



So retrieval is what we needed?
Last Updated on January 21, 2022 by Editorial Team
Author(s): Matan Weksler
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Artificial Intelligence
Last month DeepMind published their new NLP model called RETRO (Retrieval-Enhanced TRansfOrmer) which according to the paper, is a leap forward in the NLP world in multiple aspects. A notable one is that while this model achieved comparable results to SOTA architecture (e.g., GPT-3) it’s X25 times smaller with only 7.5B parameters compared to the 178B parameters of AI21 Jurassic-1.
This breaks the presumption that bigger models mean better accuracy.
The main advantage of smaller models is that they mean shorter training time thus less computing time and energy and overall a smaller carbon footprint. Just to put things in perspective, It would take 355 years to train GPT-3 on a single NVIDIA Tesla V100 GPU with an estimated cost of around $5M in compute time (to train GPT-3 OpenAI Uses 1,024x A100 GPUs still reaching an astronomical training time of around 34 days). Carbon-wise, it produced the equivalent of 85,000 kg of carbon dioxide during its training! That’s as much carbon dioxide as driving 120 cars for a whole year! Adding to that, due to their high training cost, re-training large language models regularly to incorporate new data, languages, norms, or updating the model in terms of fairness and bias is prohibitively expensive.
An additional advantage of smaller models is that while large language models can perfectly memorize parts of their training data when coupled with large training datasets gathered from the web or other sources, imposing privacy and safety implications, smaller models are less prone to such scenarios, as shown in Gehman et al. (2020). Bender et al. (2021)
So why have model sizes increased so much in recent years?
Up until recently when we spoke about NLU models we analyzed the language logic behind the text and responded accordingly. In recent years, we are trying (and hoping) to solve more knowledge-intensive tasks such as question answering, and to do so we need to integrate into the model more knowledge about the world. An example to question answering tasks might be — When was the movie Matrix released?
With linguistics utilization, we can only understand that we are searching for a date and not a name but if we are interested in getting the right answer the model needs to store this knowledge somewhere. Another reason for the growth is the increasing availability of computing power and the advances in GPU processors explicitly allow the rapid growth of models and the training cycles needed.
The Retrieval Philosophy
Instead of increasing the size of the model and training on more data, you equip models with the ability to directly access a large database as they perform predictions — a semi-parametric approach.
The best analogy to the retrieval method is the difference between Open-Book vs. Closed-Book exams.
While in a closed-book exam one needs to study and remember all the test material. In an open-book exam, you only need to understand the essence of the material, where to look for the right answer, and how to extract from the given material the correct one.
The concept of retrieval (in NLP models) is not new and has been suggested for NLU models in several papers including “Improving Neural Language Models with a Continuous Cache” by Grave et al. and Retrieval Augmented Generation from Meta-AI or the in the work of machine translation that retrieves translation pairs based on edit distance between source sentences and guide the translation output using the closest retrieved target sentences such as Zhang et al. (2018) and Gu et al. (2018).
Below I focus on the retrieval mechanism implemented by DeepMind which to my knowledge (and theirs), is the first work that shows the benefits of scaling the retrieval database to trillions of tokens for large parametric language models.
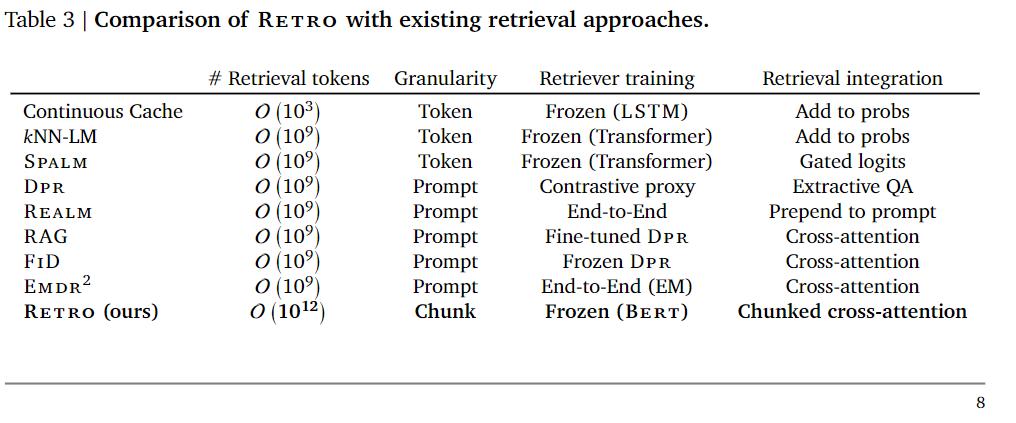
So what’s this retrieval method that makes the magic happen?
