



How To Make STGNNsCapable of Forecasting Long-term Multivariate Time Series Data?
Last Updated on July 28, 2022 by Editorial Team
Author(s): Reza Yazdanfar
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Time Series Forecasting (TSF) data is vital in all industries, from Energy to Healthcare. Researchers have achieved some significant advances through the development of TFS models. By thoroughly considering patterns and their relationships for time series, analysis based on long-dependencies in the dataset is a must. This article is about designing a new model based on another model to perform on long-dependencies and produced segment-level representations. This model stands on STEP, an abbreviation of STGNN (Spatial-Temporal Graph Neural Networks) + Enhanced + Pre-training model.
STEP:
First of all, Do Not Be Confused:
- Spatial-temporal graph data = multivariate time series
Here, the data (traffic flow) used is recorded time series data on the road by sensors.
Did you see those two patterns in Figure 1 above??
Answer: there are two repeating patterns: 1. daily 2. weekly periodicities
First, STGNNs is the abbreviation of “Spatial-Temporal Graph Neural Networks” for those who don’t know/ know meager. (not difficult, it just needed to be googled; mentioned for those who don’t want to lose time or be distracted)
STGGNNs = Sequential Networks + Graph Neural Networks (GNNs)
We use GNNs for dealing with relationships between time series and Sequential models for instructing time series patterns. By the combination of these two terms, we can grasp outstanding results. By the way, there is no free lunch — as researchers said. It means powerful models demand complicated architectures; consequently (in most cases), the computational cost rises (linearly or quadratically) with the input length. Also, don’t forget the size of our time series, which is usually considerable. STGNNs, like other models, can predict small windows to make forecasting. This ability to rely on small windows makes the model unreliable.
Problem: 1. STGNNs can’t capture long-dependencies.
2. The dependency graph is missing.
Solution: STEP (STGNN is Enhanced by a scalable time-series Pre-training)
· a modified version of STGNNs
Illustration:
Two initiatives:
1. proposing TSFormer, a transformer-based block with an autoencoder (encoder-decoder) structure as an unsupervised model. This TSFormer able to capture long dependencies.
2. Proposing a graph architecture learner to learn dependency graphs.
After proposing these two, we just need to weld them for a joint model, that is the final solution. That’s it!! Sounds easy?! Let’s make them as simple as possible. 😉
Let’s see the proposed architecture:
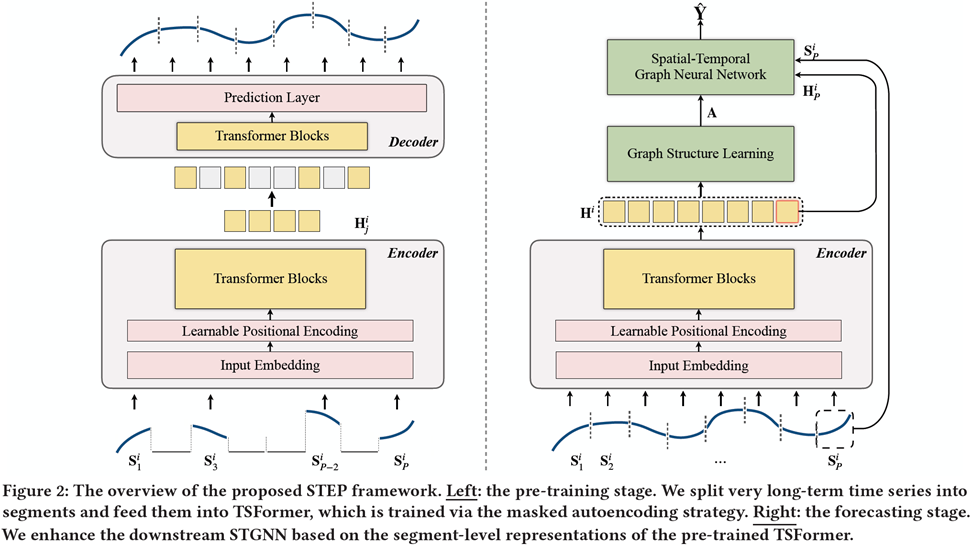
As you can see from figure 2, the model includes two phases:
phase 1) pre-training
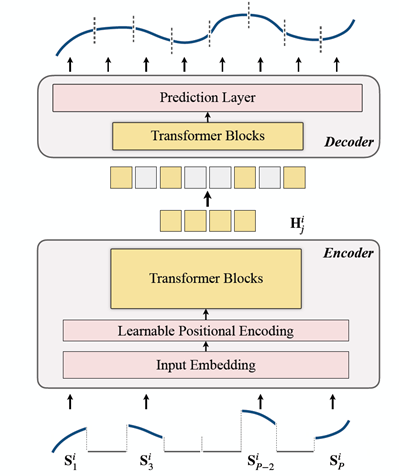
The scheme is a masked autoencoding model which is trained for time series data relying on Transformer blocks (TSFormer). This model is able to capture long-dependencies and turn out segment-level representation which includes some valuable information.
