



Integrating Feature Stores in ML architecture.
Last Updated on May 30, 2022 by Editorial Team
Author(s): Prithivee Ramalingam
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Introduction:
According to the World Economic Forum, at the beginning of 2020, the number of bytes in the digital world is 40 times the number of stars available in the observable Universe. That sure is massive, but the real question we have to ask is, can we make sense of this abundant data? The data has to be cleaned, transformed and engineered, and stored to make sense of it.
During this process, a lot of care must be provided to reduce redundancy. There must be organization-level centralized storage so that all teams have an idea of what features are already present. So they don’t waste time on Engineering Features which are already available. Feature store is getting high recognition since it is adopted by companies with abundant data to solve the redundancy and decentralization problems.
Why do we require a Feature Store?
Feature Engineering is the process of deriving a new feature after preprocessing a pile of raw data. For Engineering a single feature we collect related data, design the pipeline, analyze its business value, discuss the format, etc. These steps are exhaustive on their own, on top of that, this is an iterative process, we do this multiple times till we get satisfactory results. Based on whether it is batch or streaming data the Feature Engineering procedure and architecture differ. Proper planning and administration are required to store the Features along with necessary metadata.
A large organization will have multiple teams. Each team will be generating and consuming lots of data. Without a centralized location for accessing this data, there will be a high chance of redundancy. As there is no collaboration between teams they might work on deriving the same feature and store the data in different locations. This harms the productivity of the organization as a whole.
From the quality standpoint, the data needs of an organization should be satisfied by a single source of truth. If teams do not collaborate with each other and set stringent rules about data quality, each team would be having its own version of data and there would be no single source of truth for the organization as a whole. This would be extremely catastrophic for the organization. These are the main reasons for including a Feature Store in the ML architecture.
What is a Feature Store?
Feature Story is a centralized repository of features for the entire organization. Raw data will be curated, transformed and Feature engineered before appending to the Feature Store. Strict standards will be followed before adding values to the Feature store. Certain teams will work on generating the features and the other teams can consume the features. Since it is a centralized repository, features will be computed once and used many times. Since the features are created by subject matter experts the quality of data would be very high. Since Data versioning is enabled in Feature Stories, it automatically gets all its advantages of it.
There is no fixed structure for the Feature Store. It depends on the data needs and the infrastructure of the organization. Feature Stores should be distributed, highly available, and have low latency. There can be multiple projects in a Feature Store. Each project would have an entity ID and a list of features. The Entity ID will be used to uniquely identify the entity. An Entity could be a product ID, a review ID, or a movie ID. Data scientists can use the features from Feature Store for training and testing the models and certain features can be used in Model serving directly.

Components of a Feature Store:
A Feature Store usually consists of Registry, Monitoring, Serving, Storage, and Transformation.
Registry — The registry is also called the metadata store which contains information such as what features are present in each entity. This will be useful in cases where a developer from a different team needs information regarding the features which are available for a particular entity. Based on the query of Entity ID, the features are returned.
Monitoring — Monitoring is a new feature provided in the Feature store. The monitor can raise alerts based on failure or decay in data quality. Alerts can be configured to mail and this helps in the timely recovery and management of data.
Serving — This is the part of the Feature Store which serves features for training and inference purposes. For training purposes usually, SDKs are provided to interact with the Feature Store. For inference, Feature Stores offer a single entity based on request.
