



Breaking it Down: Gradient Descent
Last Updated on January 6, 2023 by Editorial Team
Author(s): Jacob Bumgarner
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Exploring and visualizing the mathematical fundamentals of gradient descent with Grad-Descent-Visualizer.
Outline
1. What is Gradient Descent?
2. Breaking Down Gradient Descent
2.1 Computing the Gradient
2.2 Descending the Gradient
3. Visualizing Multivariate Descents with Grad-Descent-Visualizer
3.1 Descent Montage
4. Conclusion: Contextualizing Gradient Descent
5. Resources
1. What is Gradient Descent?
Gradient descent is an optimization algorithm that is used to improve the performance of deep/machine learning models. Over a repeated series of training steps, gradient descent identifies optimal parameter values that minimize the output of a cost function.
In the next two sections of this post, we’ll step down from this satellite-view description and break down gradient descent into something a bit easier to understand. We will also visualize the gradient descent of various test functions with my Python package, grad-descent-visualizer.
2. Breaking Down Gradient Descent
To gain an intuitive understanding of gradient descent, let’s first ignore machine learning and deep learning. Let’s instead start with a simple function:
The goal in gradient descent is to find the minima of a function or the lowest possible output value of that function. This means that given our above function f(x), the goal of gradient descent will be to find the value of x that leads the output of f(x) to approach 0. By visualizing this function (below), it’s quite obvious to see that x = 0 produces the minima of f(x).
The important part of gradient descent is: if we initialize x to some random number, say x = 1.8, is there some way to automatically update x so that it eventually produces the minimal output of the function? Indeed, we can automatically find this minimal output with a two-step process:
- Find the slope of the function at the point where our input parameter x sits.
- Update our input parameter x by stepping it down the gradient.
In our simple gradient descent algorithm, this two-step process is repeated over and over until the output of our function stabilizes at a minimum, or reaches a defined gradient tolerance level. Of note, other more efficient descent algorithms take different approaches (e.g., RMSProp, AdaGrad, Adam).
2.1. Computing the gradient
To find the slope (or gradient, hence gradient descent) of the function f(x) at any value of x, we can differentiate* the function. Differentiating the simple example function is simple with the power rule (below), providing us with: f’(x) = 2x.
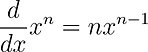
Using our starting point x = 1.8, we find our starting gradient of x (dx) to be dx = 3.6.
Let’s write a simple function in python to automatically compute the derivative of any input variable for f(x) = x².
*I’d strongly recommend checking out 3Blue1Brown’s video to intuitively understand differentiation. The differentiation of this sample function from first principles can be seen here.
Gradient at x = 1.8: dx = 3.6
2.2. Descending the gradient
Once we find the gradient of the starting point, we want to update our input parameter so that it steps down this gradient. Doing this will minimize the output of the function.
To move a variable down its gradient, we can simply subtract the gradient from the input parameter. However, if you’ve looked closely, you may have noticed that subtracting the entire gradient from the input parameter x=1.8 would cause it to infinitely bouncing back and forth between 1.8 and -1.8, preventing it from ever coming close to 0.
Instead, we can define a Learning Rate = 0.1. We’ll scale the dx with this learning rate before subtracting it from x. By tuning the learning rate, we can create ‘smoother’ descents. Large learning rates produce large jumps along the function, and small learning rates lead to small steps along the function.
Lastly, we’ll eventually have to stop the gradient descent. Otherwise, the algorithm would continue endlessly as the gradient approaches 0. For this example, we’ll simply stop the descent once dx is less than 0.01. In your own IDE, you can alter the learning_rate and tolerance parameters to see how the iterations and the output of x vary.
Function minimum found in 27 iterations. X = 0.00
As seen in the video above, our starting value of x = 1.8 was able to automatically be updated to x = 0.0 through the iterative process of gradient descent.
3. Visualizing Multivariate Descents with Grad-Descent-Visualizer
Hopefully, this univariate example provided some foundational insight into what gradient descent actually does. Now let’s expand to the context of multivariate functions.
We’ll first visualize a gradient descent of Himmelblau’s function.
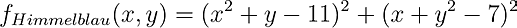
There are a few key differences in the descent of multivariate functions.
First, we need to compute partial derivatives to update each parameter. In Himmelblau’s function, the gradient of x depends on y (their sums are squared, requiring the chain rule). This means that the formula used to differentiate x will contain y and vice versa.
Second, you may have noticed that there was only one minimum in the simple function from Section 2. In reality, there may be many unknown local minima in our cost functions. This means that the local minima that our parameters find will depend on their starting positions and the behavior of the gradient descent algorithm.
To visualize the descent of this landscape, we’re going to initialize our starting parameters as x = -0.4 and y = -0.65. We can then watch the descent of each parameter in its own dimension and a 2D descent, sliced by the position of the opposite parameter.
For greater context, let’s visualize the descent of the same point in 3D using my grad-descent-visualizer package created with the help of PyVista.
3.1 Descent Montage
Now let’s visualize the descent of some more test functions! We’ll place a grid of points across each of these functions and watch how the points move as they descend whatever gradient they are sitting on.
The Sphere Function.
The Griewank Function.
The Six-Hump Camel Function. Notice the many local minima of the function.
Let’s re-visualize a gridded descent of the Himmelblau Function. Notice how different parameter initializations lead to different minima.
And lastly, the Easom Function. Notice how many points sit still because they are initialized on a flat gradient.
4. Conclusion: Contextualizing Gradient Descent
So far, we’ve worked through gradient descent with a univariate function and have visualized the descent of several multivariate functions. In reality, modern deep learning models have vastly more parameters than the functions that we’ve examined.
For example, Hugging Face’s newest natural language processing model, Bloom, has 175 billion parameters. The chained functions used in this model are also more complicated than our test functions.
However, it’s important to realize that the foundations of what we’ve learned about gradient descent still apply. During each iteration of training of any deep learning model, the gradient of every parameter is calculated. This gradient will then be averaged across the training examples and then subtracted from the parameters so that they ‘step down’ their gradients, pushing them to produce a minimal output from the model’s cost function.
Thanks for reading!
5. Resources
- Grad-Descent-Visualizer
- 3Blue1Brown
- Gradient Descent
- Derivatives
- Simon Fraser University: Test Functions for Optimization
- PyVista
- Michael Nielsen's Neural Networks and Deep Learning
Breaking it Down: Gradient Descent was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

