



Learn with me: Linear Algebra for Data Science — Part 4: Singular Value Decomposition
Last Updated on July 26, 2023 by Editorial Team
Author(s): Matthew Macias
Originally published on Towards AI.
Welcome to the next part of the linear algebra series! We will be covering the Singular Value Decomposition and its immense role in Data Science. This article will be more technical than the previous, but that is only because we are reaching some more advanced topics after having laid our foundation. Don't worry, everything you have learned previously has prepared you for this moment!
Introduction to SVD
Just the name sounds scary and overwhelming, I know.
But I assure you that by the time this article is finished, you will have a good understanding of the SVD and its applications in Data Science. Let's start with an example matrix A:

What the SVD allows us to do, is represent matrix A as a product of three other matrices. It is Given by:

If we were to expand our representation of the above, it would look like this:

Ok, so that’s a lot to take in. But we will soon discover what all this means and develop an intuition for what it represents. Until then, let’s discuss some of the basics.
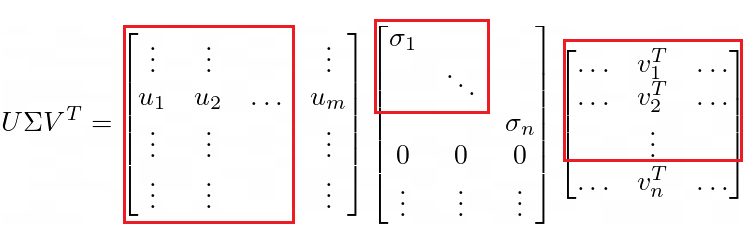
Our input matrix A is an M x N matrix. We can see that U takes on the shape of M x M , Σ (Sigma) takes on the shape of M x N and V is the shape N x N . That may seem a bit strange at first, but in the next section, we will discover how the shapes of these matrices came about. For now, just take note of them. Perhaps the most important thing to discuss is the types of matrices that U, Σ, and V are.
U and V are what is referred to as orthonormal matrices (for those that have read Part 1 of the series, you will know what orthogonal means). Orthonormal matrices are just matrices whose columns are orthogonal to each other, and each column vector has a length of one. The most interesting property that results from orthonormal matrices is the fact that their transpose is their inverse. That is to say:

Whilst this might not seem important now, the fact that these matrices behave in this way is what allows the SVD to be so useful. Finally, Σ is a diagonal matrix that contains what is known as the ‘singular values’ along the diagonal axis, all other entries are zero. Being diagonal, Σ is uninfluenced by the transpose operation, this will come in handy later also.
The final introductory piece is understanding that all of these matrices are ordered in terms of significance. That is to say that the first singular value in Σ is more important than the second, which is more important than the third etc. etc. This is also true for U and V, where the first vectors are of most importance because they correspond to the highest singular value.
So, what do U, Σ, and V actually represent?
What if I told you that our friends, the eigenvector and eigenvalue, were going to return to the party?

This is going to start off a bit abstract but just trust me! Let's start with a columnwise correlation matrix that can be created below:

Now, we have previously outlined that we can decompose any matrix into a product of three matrices U, Σ and V. So, to start let's replace all occurrences of our original matrices with their decomposed matrices. This will give us the below:

Given that the matrix U is orthonormal, then U^T U just cancels to the identity matrix, and so we are left with the below:

The above is actually the form for eigendecomposition. Where V contains the eigenvectors and Σ contains the eigenvalues. So what is the larger point that I am getting at here?
V actually captures the eigenvectors of this columnwise correlation matrix, and Σ captures the eigenvalues of that correlation matrix. This makes sense because V takes on the shape of the number of columns in both dimensions. So if the input matrix A has 10 columns, V will be a 10 by 10 matrix.
So we have covered V and Σ, what about U?
We can go through the exact same logic as above to uncover what the matrix U contains. Since V is the eigenvectors of the columnwise correlation matrix, U is the eigenvectors of the rowwise correlation matrix, denoted by:

Again, V is an orthonormal matrix, so it multiplied by its transpose cancels the identity matrix, and we are left with:

Where U contains the eigenvectors and Σ contains the eigenvalues (the same eigenvalues that we found previously, cool, right?). All of this was so you could build an intuition of what the U, Σ, and V matrices are in the SVD. To summarise it all into a single sentence, U contains the eigenvectors of the rowwise correlation matrix, Σ contains the eigenvalues, and V contains the eigenvectors of the columnwise correlation matrix.
Generally speaking, you would never compute the SVD by doing the eigendecomposition of the correlation matrices. The correlation matrices can get quite large, particularly U, and so it takes a lot of computation to derive them. A popular method for computing the SVD is known as QR factorization, which is what NumPy bases its implementation on.
Matrix Approximation
Another way that we can start to think about the SVD is that it is decomposing the original matrix into a sum of rank 1 matrices (there was a reason we took all that time to understand matrix rank, check out Part 2 for more info). Let's look at our original example:

If we were to multiply out the U, Σ, and V matrices on the right-hand side you would see that we get the following result:

The first column vector of U is multiplied by the first singular value in Σ along with the first-row vector in V. You can continue this for all combinations of U, Σ, and V.
Remember that the elements in U, Σ, and V are ordered by importance, such that the first element is of more importance than the second element etc., etc. What this allows us to do is only to keep the first r elements of each of the matrices to create a rank r best approximation of our original matrix. This results in U becoming m x r, Σ becoming r x r, and V becoming r x n.
By doing this, we end up with a much smaller matrix that can still describe the original matrix A with relative precision. You can start to see just how the SVD would be useful in dimensionality reduction techniques!
Pseudo Inversion
Perhaps the most useful application of the SVD for Data Science is its ability to invert nonsquare matrices. At this point, we are familiar with the below representation of linear systems of equations:

And we know that to be able to solve this system, where A is a known data matrix and b is a known label vector, we have to invert the matrix A. Up until now, we have just assumed that this is possible using the conventional method. However, if the matrix is non-square (which it likely always will be) then this will not work. The SVD introduces a methodology that allows us to invert these non-square matrices and solve the linear system.
You may be noticing a bit of a trend here, but again we will replace the A matrix with its SVD.

Now, there are a few things we need to do to be able to solve for x. They rely on our understanding of the composition of U, Σ, and V. We can isolate x by doing the following:

Since U and V are orthonormal, we can multiply by their transpose to eliminate them. For Σ we still need to multiply by its traditional inverse. You can see that everything except for x will cancel on the left-hand side. What we are left with is:

You’ll notice that we have inverted all of the components of the SVD. This is what is known as the pseudo inverse, and it powers all non-square matrix inversion! It is more formally denoted as:

So far, we have covered the top use cases for SVD in Data Science but let’s finally get to the good part…
How do we calculate the SVD in Python?
To start, let's just create a random matrix to experiment with:
import numpy as npA = np.random.rand(80,40)
This just created a matrix with 80 rows and 40 columns. To decompose this matrix using the SVD, we need to execute:
U, S, V = np.linalg.svd(A, full_matrices=True)
That’s it. Job done. Let's investigate a little further to make sure that the theory we discussed earlier holds true. We established that U was based on a rowwise correlation matrix and should therefore take on the shape of the number of rows x the number of rows. When we run:
>>> U.shape
(80,80)
You will see that it returns that the shape is (80,80) , which is exactly what we were expecting. Let's repeat for Σ and V.
>>> S.shape
(40,)>>> V.shape
(40,40)
So V checks out, but what's happening with Σ? Did I lie to you? Well no, NumPy returns the singular values as a vector. We can recreate Σ to be in the more traditional form but it is a bit more involved.
>>> sigma = np.zeros(A.shape, S.dtype)
>>> sigma.shape
(80,40)>>> np.fill_diagonal(sigma, S)
Essentially what's happening is that a matrix the same shape as the input matrix was created, and we added the singular values along the diagonal. Finally, let's reconstruct our original A matrix using U, Σ, and V.
>>> A_new = np.dot(U[:, :40] * S, V)
You’ll notice that we have to reduce the size of U to complete the reconstruction, but this can be avoided by setting full_matrices=False in the original SVD function.
Conclusion
That’s a wrap on another part of the linear algebra for the Data Science series. Hopefully, all of the pieces are starting to click together, and you can see just how powerful your new understanding of linear algebra will be in your Data Science journey. Next up, we will finally be covering PCA (I know you are all shaking with excitement). As always, I would recommend that you check out the other parts of this series (Part 1, Part 2, Part 3) if you haven’t already to get a solid understanding of linear algebra for Data Science.
If you have a question or just want to be in touch, feel free to contact me on Linkedin.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts

")