At a high level, retrieval models take the input and from a given database retrieve information similar to the input to incorporate it into the model to improve the predictions of the network.
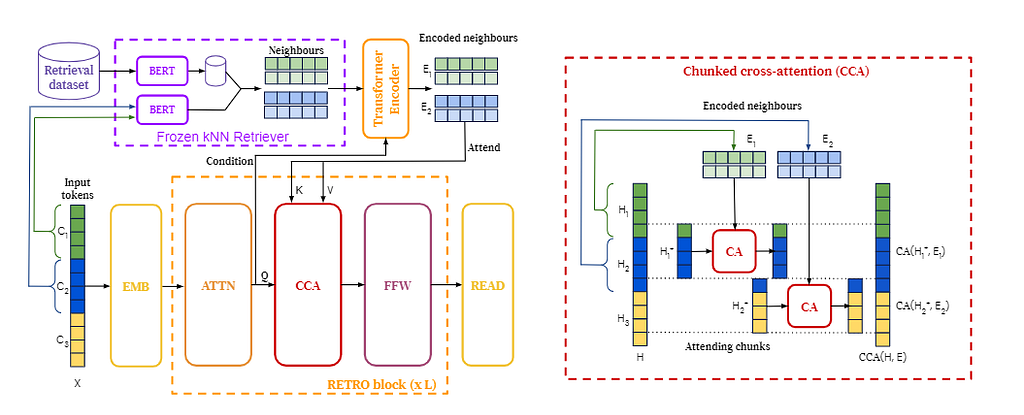
The novelty of the retrieval-enhanced architecture of DeepMind’s RETRO model is this it’s designed to be capable of retrieving data from a database with trillions of items and being able to incorporate it into the model using a chunked cross-attention scheme. That enables a linear correlation to computational time and storage requirements.
First thing, in order to implement a retrieval mechanism, we need to construct a key-value database, where values are raw chunks of text tokens and keys are frozen embeddings. The key in the RETRO model is generated by a frozen pre-trained BERT model to avoid having to periodically-compute embeddings over the entire database during training.
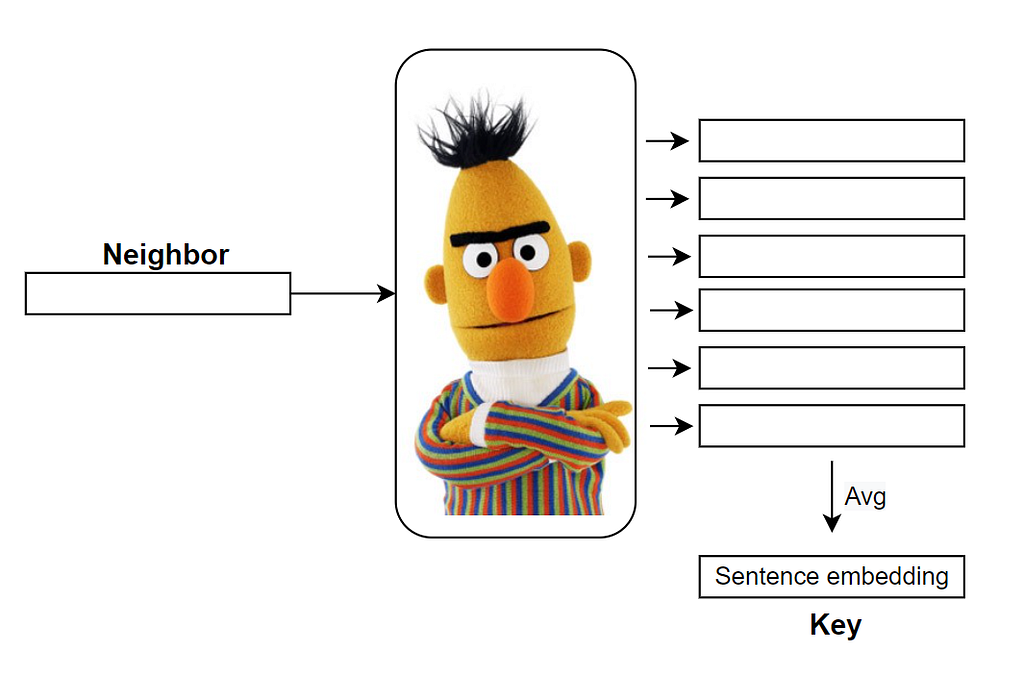
Depending on the task, the value can be a wide variety of things, for example in the question-answering task the value would be a tuple of neighbors (questions) — continuation (answer).
