


NLP News Cypher | 10.18.20
Last Updated on July 24, 2023 by Editorial Team
Author(s): Ricky Costa
Originally published on Towards AI.
NATURAL LANGUAGE PROCESSING (NLP) WEEKLY NEWSLETTER
NLP News Cypher U+007C 10.18.20
Crash Override
Hey welcome back! It’s a brand new week. And if you are unaware, we tapped into the gold mine of arXiv’s new code link feature (mentioned in last week’s newsletter). Recently, arXiv collaborated with PapersWithCode to conveniently link any associated repos to its accompanying paper on the abstract page (which is much better than stalking the PDF). U+1F447
Well… we wanted to know if we could extract links to say… all of the NLP-related papers published in a trailing 5-day week?!?! Please note that papers on arXiv are published Mon-Fri and can vary in totals ranging between 300–500 papers on a weekly basis for NLP-related material.
This past week, there were 330 papers published in the Computation and Language directory. Of these, 108 had GitHub links U+1F440. That’s roughly a .300 batting average (which is slightly above 17–20% rate of late). The rest didn’t have code but had the paper linked to the PapersWithCode website. The last 11 or so didn’t include either, these were excluded, giving us a total of 319. (Keep in mind that code can be added later on, so it is possible that some of the abstracts may have been populated with code in the last 72 hours and thus my stats can be slightly off)
The data dump has 3 fields:
URL of the abstract,
Title of the Abstract
Code to GitHub pages (if available) or PwC.
arxiv
arxiv_10_17 id,url,title,code 1, https://arxiv.org/abs/2010.07375 ,[2010.07375] Decoding Methods for Neural Narrative…
docs.google.com
Cool fact: Older papers have been retroactively appended with code links even though this feature is only a week old.(e.g. https://arxiv.org/abs/2005.11787 For example, this paper was submitted in May but has a code url).
In conclusion, this has been an awesome time experimenting and the amount data obtained is kind of nuts. Tons of new libraries and associated notebooks were discovered pretty fast.
BTW, if you want to get an awesome selection of NLP papers and other research news you can always sign up to our newsletter. (FYI, by ‘NLP papers’ I’m not referring to an arXiv data dump like the one linked above, this was just a one-off U+1F625)
Sign-up here: https://quantumstat.com
…if you can replicate this adventure, you are a true Jedi Master.U+1F469U+1F4BB
IBM research papers at INTERSPEECH 2020
talkin’ about papers…
IBM Research at INTERSPEECH 2020 U+007C IBM Research Blog
The 21st INTERSPEECH Conference will take place as a fully virtual conference from October 25 to October 29…
www.ibm.com
New Stanford Seminar
For those interested in building modern ML stacks and applying them in the real world, this new Stanford seminar series just got off the ground:
Last but not least, special thanks to Sebastian Ruder for giving the Super Duper NLP Repo a nice shout-out in his newsletter! U+1F60E
ML and NLP starter toolkit, Low-resource NLP toolkit, "Can a LM understand natural language?", The…
Hi all,It has been a while… I hope you're doing well in these crazy and strange times.COVID-19 has affected each of…
newsletter.ruder.io
Spotify Open-Sources Klio
Spotify is on GitHub bruh! Klio is their file processing library that allows you to process large audio files (or any binary file). It’s built over Apache Beam.
GitHub:
spotify/klio
Klio is an ecosystem that allows you to process audio files – or any binary files – easily and at scale. Klio jobs are…
github.com
Post-Deployment AI Management
In this white paper from O’Reilly, the subject of MLOps is discussed focusing on areas in production. The article discusses: keeping tabs on signs of domain shift in data, service level indicators so one knows the expected performance of a model in production, model monitoring and much more.
White Paper:
AI Product Management After Deployment
The field of AI product management continues to gain momentum. As the AI product management role advances in maturity…
www.oreilly.com
Multilingual Factual Knowledge Retrieval
Want to know how many facts your language model knows about the data it was trained on, (but in a multilingual style)? X-FACTR is a benchmark that does just this. (it also does multi-token). The benchmark follows the factual knowledge expressed in the form of subject-relation-object triples from the T-REx dataset.
