



GANs for Synthetic Data Generation
Last Updated on January 6, 2023 by Editorial Team
Last Updated on August 2, 2022 by Editorial Team
Author(s): Varatharajah Vaseekaran
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
A practical guide to generating synthetic data using open-sourced GAN implementations
The advancements in technology have paved the way for generating millions of gigabytes of real-world data in a single minute, which would be great for any organization or individual in utilizing the data. However, a large amount of time and resources would be consumed in cleaning, processing, and extracting vital information from the mounds of data.
The answer to handling such a problem is by generating synthetic data.
Contents
- What is Synthetic Data?
- A Brief Introduction to GANs
- Mode Collapse
- Wasserstein GAN (WGAN)
- Implementing a GAN for Synthetic Data Generation
- The Dataset
- Designing and Training the Synthesizer
- Final Words
- References
What is Synthetic Data?

The definition for synthetic data is quite straightforward: artificially generated data that mimics real-world data. Organizations and individuals can leverage the use of synthetic data to their needs and would be able to generate data, according to their specifications, as much as they require.
The use of synthetic data is highly beneficial in preserving privacy in information-sensitive domains: the medical data of the patients and transactional details of banking customers are a few examples where synthetic data can be used to mask the real data, which would enable sharing of sensitive data among organizations.
Few well-labeled data can be used to generate a large amount of synthetic data, which would fast-track the time and energy needed to process the massive real-world data.
There are many ways of generating synthetic data: SMOTE, ADASYN, Variational AutoEncoders, and Generative Adversarial Networks are a few techniques for synthetic data generation.
This article will focus on using Generative Adversarial Networks to generate synthetic data and a practical demonstration of generating synthetic data using open-sourced libraries.
A Brief Introduction to GANs

Many machine learning and deep learning architectures are prone to adversarial manipulation, that is, the models fail when data that is different to the one that is used to train is fed. To solve the adversarial problem, Generative Adversarial Networks (GANs) were introduced by Ian Goodfellow [2], and currently, GANs are very popular in generating synthetic data.
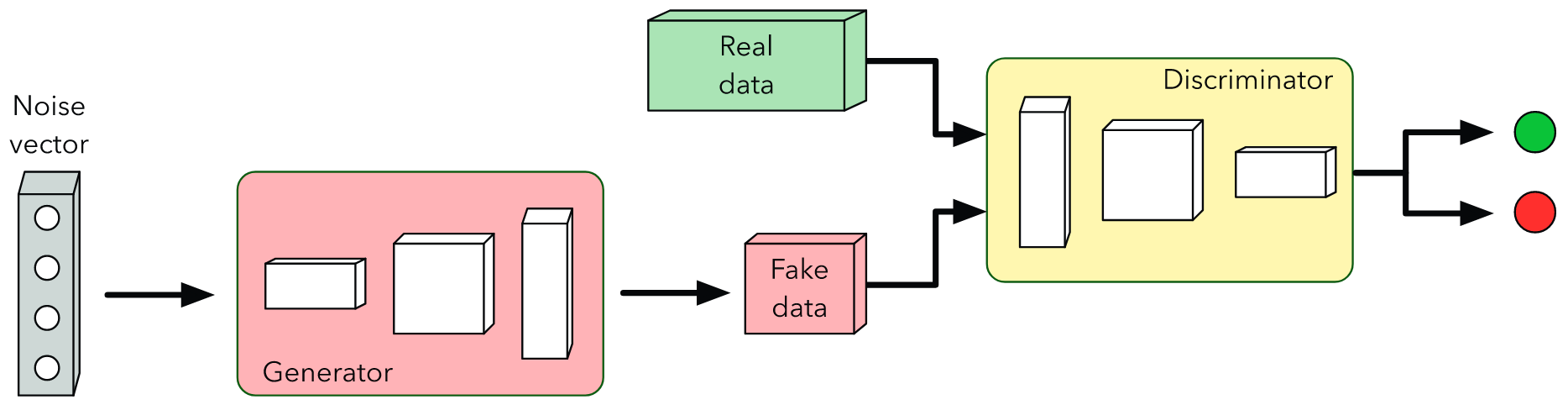
A typical GAN consists of two components: generator and discriminator, where both networks compete with each other.
The generator is the heart of the GAN, where it attempts to generate fake data that looks real by learning the features from the real data.
The discriminator evaluates the generated data with the real data and classifies whether the generated data looks real or not, and provides feedback to the generator to improve its data generation.
The goal of the generator is to generate data that can trick the discriminator.
Mode Collapse
Mode collapse is a common problem that GAN-based architectures face during adversarial training, where the generator repeatedly generates one specific type of data. This occurs when the generator identifies that it can fool the discriminator with one type of data, the generator would keep on generating that same data.
This problem can easily go undetected, as the metrics would indicate the model training is running smoothly, but the generated results would indicate otherwise.

