



Modern Spam Detection with DistilBERT on NVIDIA Triton
Last Updated on July 31, 2022 by Editorial Team
Author(s): Jiri Pik
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Authors: Jiri Pik, Saumya Ahuja, Janakan Arulkumarasan, Ermanno Attardo, Kshitiz Gupta, Jiahong Liu
1. Introduction
Unwanted and unsolicited bulk digital communication (“spam”) is responsible for substantial direct and indirect economic damage every year.
Traditional ways to identify spam by detecting certain keywords, manually reviewing text records, or even running Natural Language Processing (“NLP”) pipelines are no longer sufficient.
This article describes the architecture of a state-of-the-art Spam Detection Engine for social network posts with URL links consisting of multiple inter-dependent distinct classifiers delivering real-time, high-performance, superior accuracy with the minimum required manual review.
This article presents a 3-part spam detection system that combines the best available technology approaches and focuses on the DistilBERT model for the NLP classifier.
The application of NVIDIA Triton Inference Server for this use case provides the inference throughput 2.4 times higher than AWS TorchScript Inference Server with 52.9 times lower model latency.
The article’s GitHub Repository is https://github.com/jiripik/nvidia-triton-c-suite-labs-spam-detection-engine.
2. Single-Factor Approaches do NOT work
Over time we realized that there is no reliable public API taking into multiple factors to generate an overall spam score.
Partial, single-factor solutions simply do not work:
- Block lists do not work — solutions that block known abusive domains, keywords, IP addresses, or usernames are amazingly easy to bypass
- Text Analysis Approaches do not work — solutions analyzing text in comments, such as OOPSpam, fail to address the text hidden in the preview image or in the destination page
- Domain-Based Approaches do not work — solutions aiming at determining if the URL links are safe by studying the reputation of the hosting domain, such as Google Web Risk API, do not work — anybody can upload a video containing spammy text to YouTube, and these services would consider it safe since it’s hosted on a trusted domain (YouTube).
3. A Blueprint for a Modern Spam Detection Engine
We approach the problem from three distinct angles: User, Message, and Link. Each social network’s record comes from a source, i.e., the user, from a device with an IP address following a certain sequence of UI steps. The record’s content has a message and may contain a link.
Our joint design consists of an ensemble of models:
- IP & URL Models
- Poster’s IP address — The IP addresses of the source are effective spam indicators, and blocking them over time can significantly reduce spam posts. Our engine identifies the IP addresses consistently posting spam.
- Link URL Domain — Spam URLs follow similar patterns. Hence if the URL pattern matches previously reported URLs, it is predictive of spam. The key features are:
+ url_age: time for which the link has been active on the web
+ url_wot_score: Web of Trust score of the URL
+ url_google_score: the Google Web Risk score for the URL
+ url_domain: the domain of the URL
+ url_tld: the network location top-level domain of the URL
+ url_subdomain_count: the number of subdomains in the URL
+ url_token: the concatenated path tokens extracted from URL text - Link URL Context — We run data wrangling techniques on the historical data of the platform and generate such features that correlate to the spam:
+ url_post_count: the number of times the URL has been posted
+ post_share_count: the number of times the message with the URL is shared
+ post_comment_count: the number of responses responses/traction does the post gets
+ domain_report_count: the number of times the URL’s domain has been reported
+ text_content: the content of the message posted with the URL
2. Social Behavior Models
- Poster Profile — We study features like (1) friends count or (2) the length of time on our platforms, or (3) the user’s past activities on the social networking site. If the user profile is similar to other accounts previously reported as spam, there is a high probability it is a spammer user profile. Also, the history of the user might also be indicative of a spam account. Combining these, the profile features that have a correlation to spam are:
+ user_age: the time for which the user has an account on the platform
+ user_email_domain: the domain of the user’s email address which they are registered
+ user_friends: the number of friends of the user
+ user_followers: the count of followers of the user
+ user_verified: a boolean to determine if the user is influential and verified by the platform
+ user_posts: the number of posts the user has published on the platform
+ user_spam_posts: the number of times the user’s post has been reported as spam
+ user_spam_report: a boolean to determine if the user has been reported as spam
+ user_link_count: the number of times the user has shared this link
+ user_post_count: the number of times the user has shared this post - Poster Journey — We analyze the sequence of steps the user takes to post the social network’s new record. For example, spammers or bots tend to utilize highly efficient workflows.
