
Member-only story
Data Engineering, Editorial
Diving Into Data Pipelines — Foundations of Data Engineering
An Introduction to Data Pipelines. How, What, When, and Why?
Author(s): Saniya Parveez, Roberto Iriondo
This article covers an extensive introduction with step-by-step explanations and code on data pipelines to introduce the foundations of data engineering. Data pipelines are used extensively in data science and machine learning and are crucial on machine learning workflows to integrate data from multiple streams to gain business intelligence for competitive analysis and advantage.
What is a Data Pipeline?
A data pipeline is a set of rules that stimulates and transforms data from multiple sources to a destination where new values can be obtained. In the most simplistic form, pipelines may extract only data from different sources such as a REST API, databases, feeds, live stream, and so on. These are loaded to a destination, such as a SQL table in a data warehouse. Data pipelines are the foundation of analytics, reporting, and machine learning capabilities.
Data pipelines are constructed with multiple steps such as data extraction, data preprocessing, data validation, data storage, and others. They can be developed by using multiple programming languages and tools.
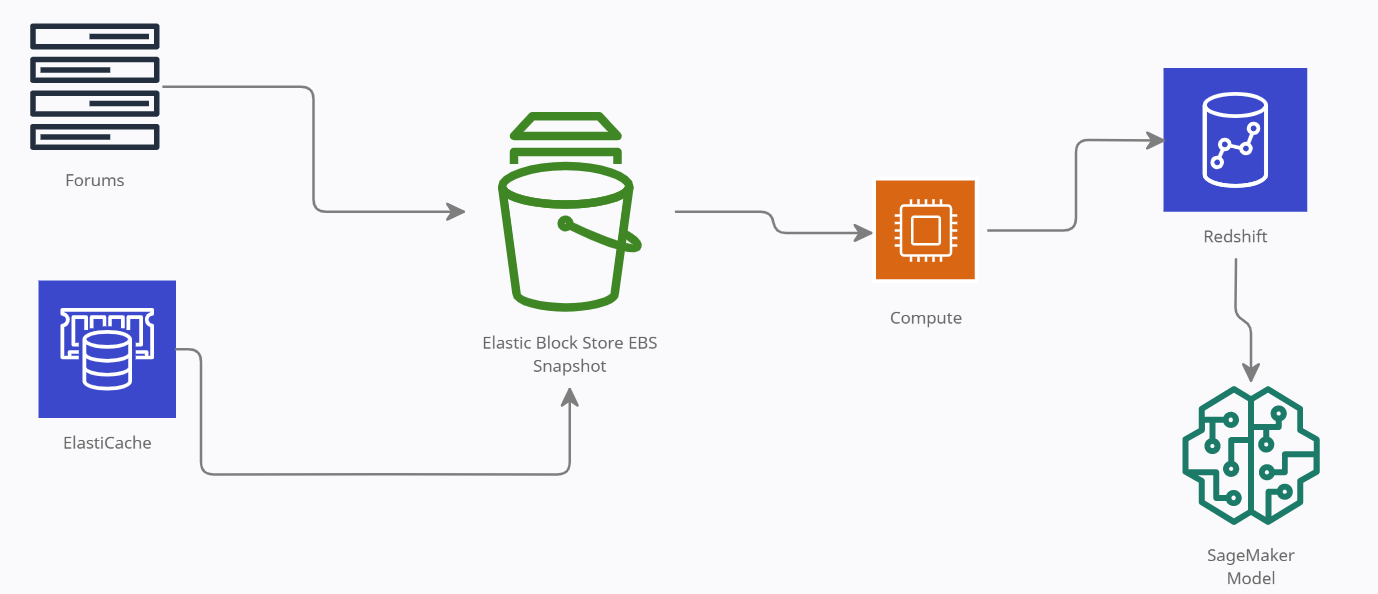
Well-built data pipelines do more than just extract data from sources and load them into manageable database tables or flat files for analysts to use. They perform several steps with raw data, including cleaning, structure, normalization, combining, aggregation, and so on. A data pipeline also requires other actives such as monitoring, maintenance, enhancement, and support of different infrastructures.

