



The universe of “Data Science” roles demystified
Last Updated on August 7, 2022 by Editorial Team
Author(s): Shahrokh Barati
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
The Universe of “Data Science” Roles
Data Scientist vs. Data Analyst vs. Data Engineer vs. ML Engineer vs. MLOps Engineer vs. [insert your fancy role title here]…
Let me start this blog by clarifying that I do not consider myself a data scientist nor a technical expert, but I have gained a pragmatic perspective on the various roles in this space through my experiences in leading AI & data science projects and building up and managing teams of data scientists and analytics professionals.
I believe in the power of visual illustrations, so if you only have 1 minute to spare, let it be on the image above, which is a visual summary of this blog, depicting core and supporting roles across the data science lifecycle.
There are many different and sometimes contradicting views on the numerous roles in the data science space and their respective responsibilities. I don’t claim to have THE right answer, but I have tried to highlight the most common roles in simple terms to demystify some of the hype that surrounds the “loaded” titles.
There is naturally a lot of overlap between these roles, and I will not pretend they are MECE (mutually exclusive and collectively exhaustive), but I’ve tried to underline the key differentiating elements of each role to help with their positioning. Also, I believe as the industry matures, these roles will naturally become more standardized and commonly defined, especially considering some of them didn’t even exist as recently as 3–4 years ago.
Overview of “Core” Data Science roles
I’m only using the term “core” to highlight the roles that are most often referred to when talking about data science. “Core” should certainly not be read as “more important,” as each of these roles has its own place, without which the success of any data science project could be compromised.
The common technical skills that span most data science roles are data modeling, machine learning theory & statistics, software development, and data visualization. The main difference is in the extent to which each skill is important for one role versus another, as illustrated here:
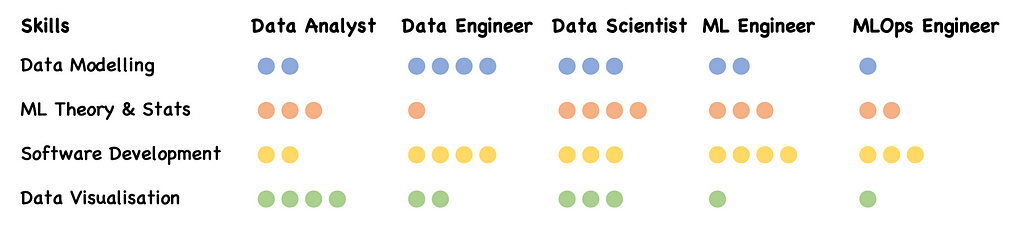
I’m purposefully keeping the descriptions below fairly brief and succinct to help differentiate between each role more easily; writing an exhaustive list of responsibilities and full job descriptions goes beyond the scope of this blog.
Data Analyst (Analytics expert)
- Key focus: Data Analysts, sometimes also referred to as data analytics experts, spend the majority of their time exploring, wrangling, and preparing data, as well as creating reports, dashboards and visualizations with the main aim of providing actionable insights.
- Key tech stack: Microsoft Excel (for data exploration), Alteryx (or other similar visual data prep tool), Tableau/Power BI/Qlikview (and other similar dashboarding/visualization tools), Basic Python (e.g., Pandas, NumPy, and the like)
Data Engineer
- Key focus: Data Engineers are software engineers at their core who have specialized in the development of data (including Big Data) pipelines. They are primarily responsible for sourcing, transforming, and integrating large datasets from various systems and getting them into the required structure/data model for data analysts and data scientists to consume.
- Key tech stack: Advanced Python (e.g., Pandas, NumPy), Advanced SQL, Big Data technologies/languages (e.g., Spark, PySpark, Scala, Hadoop, Hive), ETL platforms (e.g., Informatica, IBM InfoSphere)
Data Scientist
- Key focus: The primary focus of data scientists is typically within the “model development & evaluation” stage, where they are responsible for developing machine learning pipelines through an iterative and experimental process of feature engineering, model training, model evaluation, and performance optimization. In practice, however, many data scientists get involved across all stages of the data science lifecycle and are sometimes referred to as full-stack data scientists.
- Key tech stack: Advanced Python, including ML libraries (e.g., Pandas, NumPy, Tensorflow, Scikit-learn, PyTorch, Matplotlib, etc.), NLP libraries (e.g., NLTK, BERT, spaCy, etc.), working with SQL and NoSQL databases, Data Science Platforms (e.g., Dataiku, Azure ML, Databricks, Domino Data Lab, KNIME, RapidMiner, or simply Jupyter Notebook/JupyterLab)
MLOps Engineer
- Key focus: Machine Learning Operations (MLOps) engineers are effectively DevOps engineers who have specialized in the deployment and CI/CD pipelines of machine learning models. MLOps practices differ from traditional DevOps practices in a number of ways. For example, they typically require production data in the development environment, scalable cloud-based infrastructure often including GPU-powered servers for model training, model version control with a model registry service, model containerization and deployment onto a scalable orchestration infrastructure, and pipelines that enable constant monitoring of outputs in production, mechanisms to feed outputs to automatically re-train and re-deploy models dynamically, etc.)
- Key tech stack: Docker Containers or similar, Kubernetes Services or similar, GitLab or similar, CI/CD pipelines, Linux/Unix, Fiddler, MLflow, etc.
ML Engineer
- Key focus: Machine Learning (ML) Engineer is one of the most contentious roles with often contradicting views about its scope. Some view it as almost synonymous with a data scientist, and others view it as a full-stack developer; however, in practice, they sit somewhere in between. ML Engineers are software engineers by training who also have intimate knowledge of machine learning concepts and pipelines. Their responsibilities span across integrating model outputs into downstream systems, re-factoring ML pipelines into production-ready code (sometimes in lower-level programming languages like Java or C++), developing APIs that wrap models and enable their decoupling as a microservice, developing applications that integrate the model outputs, etc.
- Key tech stack: Advanced programming (Java, C++, Python), advanced microservices and API knowledge (e.g., Java Spring Boot, Flask, FastAPI, etc.), understanding of MLOps-related tech stack (e.g., Docker, Kubernetes, GitLab, etc.)
Overview of other supporting roles related to data science projects