- Users’ Feedback — We analyze the patterns of other users’ complaints about each social network record
3. Content Models
- NLP analysis — We analyze the user post and the contents of the linked web page, including OCR analysis of any image on the page and the transcript of excerpts of all videos. The model is based upon supervised or semi-supervised learning models, such as BERT and GPT-3.
We apply neural network and machine learning-based approaches to develop a series of models for each of these sub-systems. Their outputs are then fed into the primary machine learning model, a decision tree, that outputs the final classification result:
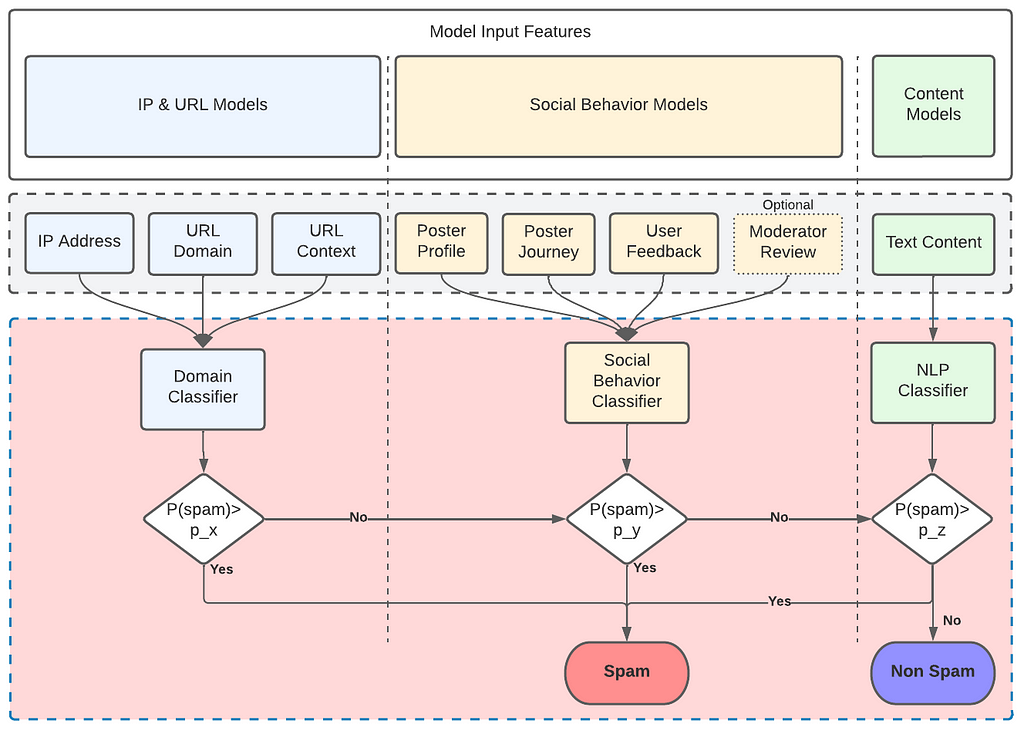
The architecture leads to the following insights:
- If the URL domain is already safely banned, we can reach the immediate conclusion that the new social network’s record is spam and stop.
- Social Behavior Analysis then provides an indication if the user’s new post is spam — for example, past complaints, if present, and the poster journey are an extraordinarily strong indicators (about 90% accuracy) that the new post is spam.
- Finally, we run the NLP analysis on the textual content of the user post and the textual representation of the associated images or videos.
4. Introduction to the Spam Engine’s DistilBERT Content Model
4.1 BERT Models
Google’s Bidirectional Encoder Representations from Transformers (BERT) base uncased models are the current state-of-the-art models for text classification delivering accuracy of over 97% depending on the quality of the training set.
The BERT architecture is based on
- A Transformer Encoder model (a neural network that takes an input sentence and tokenizes each word, the output is a vector numerical representation of each token). It provides better context understanding than LSTM or RNN since it processes sentences simultaneously. It builds context for a word using the inputs before and after it, while LSTM or RNN only accounts for inputs before it → BERT has better performance. For example, the word “apple” in “I need the apple” and “I need the apple product” would have the same vector value in LSTM or RNN but are different in BERT.
- Transfer Learning (train a model for a general task and reuse that to fine-tune BERT to a new task). BERT has been trained on BookCorpus (800M words, 11038 books — same as GPT-1) and the English Wikipedia (2.5B words). It took 4 days on 64 TPUs. Pretraining is slower, but fine-tuning is faster. Sometimes it can be done on a single GPU.
BERT has two tasks:
Task #1: Masked Language Model (MLM) was originally released by Devlin et al in 2018 at Google.