phase 2) forecasting
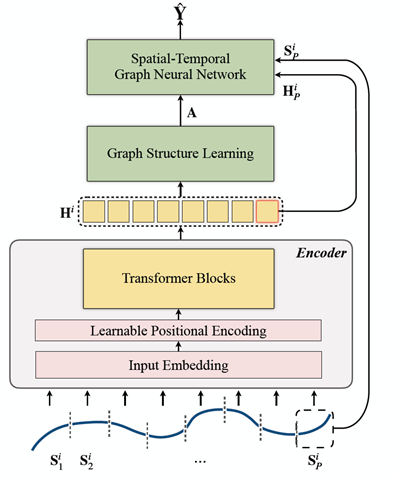
In this phase, the pre-trained model from the previous phase (which captured long-dependencies) is used to modify the downstream STGNN. Additionally, a discrete and sparse graph learner is designed just in case the pre-defined graph is missing.
That’s all I have done in general. Thus, let’s dive more into the details of these two phases:
1. The Pre-Training Phase
This attempt, I mean using a pre-trained model, is due to an increase of interest (and, of course, results) in applying them in NLP projects. Though pre-trained models are adopted widely in NLP (which is sequential data), there are some differences with time series. You can read its full description in my previous article: “How to Design a Pre-training Model (TSFormer) For Time Series?”
2. The Forecasting Phase
The input here is divided into P non-overlapping patches of length L. Our TSFormer produces indications for each input (Si) of the forecasting phase. One of the STGNNs’ features is that they take the newest. Therefore, based on those produced indications by TSFormer, we will modify STGNNs.
STEP From ZERO | The Process
- The encoder section in this phase is the same as it is in TSFormer; its description is not provided here to prevent making this article too long. If you want to know the details, you can read another article I have demonstrated completely(How to Design a Pre-training Model (TSFormer) For Time Series?).
The structure of learning in graphs
Problem) most graphs depend on a pre-defined graph that is unavailable or not good enough in most cases—also, mixing the way of learning (seeking the relationship between nodes (for ex. i and j) of the time series and STGNNs leads to great complexity.
Solution) pre-trained TSFormer
Interpretation) Proposing a discrete sparse graph. How? 1. graph regularization to fit supervised information. 2. a KNN graph to rein the sparsity. Its formulations are summarized below:

Downstream spatial-temporal graph neural network
problem) usual STGNNs’ input: last patch+dependency graph
solution) STEP (which adds the input patch’s representation to the input)
interpretation) As we discussed in my previous article, “How to Design a Pre-training Model (TSFormer) For Time Series?”, TSFormer captures long-dependencies; consequently, it makes H rich in aspects of information. Also, WaveNet is selected as our backend, which assists in capturing multivariate time series properly. But how?? It blends graph convolution with dilated convolution. Consequently, our forecasts are supported by WaveNet’s output latent, hidden representations. How?? By using MLP.
Q) If you look at the Forecasting phase architecture, you’d see two streams into Spatial-Temporal Graph NN Block. So, how can we manage that?
A) by using Eq7:
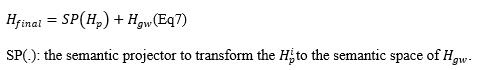
In the end, the forecasts are made by MLP:
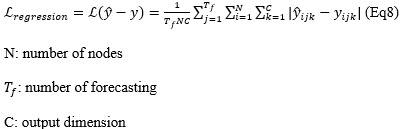
The output of the downstream STGNN:
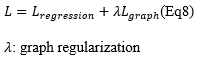
That’s the end of this STGNN modification. Hope you enjoyed. The rest is the results on the real-world dataset.