“X-FACTR is a multilingual benchmark for probing factual knowledge in language models. Prompts in 23 languages are created by native speakers to probe factual knowledge in LMs by having them fill in the blanks of prompts such as: Punta Cana is located in _.”
Language Support:
en(English),fr(French),nl(Dutch),ru(Russian),es(Spanish),jp(Japanese),vi(Vietnamese),zh(Chinese),hu(Hungarian),ko(Korean),tr(Turkish),he(Hebrew),el(Greek),war(Waray),mr(Marathi),mg(Malagasy),bn(Bengali),tl(Tagalog),sw(Swahili),pa(Punjabi),ceb(Cebuano),yo(Yoruba),ilo(Ilokano)
X-FACTR
Multilingual Factual Knowledge Retrieval from Pretrained Language Models View My GitHub Profile X-FACTR is a…
x-factr.github.io
GitHub:
jzbjyb/X-FACTR
X-FACTR is a multilingual benchmark for probing factual knowledge in language models. Prompts in 23 languages are…
github.com
Annotation-Tools Repo
Mariana Neves has an awesome repo that indexes annotation tools across various domains for your NLP needs. They also have a web app that allows you to search their index. If you are involved in data annotation, bookmark this:
mariananeves/annotation-tools
We have evaluated all tools with regard to many criteria. Further, we developed a Web application for searching for the…
github.com
News-Please
News-Please is a news crawler that extracts structured information from… you guessed it, news articles. This is isn’t just a scraper, this library also allows you to crawl and extract news articles from the commoncrawl.org site!
Here’s an example JSON output:
fhamborg/news-please
Permalink GitHub is home to over 50 million developers working together to host and review code, manage projects, and…
github.com
GitHub:
fhamborg/news-please
news-please is an open source, easy-to-use news crawler that extracts structured information from almost any news…
github.com
SpaCy 3.0
SpaCy update U+1F525. Transformers pipeline is dope. And they now support multi-task learning. Their update supports newly trained models for 16 languages and 51 pipelines. Read more here:
Introducing spaCy v3.0 nightly · Explosion
spaCy v3.0 is going to be a huge release! It features new transformer-based pipelines that get spaCy's accuracy right…
explosion.ai
Honorable Papers
Commonsense and Adapters: https://arxiv.org/pdf/2005.11787.pdf
Abductive Reasoning: https://arxiv.org/pdf/2010.05906.pdf
BioMegatron: https://arxiv.org/pdf/2010.06060.pdf
Dataset of the Week: DialoGLUE
What is it?
DialoGLUE is a conversational AI benchmark containing 7 datasets pertaining to task-oriented dialogue.
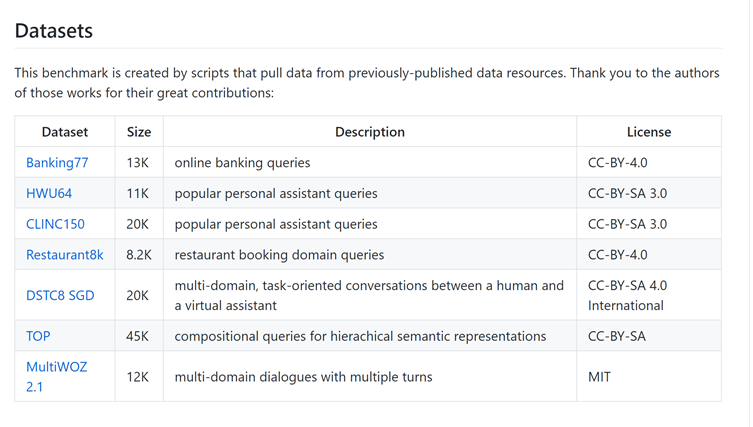
Where is it?
alexa/dialoglue
DialoGLUE is a conversational AI benchmark designed to encourage dialogue research in representation-based transfer…
github.com
Paper: https://arxiv.org/pdf/2009.13570.pdf
Every Sunday we do a weekly round-up of NLP news and code drops from researchers around the world.
For complete coverage, follow our Twitter: @Quantum_Stat
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts



")