- Predicts a random 15% of (sub)word tokens. To regularize, it: Replaces input words with a mask 80% of the time. Replaces the input word with a random token 10% of the time. It leaves it unchanged 10% of the time (but still predicts it)
- It uses a transformer encoder to do that
- The pretrained inputs to BERT are two separate contiguous sequences
Task #2: Next Sentence Prediction (NSP). The MLM does not support the concept of the relationship between sentences. In this task, the model is taught relationships between sentences.
A study by Sergio Rojas-Galeano highlighted
- The BoW (Bag of Words), TFIDF (Term Frequency Inverse Document Frequency), and BERT encoders can extract effective functions to identify spam using widely used classification algorithms, but BERT performs slightly better. This confirms their quoted previous literature.
- Empirical evidence is that BERT can resist Mad-lib attacks while BoW or TFiDF are vulnerable. It uses an adversarial automatic procedure to generate the attacks.
The study by Andrew McCarren and Jennifer Foster shows that BERT outperforms the neural models based on FFNN, CNN, and LSTM (RNNs).
4.2 DistilBERT Models
For our Spam Detection engine, we chose its DistilBERT variant, which, according to its authors, is “60% of the size of a BERT model while retaining 97% of its language understanding capabilities and being 60% faster”, implying it’s also more cost-effective to apply.
We used its HuggingFace implementation.
4.3 Training Set
Our training set was constructed as a combination of these datasets:
- Professionally labeled spam datasets
- Manually curated spam dataset
- Rule-based labeled dataset.
4.4 Training Code
The simplified implementation of our DistilBERT code is below and in the article’s GitHub repository:
logging.info('Loading the pretrained tokenizer and model')
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
model = DistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased")
logging.info('Preparing the training and evaluation dataset')
train_data, val_data, train_labels, val_labels = train_test_split(dataset[COL_DATA].values, dataset[LABEL].values)
train_tokens = tokenizer(list(train_data), return_tensors="pt", padding=True, truncation=True, max_length=BATCH_SIZE)
val_tokens = tokenizer(list(val_data), return_tensors="pt", padding=True, truncation=True, max_length=BATCH_SIZE)
train_dataset = ClassificationDataset(train_tokens, train_labels)
val_dataset = ClassificationDataset(val_tokens, val_labels)
logging.info('Training Started')
trainer = Trainer(
model=model,
args=TrainingArguments(output_dir=TRAIN_DIR, num_train_epochs=NUM_EPOCHS),
train_dataset=train_dataset,
eval_dataset=val_dataset,
compute_metrics=compute_metrics,
)
trainer.train()
model.save_pretrained(FINAL_DIR)
tokenizer.save_pretrained(FINAL_DIR)
logging.info('Training Completed')
print("**************** Evaluation ************")
metrics = trainer.evaluate()
metrics["eval_samples"] = len(val_dataset)
trainer.log_metrics("eval", metrics)
trainer.save_metrics("eval", metrics)
5. Introduction to NVIDIA TensorRT and NVIDIA Triton Inference Server
NVIDIA® TensorRT™ is an SDK for high-performance deep learning inference, which includes
- a deep learning inference optimizer and runtime that delivers low latency
- high throughput for inference applications.
TensorRT can be understood as a Deep Learning Compiler that produces an NVIDIA GPU-optimized binary executable (“TensorRT engine“).
NVIDIA Triton™ Inference Server is an open-source inference server that helps standardize model deployment and execution and delivers fast and scalable AI in production, supporting most machine learning frameworks, as well as custom C++ and Python code.
Triton’s Backend:
- TensorRT is the recommended backend with Triton for GPU optimal inference.
- The best way to convert your TensorFlow or PyTorch model to TensorRT is to convert it to an ONNX model and then convert the ONNX model to TensorRT. During the ONNX to TensorRT conversion step, the TensorRT Optimizer step runs several optimizations, such as Layer Fusion, which yields a highly GPU-optimized inference model.
- It is possible to choose another Triton-supported backend, such as TensorFlow, Torchscript, ONNX, etc.
The principal reason you should use NVIDIA Triton Inference Server for the deployment of machine learning models is the increased throughput and higher utilization of the hardware compared to the performance provided by other model-serving solutions.
6. AWS Setup
We prefer AWS to other public clouds for its reliability, cost-efficiency, and ease of use. We prefer NVIDIA GPUs for training deep learning models for their performance.