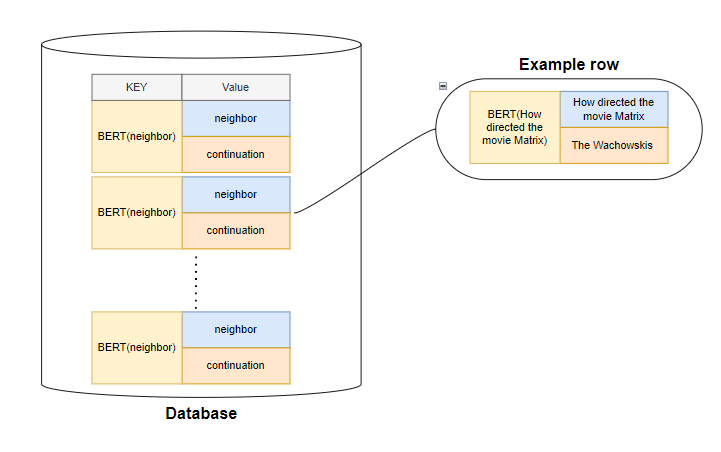
During the training phase, each training sequence is divided into chunks, which are then embedded using frozen BERTs. From the database, each chunk is retrieved his k-nearest neighbors to be augmented later in the RETRO block.
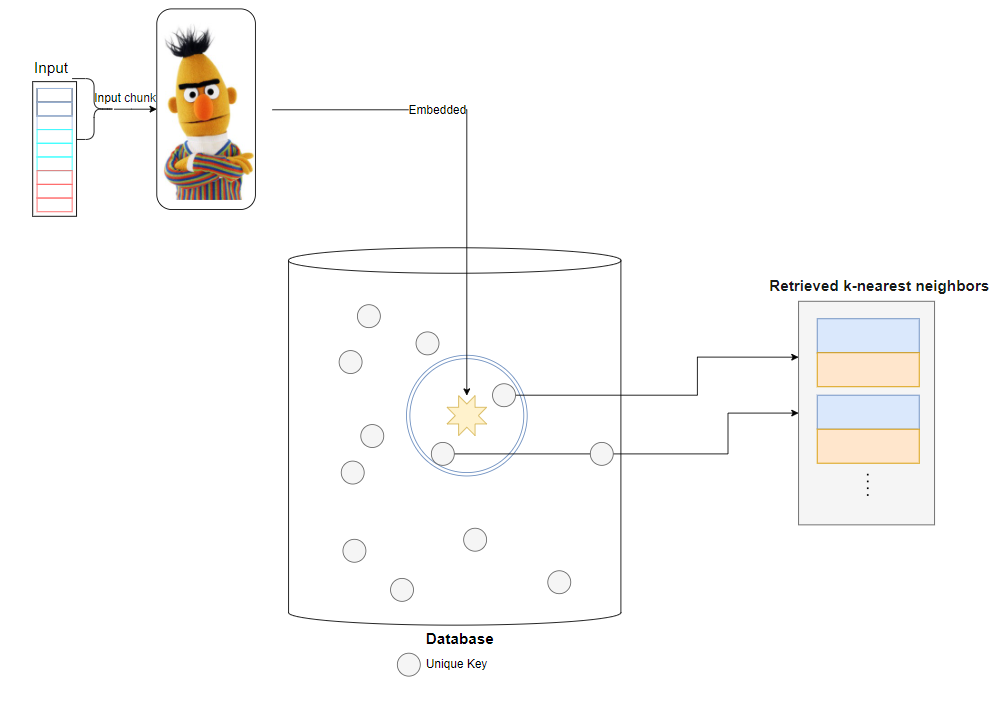
Then the encoder-decoder architecture integrates retrieval chunks into the model’s predictions.
