



What Is the Effect of Batch Size on Model Learning?
Last Updated on July 26, 2023 by Editorial Team
Author(s): Mohit Varikuti
Originally published on Towards AI.
And why does it matter
Batch Size is one of the most crucial hyperparameters in Machine Learning. It is the hyperparameter that specifies how many samples must be processed before the internal model parameters are updated. It might be one of the most important measures in ensuring that your models perform at their best. It should come as no surprise that a lot of research has been done on how different Batch Sizes influence different parts of your ML workflows. When it comes to batch sizes and supervised learning, this article will highlight some of the important studies. We’ll examine how batch size influences performance, training costs, and generalization to gain a full view of the process.
Training Performance/Loss
Batch Size, the most important measure for us, has an intriguing relationship with model loss. Let’s start with the simplest method and examine the performance of models where the batch size is the sole variable.
- Orange: size 64
- Blue: size 256
- Purple: size 1024
This clearly shows that increasing batch size reduces performance. But it’s not as simple as that. To compensate for the increased batch size, we need to alter the learning rate. We get the following result when we try this.
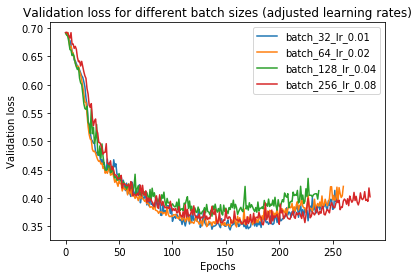
In this case, all of the learning agents appear to provide quite identical results. Indeed, it appears that increasing the batch size minimizes validation loss. Keep in mind, however, that these results are near enough that some variation might be related to sample noise. As a result, reading too much into this isn’t a smart idea.
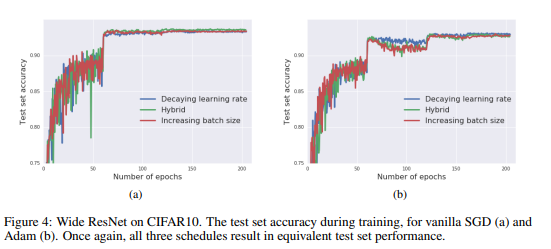
Conclusion: There is no major influence (as long as learning rate is adjusted accordingly).
Generalization
When given new, unknown data, a model’s capacity to adapt and perform is referred to as generalization. This is critical since it’s unlikely that your training data will contain every type of data distribution relevant to your application.
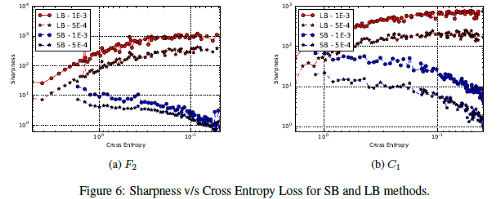
This is one of the areas where we notice significant variations. The difference in generalization between big and small-batch training approaches has been studied extensively. According to popular knowledge, increasing batch size reduces the learners’ capacity to generalize. Large Batch techniques, according to the authors of the study “On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima,” tend to result in models that become caught in local minima. Smaller batches are thought to be more likely to push out local minima and discover the Global Minima. If you want to read more about this paper read this article.
But it doesn’t end there. The study “Train longer, generalize better: bridging the generalization gap in large batch training of neural networks” aims to close the generalization gap between batch sizes. The authors offer a straightforward claim:
Following this premise, we conducted tests to demonstrate that the “generalization gap” is caused by a short number of updates rather than a large batch size, and that it can be totally avoided by changing the training regime.
The amount of times a model is updated is referred to as updates. This is reasonable. By definition, a model with double the batch size will traverse through the dataset with half the updates. For one simple reason, their paper is fascinating. We can save money while getting better performance if we can eliminate the generalization gap without increasing the number of updates.
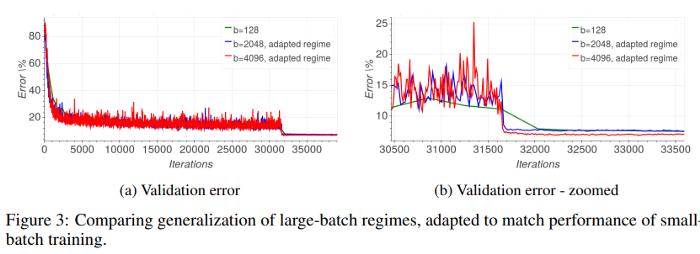
The authors employed an altered training schedule to get the big batch size learners to catch up to the smaller batch size learners. In the table below, they summarize their findings:
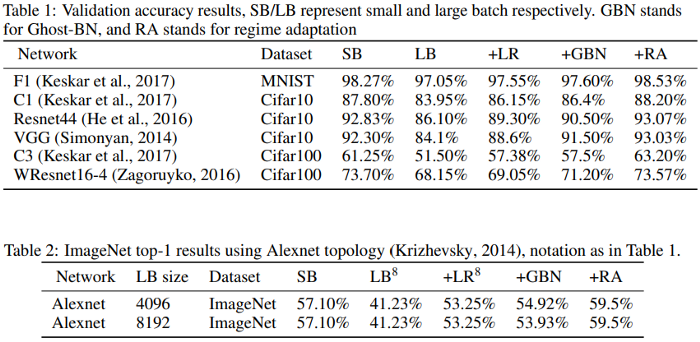
This is unquestionably thrilling. The ramifications are enormous if we can eliminate or greatly minimize the generalization gap in the approaches without significantly raising the expenses. Let me know in the comments/texts if you’d like a breakdown of this article. I’ll put this paper on my to-do list.
Conclusion: Weak Generalization in Larger Batches. However, this is something that can be remedied.
Costs
The Large Batch approach flips the script at this point. They tend to outperform when it comes to computational power since they require fewer updates. Using this as one of its optimization bases, the writers of “Don’t Decay LR…” were able to cut their training duration to 30 minutes.
But this isn’t the only factor that influences the outcome. And this is something I only recently discovered. I was shocked by a comment made in the article, “Scaling TensorFlow to 300 million predictions per second.” The authors claimed that by increasing batch size, they were able to cut their training expenditures in half. This makes perfect sense. Such considerations become more important when dealing with Big Data.
Fortunately, the cost aspect is pretty simple.
Conclusion: Larger batches result in fewer updates and data moving, resulting in cheaper computing costs.
Verdict
Batch sizes are critical in the model training process, as we can see. As a result, you’ll often encounter models trained with varying batch sizes. It’s difficult to predict the ideal batch size for your needs right away. There are, however, some trends that might help you save time. If cost is tight, LB could be the way to go. When you care about Generalization and need to get something up quickly, SB could come in handy.
Keep in mind that this article focuses solely on supervised learning. Things might alter if you use a different technique (like contrastive learning). Larger batches + more epochs appear to help Contrastive Learning a lot. Machine learning is a tough area with a lot to learn.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Related posts


Popular posts

 for 2021")



Updates

Recent Posts