6.1 AWS Inference Environments
AWS offers two solutions for training and deploying machine learning models:
- AWS SageMaker Notebook Instances for training and AWS SageMaker Inference Endpoints for inference
- AWS EC2 instances for training and AWS ECS for inference
Each solution has its advantages and disadvantages:
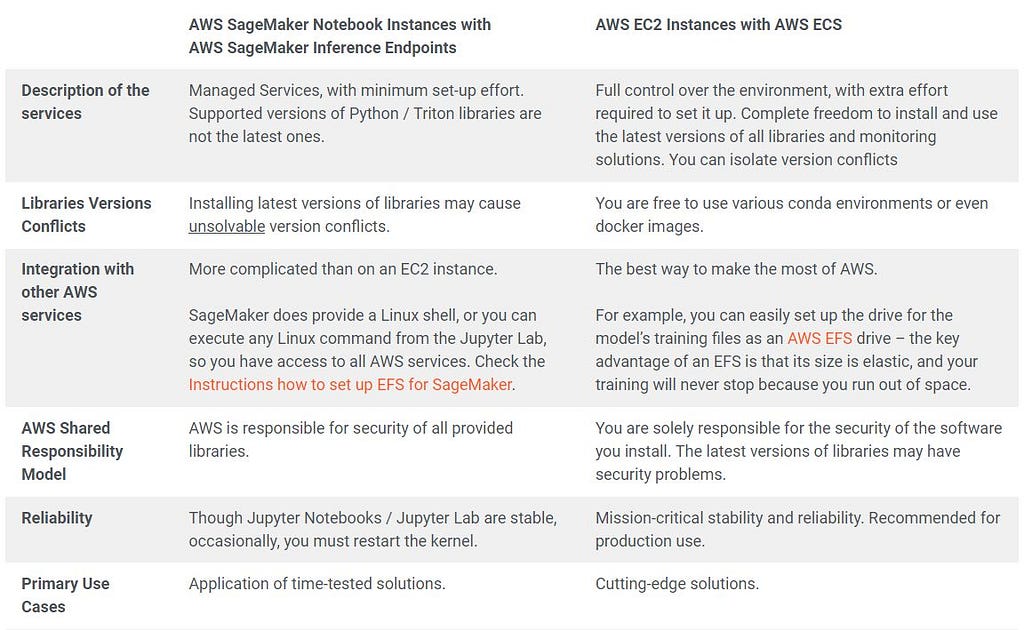
In addition, we strongly advise against using outputs from different versions of PyTorch / TensorFlow as inputs to another version of PyTorch / TensorFlow, for example, trying to import one from an EC2 Instance into a SageMaker Notebook. In most such cases, you will receive an error message only at the end of the ML pipeline — NVIDIA Triton’s SageMaker Endpoint will fail to initialize.
6.2 Deployment of the model to NVIDIA Triton Inference Server
We present below the deployment of the described model using AWS SageMaker Notebook Instance to AWS SageMaker Inference Endpoint running the Docker image of NVIDIA Triton Inference Server.
We describe the steps outlined in the solution’s Jupyter Notebook along with the expected output.
6.2.1 Step 0 — Setting up the AWS SageMaker Notebook Instance
AWS offers multiple compute instance types suitable for deep learning. Check this guide to decide which one is the most suitable for your use case.