The retrieved information is passed through a transformer encoding block to be able to be incorporated at the decoder part of the RETRO model. In practice, at the RETRO model, it’s being incorporated every third block starting from the 9th RETRO block (i.e, 9, 12, 15…32)
The advantages of retrieval
The obvious advantage of retrieval is that you can use a smaller model without losing accuracy. In practice, this has a beneficial impact on training (or re-training for model update) and inference time. More than that, keeping the retrieval models up-to-date, may be sufficient only to update the retrieval database, which is orders of magnitude cheaper than re-training a model from scratch.
Additionally, if portions of the training data are found to be biased or toxic outputs after training, retrieval allows for some correction, as the offending retrieval data can be retroactively filtered.
Summary
I intentionally did not want to go too deeply into the mechanics of the model. The model has already been analyzed in a number of articles, and of course, you can always read the full article by Deepmind (Link).
In my opinion, the concept of retrieval is revolutionary and worth the extra attention (pun intended). The paradigm shift is that instead of collecting and labeling huge amounts of data to teach our models, let’s see how we can teach a model to analyze information and just give the model the information we think might be relevant to him to extract this data.
Nowadays, access to information is endless, it is much more intuitive for us as humans to search the web and analyze the given information rather than remember everything, so why shouldn’t models do the same?
Just as “attention” allowed us to see the contexts within a sentence, methods like retrieval could help us link the model to the information relevant to it.
This could be the first step towards General-AI models, by embedding into the model the ability to extract task-specific information from a huge database to improve accuracy in a broad spectrum of tasks.
Furthermore, since we can directly visualize or modify the neighbors that the retrieval mechanism provides, we can gain more insights into the outputs of a model, thereby improving the explainability of the model.
Looking ahead, the next questions to ask could be; how can we improve our existing language models today? Is it possible to extend this retrieval method to other less intuitive places? What would be our database size limit? Could we improve our database query? and many more.
Days will tell
BTW, The Matrix was released on March 24, 1999 🙂
References
Borgeaud, S., Mensch, A., Hoffmann, J., Cai, T., Rutherford, E., Millican, K., … & Sifre, L. (2021). Improving language models by retrieving from trillions of tokens. arXiv preprint arXiv:2112.04426 – https://arxiv.org/pdf/2112.04426.pdf
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., … & Kiela, D. (2020). Retrieval-augmented generation for knowledge-intensive nlp tasks. arXiv preprint arXiv:2005.11401. https://arxiv.org/abs/2005.11401
Grave, E., Joulin, A., & Usunier, N. (2016). Improving neural language models with a continuous cache. arXiv preprint arXiv:1612.04426. –https://openreview.net/forum?id=B184E5qee
http://jalammar.github.io/illustrated-retrieval-transformer/
Gehman, S., Gururangan, S., Sap, M., Choi, Y., & Smith, N. A. (2020). Realtoxicityprompts: Evaluating neural toxic degeneration in language models. arXiv preprint arXiv:2009.11462 – https://aclanthology.org/2020.findings-emnlp.301/
Zhang, J., Utiyama, M., Sumita, E., Neubig, G., & Nakamura, S. (2018). Guiding neural machine translation with retrieved translation pieces. arXiv preprint arXiv:1804.02559 –https://arxiv.org/abs/1804.02559
Gu, J., Wang, Y., Cho, K., & Li, V. O. (2018, April). Search engine guided neural machine translation. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 32, №1)-https://www.aaai.org/GuideBook2018/17282-74380-GB.pdf
Bender, E. M., Gebru, T., McMillan-Major, A., & Shmitchell, S. (2021, March). On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?🦜. In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (pp. 610–623) – https://dl.acm.org/doi/10.1145/3442188.3445922
Lieber, O., Sharir, O., Lenz, B., & Shoham, Y. (2021). Jurassic-1: Technical details and evaluation. White Paper. AI21 Labs. — https://uploads-ssl.webflow.com/60fd4503684b466578c0d307/61138924626a6981ee09caf6_jurassic_tech_paper.pdf
https://www.spglobal.com/marketintelligence/en/news-insights/trending/HyvwuXMO9YgqHfj7J6tGlA2
https://www.theregister.com/2020/11/04/gpt3_carbon_footprint_estimate/
So retrieval is what we needed? was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")