There are several related roles that often interplay with the aforementioned core roles to deliver data science projects. They largely fall into 3 categories:
1. Several of these are standard engineering roles, such as Infrastructure Engineers, Solution Architects, and Product Managers, who are required for any IT delivery projects.
2. Others like Data Architects, Data Modelers, Data Owners, and Data Management experts are required for any data-related projects, irrespective of whether advanced AI/ML techniques are used or not.
3. The last category is those that are more specific to the world of data science, such as AI/ML Researchers, Model Validators, and Analytics Translators. Their responsibilities are sometimes contained within the aforementioned core roles but can also exist as standalone roles, especially in larger organizations. For example:
- AI/ML Researcher: Similar technical capabilities to a data scientist, but with the main focus on researching and experimenting with the latest and greatest developments in the data science space before they are used in an actual production environment
- Model Validator: Usually required in highly regulated environments such as financial services, where independent validation of models and their assumptions are required by someone other than the person who developed the model
- Analytics Translator: This role sits at the intersection of non-technical business SMEs (subject matter experts) and technical data scientists and acts as a “translator” to connect these two worlds. They have a sound understanding of data science concepts and related lingo but can also speak the business language and frame data science problems and benefits for non-technical crowds.
Final thoughts on the evolution of data science roles

Many of these roles have existed for a long time, but they were simply called by different titles before the so-called “data science era.” These roles are by no means obsolete and still very much exist in essence, but have mostly evolved/merged into one of the aforementioned data science roles.
For example, ETL developers (Extract-Transform-Load), have evolved into data engineers with a more modern tech stack such as PySpark, Scala, and Hive instead of ETL tools such as Informatica. Similarly, Business Intelligence (BI) engineers have evolved into data analytics experts who focus on drawing insights from data using the latest visualization and dashboarding tools.
I have no doubt that the current crop of data science roles will also continue to evolve, especially given the particularly fast-paced developments in this space. Some of the roles that I have referred to here may well become obsolete or merged into other newer roles or re-positioned with a completely different set of responsibilities to our current expectations.
As an example, there is an increasing trend in embracing Auto-ML technologies that are capable of automatically generating 1000s of features from data and training 100s of ML models with different hyper-parameters to find the optimal solution for a defined problem. As these technologies become more established and accepted, the nature of data science roles will also need to evolve. For instance, there will be more emphasis on framing problems and expert fine-tuning rather than spending a lot of effort in developing feature engineering pipelines and ML experiments from scratch.
This is already the case with the current ML frameworks/libraries such as Tensorflow, Pytorch, and Keras, which have enabled data scientists to spend almost no time developing the underlying ML algorithms from scratch (e.g., Neural Networks, XGBoost, etc.) and spend more time on applying those algorithms to solve their problems. Therefore, it’s natural to expect this trend to continue and for newer frameworks/libraries to automate an even larger portion of the data science lifecycle as we know it.
Looking forward to your comments on 1) whether my positioning of these roles aligns with your understanding/experience and 2) if there are any additional roles worth highlighting.
The universe of “Data Science” roles demystified was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