We used this instance:
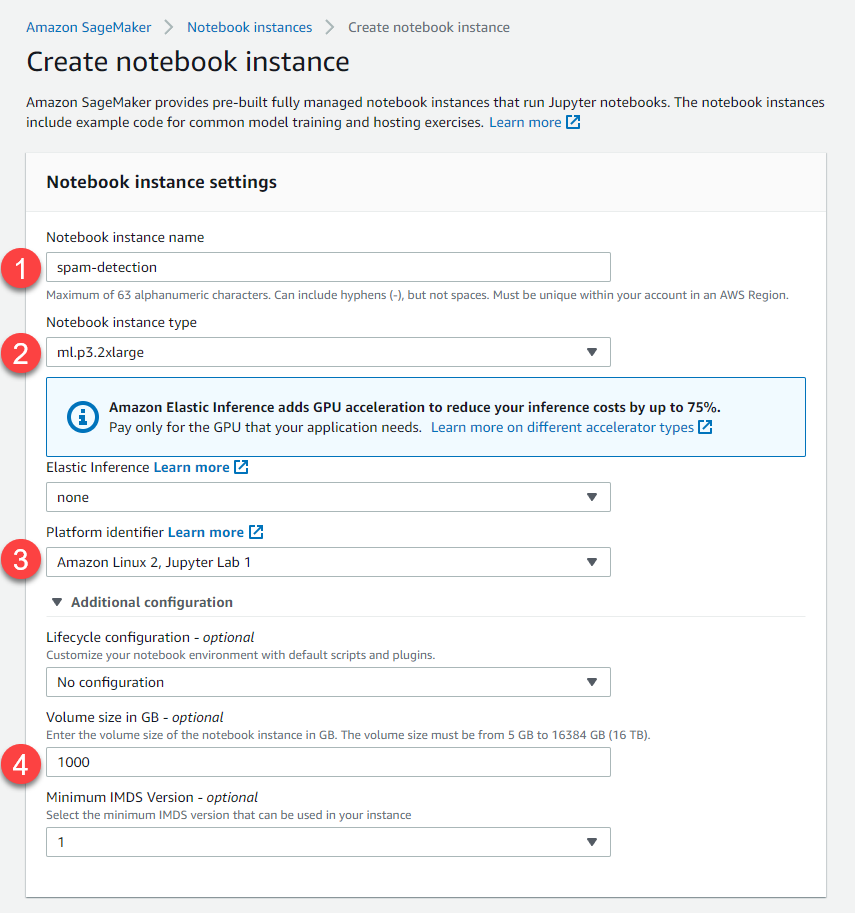
Notice:
- We increased the required disk space to a safe value of 1 TB.
- We do not need to use Elastic Inference — it is used to add a fractional GPU for accelerating inference at cheaper cost. In our case, we are already using the GPU instance of ml.p3.2xlarge which comes with a whole V100 GPU → we don’t need the elastic inference.
- We used the platform identifier of Amazon Linux 2, Jupyter Lab 1. Using a different value may cause version conflicts.
- The Jupyter Lab’s kernel to be used for the solution notebook is “conda_amazonei_pytorch_latest_p37”. Using a different kernel may cause version conflicts.
6.2.2 Step 1 — Installation of the model required libraries
!pip install torch -U
!pip install -qU pip awscli boto3 sagemaker transformers
!pip install nvidia-pyindex
!pip install tritonclient[http]
!pip3 install pickle5
!pip install datasets
!pip install nltk
Notice: We have upgraded the PyTorch library to the latest version. Without this step, we would not be able to save to model the ONNX file and deploy to NVIDIA Triton Inference Server. This upgrade causes minor library version conflicts — we do not depend on them:
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
torchvision 0.6.1 requires torch==1.5.1, but you have torch 1.11.0 which is incompatible.
torcheia 1.0.0 requires torch==1.5.1, but you have torch 1.11.0 which is incompatible.
6.2.3 Step 2 — Train the model
The code has been described in section 4.4.
Usually, we would add a step of evaluating the model on a larger test dataset. We do not share the dataset with the solution, so we omit.
6.2.4 Step 3 — Generate the ONNX file
!docker run --gpus=all --rm -it -v `pwd`/workspace-trt:/workspace nvcr.io/nvidia/pytorch:21.08-py3 /bin/bash generate_models.sh
The ONNX file is generated by the script in workspace-trt/generate_models which needs to be present in the solution.
#!/bin/bash
pip install transformers[onnx]
python -m transformers.onnx --model=./ --feature=sequence-classification ./
trtexec --onnx=model.onnx --saveEngine=model_bs16.plan --minShapes=input_ids:1x128,attention_mask:1x128 --optShapes=input_ids:1x128,attention_mask:1x128 --maxShapes=input_ids:1x128,attention_mask:1x128 --fp16 --verbose --workspace=14000 | tee conversion_bs16_dy.txt
trtexec is TensorRT’s command line tool for building a .plan optimized TensorRT model file from an onnx file. Its parameter –saveEngine (here model_bs16.plan) is used to specify the output engine’s name.
You can learn more by doing trtexec -–help inside the PyTorch NGC container.
Notice the parameters of the TensorRT’s trtexec command specifying the shape of the inputs and outputs:
- Batch size
- When we specified minShapes as 1×128, optShapes as 1×128 and maxShapes as 1×128, we were defined as a fixed batch size meaning the model can only accept batch sizes 1.
- However, TensorRT supports building optimized engines with dynamic shapes, so we can also, for example, specify minShapes as 1×128, optShapes as 16×128 and maxShapes as 128×128, which means the model can accept batch sizes between 1 and 128 and is optimized for batch size 16.
2. Sequence length
- It is represented by the second dimension in these shape profiles. In this example, it’s fixed at 128 (but you can change it to whatever sequence length is best for your model).