Results:
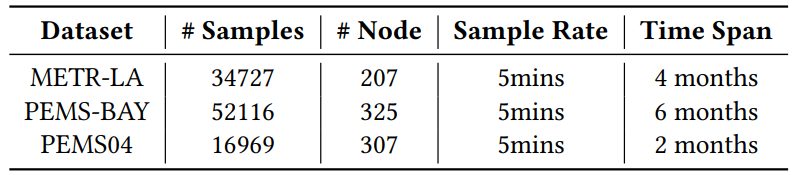
data:
The model is trained on three traffic speed datasets in three regions in the USA:
- METR-LA
- PEMS-BAY
- PEMS04
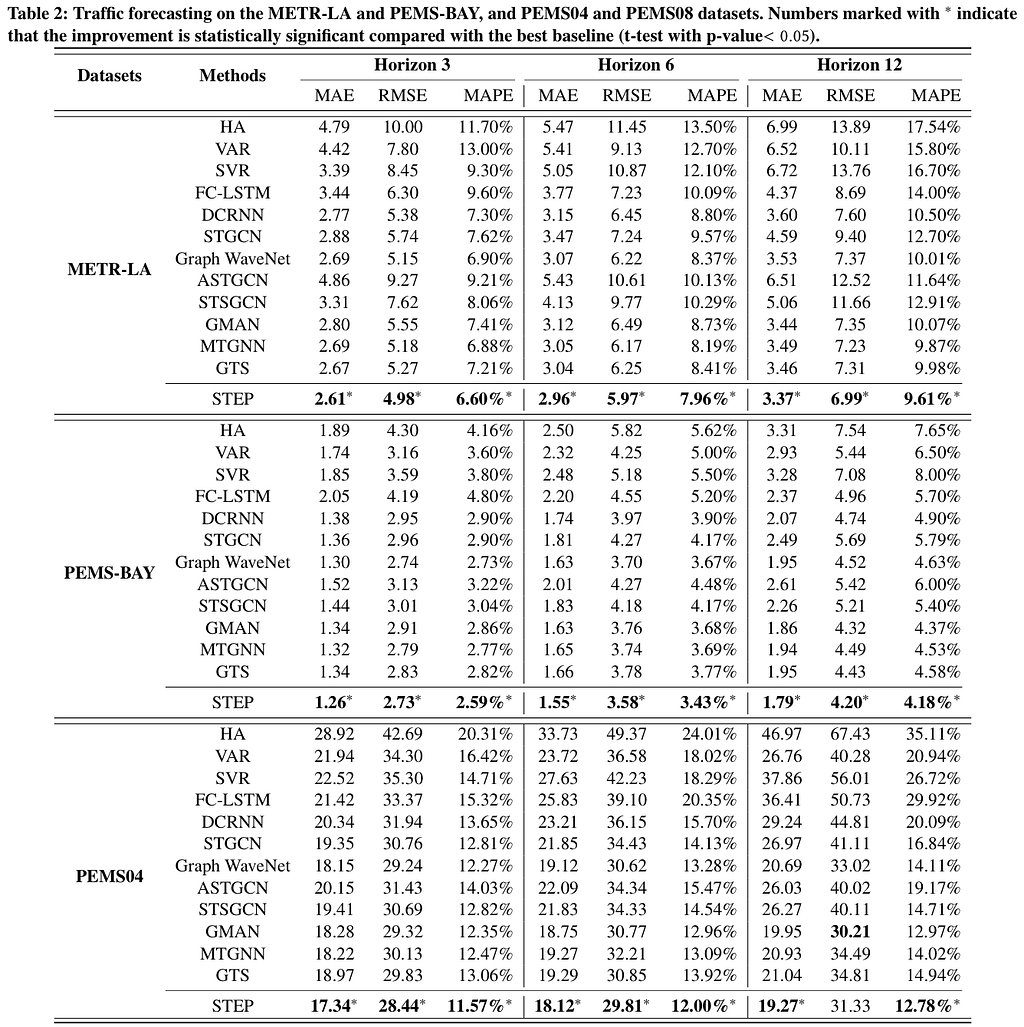
Metrics:
- MAE (Mean Absolute Error)
- RMSE (Root Mean Absolute Error)
- MAPE (Mean Absolute Percentage Error)
The End
The source is this.
You can contact me on Twitter here or LinkedIn here. Finally, if you have found this article interesting and useful, you can follow me on medium to reach more articles from me.
How To Make STGNNsCapable of Forecasting Long-term Multivariate Time Series Data? was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

