetic Data Generation in Foundation Models and Differential Privacy: Three Papers from Microsoft Research
Author(s): Jesus Rodriguez
Originally published on Towards AI.

I recently started an AI-focused educational newsletter, that already has over 170,000 subscribers. TheSequence is a no-BS (meaning no hype, no news, etc) ML-oriented newsletter that takes 5 minutes to read. The goal is to keep you up to date with machine learning projects, research papers, and concepts. Please give it a try by subscribing below:
TheSequence | Jesus Rodriguez | Substack
The best source to stay up-to-date with the developments in the machine learning, artificial intelligence, and data…
thesequence.substack.com
The use of synthetic data for pretraining and fine-tuning foundation models is one of the most interesting topics in generative AI. Many experts have proclaimed the “end of data” as a relevant phenomenon we might face given the fast growth of foundation models. Using synthetic data to augment those processes seems like the most obvious alternative but its far from trivial. You need real data to produce synthetic data and that comes with real compliance and security risks. Differential privacy(DP) is one of the techniques that has emerged recently as a novel way to overcome the challenges with synthetic data generation.
Microsoft Research has been doing some innovative work at the intersection of DP and synthetic data generation for foundation models. Recently, they published three research papers that tackle some of the fundamental challenges in this area:
1. Recipes for using DP for synthetic data generation.
2. DP for synthetic data generation using foundation model inference APIs.
3. DP and synthetic data for few-shot learning scenarios.
Here is how the three approaches relate to the synthetic data generation workflow in foundation models:
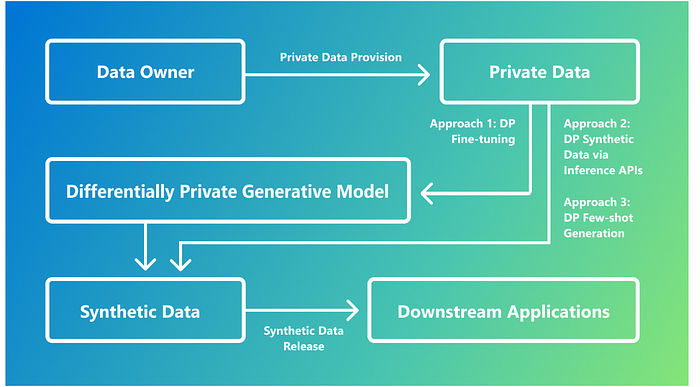
Microsoft Research is delving into differentially private (DP) synthetic data generation to facilitate machine learning innovations while maintaining data privacy. This technique aims to create data that mirrors real-world sources statistically. However, if the generated data too closely resembles the original, it can compromise privacy by replicating identifiable details. DP serves as a safeguard here, offering a mathematical framework that ensures computations remain relatively unchanged by the presence or absence of individual data points. By leveraging DP techniques, researchers can produce synthetic datasets that retain the original data’s statistical attributes while obscuring information that could identify contributors.
1) Synthetic Text Generation with Differential Privacy: A Practical Approach
Generative Large Language Models (LLMs) can produce synthetic text by sampling their outputs. One effective method is to fine-tune an LLM on representative data, such as a collection of scientific papers, to generate realistic scientific writing. However, generating synthetic text from private documents, like medical notes or personal emails, poses privacy risks due to LLMs’ ability to memorize training data.
In Synthetic Text Generation with Differential Privacy: A Simple and Practical Recipe(opens in new tab), Microsoft researchers presented a method to use a private data corpus for synthetic generation without compromising privacy. They applied differentially private stochastic gradient descent (DP-SGD) to fine-tune an LLM on private documents, ensuring a strong privacy guarantee. This method provides a mathematical assurance that the model’s parameters and outputs remain relatively unaffected by any single user’s data.

The researchers validated this approach by training on restaurant reviews with varying privacy levels, then generating new reviews for classification tasks like sentiment analysis and genre classification. The results, summarized in Table 1, showed minimal accuracy loss compared to using raw private data, demonstrating that realistic synthetic data can be generated without sacrificing privacy.
2) Generating Differentially Private Synthetic Data via Foundation Model APIs
Training large models can be challenging due to high computational requirements and restricted access to proprietary models. In Differentially Private Synthetic Data via Foundation Model APIs 1: Images and Differentially Private Synthetic Data via Foundation Model APIs 2: Text, Microsoft researchers explored generating synthetic data using only inference API access, even with models controlled by third parties. They employed a differentially private sampling method called Private Evolution (PE), which bypasses the need for DP-SGD fine-tuning.

PE accesses model inference APIs to generate data that closely resembles a private corpus while maintaining a DP guarantee. This approach is compatible with large, non-fine-tunable models accessible only through inference APIs, offering a practical solution for synthetic data generation with privacy protection.
3) Privacy-Preserving In-Context Learning with Differentially Private Few-Shot Generation
In-context learning involves providing a model with demonstration examples before task execution, leveraging LLMs’ generalization capabilities. When only private labeled examples are available, directly using them poses a privacy risk.
In Privacy-Preserving In-Context Learning with Differentially Private Few-Shot Generation, Microsoft researchers proposed a solution that synthesizes demonstration examples from a private corpus while ensuring privacy. This method incrementally samples from a token distribution defined by the private examples, adding noise to maintain a privacy bound for each sample.

The topic of DP and synthetic data in foundation models is relatively nascent but quite promising. Microsoft Research’s efforts in DP synthetic data generation seem to be targeting the right challenges in order to offer robust privacy guarantees while enabling the production of realistic, useful synthetic data. These methods pave the way for secure and practical applications in various fields requiring data privacy.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Related posts
Popular posts

 for 2021")



Updates

Recent Posts