WARNING: Only the ONNX to TensorRT conversion step needs to happen
on the same GPU as the deployment GPU.
This means if you are deploying on an endpoint with g4dn.xlarge (which has the T4 GPU), then you need to make sure that ONNX to TensorRT conversion step (which we also refer to as building the TensorRT engine) needs to be on the T4 GPU (g4dn instance).
Everything else, from training the model to exporting the model to ONNX can happen on the training GPU, which can be a p3 instance, p4 instance or even g4dn instance.
The supported parameters of the trtexec command depend on its version:
- The PyTorch 21.08 NGC container has TensorRT 8.0.1.6, which cannot support dynamic shapes for DistilBERT model. This limitation was fixed in recent TensorRT version 8.2.4.2 available in PyTorch 22.04 NGC container.
- Using the most recent PyTorch NGC container in the current SageMaker Inference Endpoint version is, however, not possible. To run the TensorRT model successfully in Triton we also need to update to newer Triton version like 22.05, which has the TensorRT version 8.2.4.2 or later. Currently, the latest Triton container version that SageMaker supports is 21.08, which has the old TensorRT version 8.0.1.6, but we need TensorRT v8.2.4.2 or later, which is available in recent NGC Triton 22.5 container. Unfortunately, the SageMaker team doesn’t yet have a concrete release date for when they will officially add the new Triton 22.05 container in SageMaker.
6.2.5 Step 4 — Create SageMaker model package and upload it to SageMaker
!mkdir -p triton-serve-trt/bert/1/
!cp workspace-trt/model_bs16.plan triton-serve-trt/bert/1/model.plan
!tar -C triton-serve-trt/ -czf model.tar.gz bert
import boto3, json, sagemaker, time
from sagemaker import get_execution_role
sess = boto3.Session()
sm = sess.client("sagemaker")
sagemaker_session = sagemaker.Session(boto_session=sess)
role = get_execution_role()
client = boto3.client("sagemaker-runtime")
model_uri = sagemaker_session.upload_data(path="model.tar.gz", key_prefix="triton-serve-trt")
This script depends on the existence of the model config file triton-serve-trt/bert/config.pbtxt defining the model for NVIDIA Triton Inference Server, which needs to be present in the solution.
name: "bert"
platform: "tensorrt_plan"
max_batch_size: 128
input [
{
name: "input_ids"
data_type: TYPE_INT32
dims: [128]
},
{
name: "attention_mask"
data_type: TYPE_INT32
dims: [128]
}
]
output [
{
name: "logits"
data_type: TYPE_FP32
dims: [2]
}
]
instance_group {
count: 1
kind: KIND_GPU
}
6.2.6 Step 5 — Create SageMaker Inference endpoint
sm_model_name = "triton-nlp-bert-trt-" + time.strftime("%Y-%m-%d-%H-%M-%S", time.gmtime())
container = {
"Image": triton_image_uri,
"ModelDataUrl": model_uri,
"Environment": {"SAGEMAKER_TRITON_DEFAULT_MODEL_NAME": "bert"},
}
create_model_response = sm.create_model(
ModelName=sm_model_name, ExecutionRoleArn=role, PrimaryContainer=container
)
print("Model Arn: " + create_model_response["ModelArn"])
endpoint_config_name = "triton-nlp-bert-trt-" + time.strftime("%Y-%m-%d-%H-%M-%S", time.gmtime())
create_endpoint_config_response = sm.create_endpoint_config(
EndpointConfigName=endpoint_config_name,
ProductionVariants=[
{
"InstanceType": "ml.p3.2xlarge",
"InitialVariantWeight": 1,
"InitialInstanceCount": 1,
"ModelName": sm_model_name,
"VariantName": "AllTraffic",
}
],
)
print("Endpoint Config Arn: " + create_endpoint_config_response["EndpointConfigArn"])
endpoint_name = "triton-nlp-bert-trt-" + time.strftime("%Y-%m-%d-%H-%M-%S", time.gmtime())
create_endpoint_response = sm.create_endpoint(
EndpointName=endpoint_name, EndpointConfigName=endpoint_config_name
)
print("Endpoint Arn: " + create_endpoint_response["EndpointArn"])
The code finds the NVIDIA Triton Inference Server’s closest location in AWS ECR and deploys it to the AWS SageMaker Inference Endpoint. The deployment should take less than 10 mins.