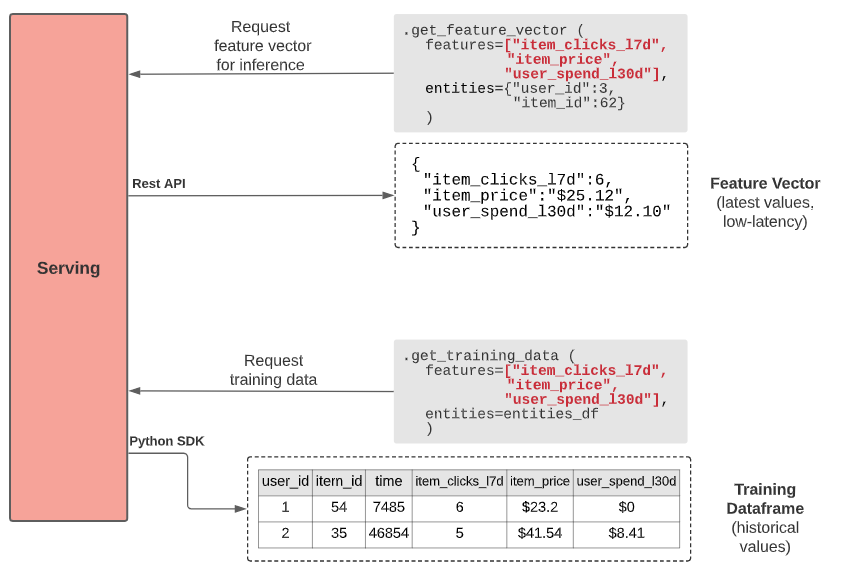
Storage — Features stores contain both online and offline storage. Offline storage contains all the historic data transformed into features. They are stored in data lakes and data warehouses. Snowflake and BigQuery can be used for offline storage. Online storage consists of data that are very recent. They contain mostly streaming data. Online storage layers have to have very little latency. Kafka and Redis can be used for online storage.
Transformation — Features for a Machine learning model are generated through a data pipeline. The feature store acts as an orchestrator for these pipelines. The features are recomputed based on a specified time interval and the transformation pipeline logic can be reused for this purpose.
Ingestion of Features:
The Feature Store architecture consists of Ingestion and Consumption mechanisms. Ingestion is the process of collecting raw data, feature engineering it to required features, and storing them in a storage solution. There are two types of ingestion: batch processing and streaming.
Batch Processing Ingestion — Batch processing is done when a bulk of data arrives at a scheduled time. The frequency can be something like once a day, twice an hour, once a week, etc. Since the data will be coming in bulk the data would be stored with the likes of Amazon S3, Database, HDFS, Data Warehouse, and Data Lakes. Spark can be used to handle bulk data with ease and store the Entity ID and Features in the Feature Store.
Streaming Ingestion — Streaming is real-time data. The data will be coming without any prior information. So Kafka will be an ideal candidate for Streaming ingestion. The data will be stored as log files or we can get them through API calls.
Consumption of Features:
Consumption is the process of consuming the stored features in an efficient manner. The types of consumption are model training and model serving.
Model Training — In this case we only select a subset of features of the total population but we would be selecting all the entities. We might consume data for experimentation or production in this method. For experimentation, we go with Google Colab or Jupyter notebook and for products, we use Spark or TensorFlow, or Pytorch.
Model Serving — In this case, we consume features from the Feature Store using an API call. The output would be sent to a web or mobile application. We would call only certain entities based on the entity ID received. The main requirement of this method is to support very low latency.
Advantages of Feature Store:
Improved Collaboration — Since Feature Stores have all the data concentrated in a repository. It improves collaboration between teams. The Features can be reused by multiple teams and this helps in avoiding redundancy to a great extent.
Guarantee of Data Quality — Since the ingestion is done by Subject matter experts, there is a guarantee that the data will be of High quality. Multiple subject matter experts coming together will help the organization establish a high-quality single source of truth.
Abstraction — Feature Stores bring in a layer of abstraction to the users. The preprocessing, transformation, and engineering are completely abstracted so the users can just concentrate on the job at hand.
Conclusion:
Recent advancements in the Feature Store architecture have made organizations integrate them into their MLOps pipeline. Feature Stores are currently being used in the production environment to handle datasets and data pipelines. Due to their centralized nature Feature Stores improve collaboration and reduce redundancy.
References:
- How much data is generated each day? | World Economic Forum (weforum.org)
- What is a Feature Store? | Tecton
- (7009) ML System Design: Feature Store — YouTube
- What are Feature Stores and Why Are They Critical for Scaling Data Science? | by Adi Hirschtein | Towards Data Science
Want to Connect?
Linked In — Prithivee Ramalingam | LinkedIn
Medium — Prithivee Ramalingam — Medium
Integrating Feature Stores in ML architecture. was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