Notice:
- In the endpoint configuration, we define the endpoint instance type — it must be identical to the instance used for creating the TensorRT model. Creating the TensorRT model (engine) from ONNX model i.e. ONNX to TensorRT conversion step, needs to happen on the same GPU as the target deployment GPU. So if you want to deploy TensorRT model on T4 GPU, which is in g4dn instance then you build the TensorRT engine on g4dn instance. Similarly, if you are deploying the model on V100 GPU which is found in p3 instance, then you need to build the TensorRT engine from onnx model on p3 instance. Currently, we can’t relax this hard requirement of TensorRT
- The deployment log is available from the AWS SageMaker Inference Endpoint (for us-east-1). If the creation takes more than 10 mins, review them. If it contains an error, the deployment fails after more than 30 mins and then you can delete the endpoint.
6.2.7 Step 6 — Test Triton SageMaker Inference Endpoint
import tritonclient.http as httpclient
from transformers import DistilBertTokenizer
import torch.nn.functional as F
import numpy as np
from retry import retry
import botocore
import concurrent
import time
enc = DistilBertTokenizer.from_pretrained("./workspace-trt/")
def tokenize_text(text):
encoded_text = enc(clean_text(text), padding="max_length", max_length=128, truncation=True)
return encoded_text["input_ids"], encoded_text["attention_mask"]
def get_sample_tokenized_text_binary(text):
inputs = []
outputs = []
input_names = ["input_ids", "attention_mask"]
output_names = ["logits"]
inputs.append(httpclient.InferInput(input_names[0], [1, 128], "INT32"))
inputs.append(httpclient.InferInput(input_names[1], [1, 128], "INT32"))
indexed_tokens, attention_mask = tokenize_text(text)
indexed_tokens = np.array(indexed_tokens, dtype=np.int32)
indexed_tokens = np.expand_dims(indexed_tokens, axis=0)
inputs[0].set_data_from_numpy(indexed_tokens, binary_data=True)
attention_mask = np.array(attention_mask, dtype=np.int32)
attention_mask = np.expand_dims(attention_mask, axis=0)
inputs[1].set_data_from_numpy(attention_mask, binary_data=True)
outputs.append(httpclient.InferRequestedOutput(output_names[0], binary_data=True))
outputs.append(httpclient.InferRequestedOutput(output_names[1], binary_data=True))
request_body, header_length = httpclient.InferenceServerClient.generate_request_body(inputs, outputs=outputs)
return request_body, header_length
@retry(botocore.exceptions.ClientError, tries=5, delay=1)
def get_prediction(text):
input_ids, attention_mask = tokenize_text(text)
payload = {
"inputs": [
{"name": "input_ids", "shape": [1, 128], "datatype": "INT32", "data": input_ids},
{"name": "attention_mask", "shape": [1, 128], "datatype": "INT32", "data": attention_mask},
]
}
response = client.invoke_endpoint(EndpointName=endpoint_name, ContentType="application/octet-stream", Body=json.dumps(payload))
result = json.loads(response["Body"].read().decode("utf8"))
predictions = F.softmax(torch.tensor(result['outputs'][0]['data']),dim=-1)
return torch.argmax(predictions, dim=-1).numpy()
test_texts = [
"Oh k...i'''m watching here:)",
"As a valued customer, I am pleased to advise you that following recent review of your Mob No. you are awarded with a £1500 Bonus Prize, call 09066364589",
"I HAVE A DATE ON SUNDAY WITH WILL!!",
"England v Macedonia - dont miss the goals/team news. Txt ur national team to 87077 eg ENGLAND to 87077 Try:WALES, SCOTLAND 4txt/ú1.20 POBOXox36504W45WQ 16+"
]
num_inferences = 1000
start = time.time()
with concurrent.futures.ThreadPoolExecutor() as exe:
fut_list = []
for _ in range (num_inferences):
for test_text in test_texts:
fut = exe.submit(get_prediction, test_text)
fut_list.append(fut)
for fut in fut_list:
rslt = fut.result()
elapsed_time = time.time() - start
print('num_inferences:{:>6}[texts], elapsed_time:{:6.2f}[sec], Throughput:{:8.2f}[texts/sec]'.format(num_inferences * len(test_texts), elapsed_time, num_inferences * len(test_texts)/ elapsed_time))
While Triton does support batch inference for all its supported backends, for this model we were restricted to the batch size of one because the current SageMaker Triton container’s available version of TensorRT doesn’t support dynamic shapes for the DistilBERT model.
This limitation of TensorRT has been fixed in its newer releases and should be available in the SageMaker Triton container soon.
6.2.8 Step 7 — Delete the SageMaker Inference Endpoint
After we finish the testing of the solution, we can delete the SageMaker inference endpoint, endpoint configuration and the model.
sm.delete_endpoint(EndpointName=endpoint_name)
sm.delete_endpoint_config(EndpointConfigName=endpoint_config_name)
sm.delete_model(ModelName=sm_model_name)
7. Performance Comparison of NVIDIA Triton-based and TorchScript-based AWS SageMaker Inference
For illustrative purposes, we have implemented identical code using AWS SageMaker Triton Inference endpoint and AWS SageMaker TorchScript Inference endpoint:
- We have repeated an inference for four test texts one thousand times using ThreadPoolExecutor
- While the results are approximate only, they should be robust enough: NVIDIA Triton Inference Server delivers 2.4 times higher throughput with 52.9 times lower model latency than TorchScript Inference Server.
Inference TypeThroughputModel LatencyNVIDIA Triton Inference Server339.35 texts/sec1.48 msTorchScript Inference Server 140.4 texts/sec78.3 ms
Compare the AWS CloudWatch’s ModelLatency for both inference servers:
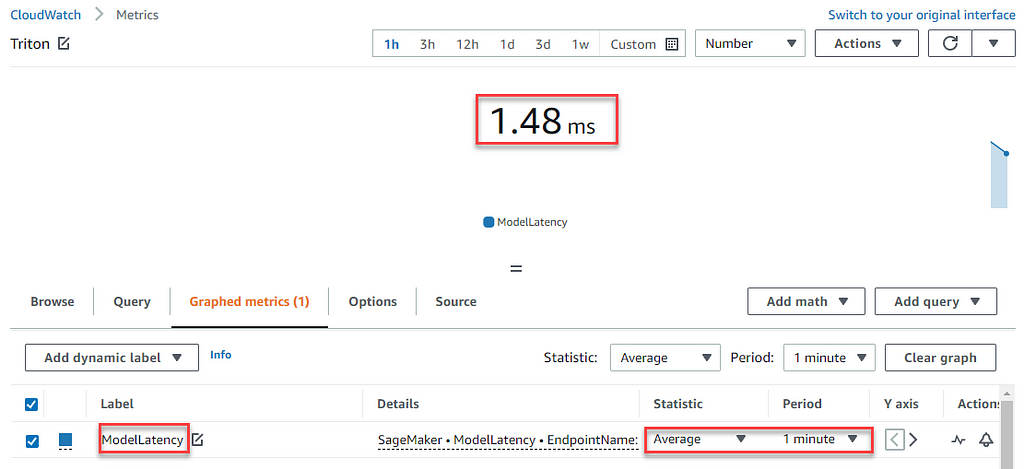
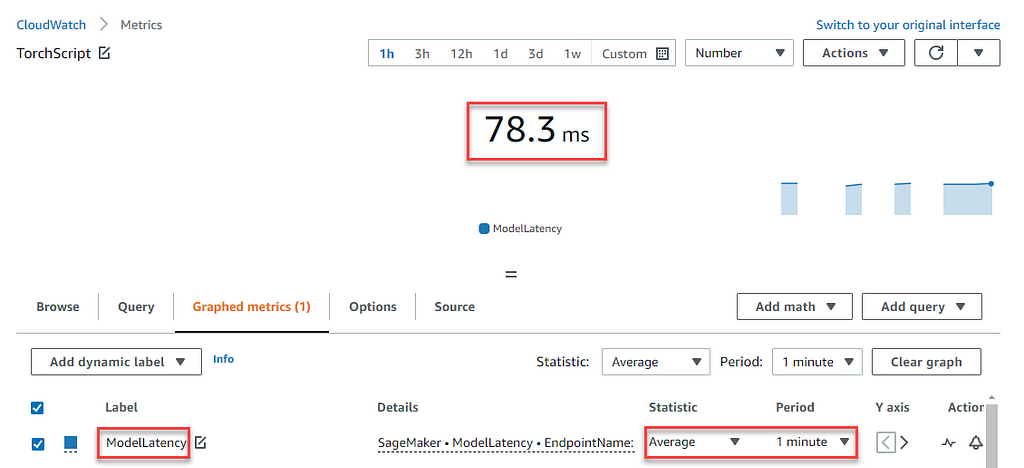
The main speed boost comes from the TensorTRT acceleration compared to the framework performance as well as the efficient kserve v2 protocol in Triton. It is possible to increase the performance even more by trying out these optimizations provided natively by Triton.
Modern Spam Detection with DistilBERT on NVIDIA Triton was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