Wasserstein GAN (WGAN)
The main problem in a standard GAN is the difference in complexity of the outputs from the generator and the discriminator.
A standard Vanilla GAN uses the Binary Cross Entropy (BCE)loss function [5] to evaluate whether the generated data looks real, where the output of the loss function is between 0 and 1. The task of the generator is to generate synthetic data that might have a lot of features and values, and the output from the discriminator is not sufficient for the generator to learn, and due to the lack of guidance, the generator can easily fall into mode collapse.
WGAN [6] alleviates the problem by replacing the discriminator with a critic, where the critic would evaluate the distribution of the real data with the distribution of the generated data and outputs a score of how real the generated data looks when compared to the real data. The Wasserstein loss function utilized in WGAN measures the difference between the real distribution and the generated distribution based on the Earth Mover’s Distance.
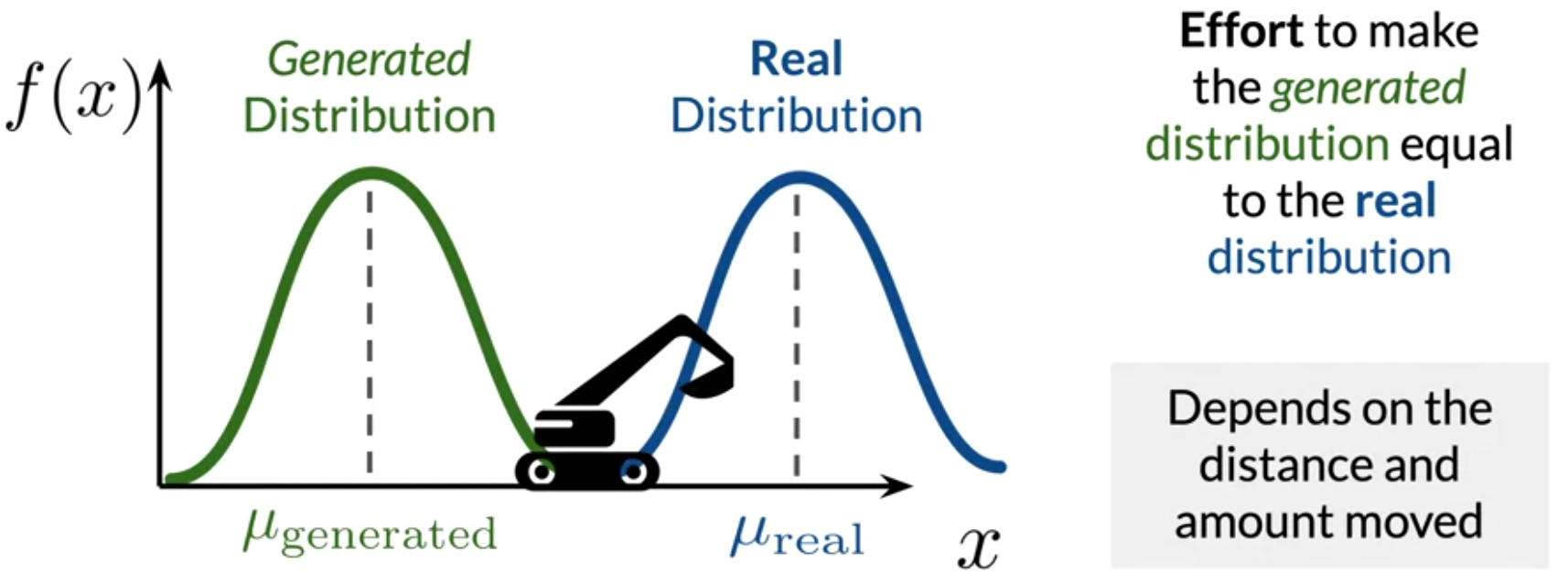
Earth Mover’s Distance measures the effort that is needed to make the distribution of the generated data look similar to the real data’s distribution. Therefore, there is no limitation on the value that is output. That is, if both distributions are far apart, the Earth Mover’s Distance will give a real positive value, whereas the BCE loss would output gradient values that are closer to zero. Therefore, the Wasserstein loss function enables solving the vanishing gradient problem during training.
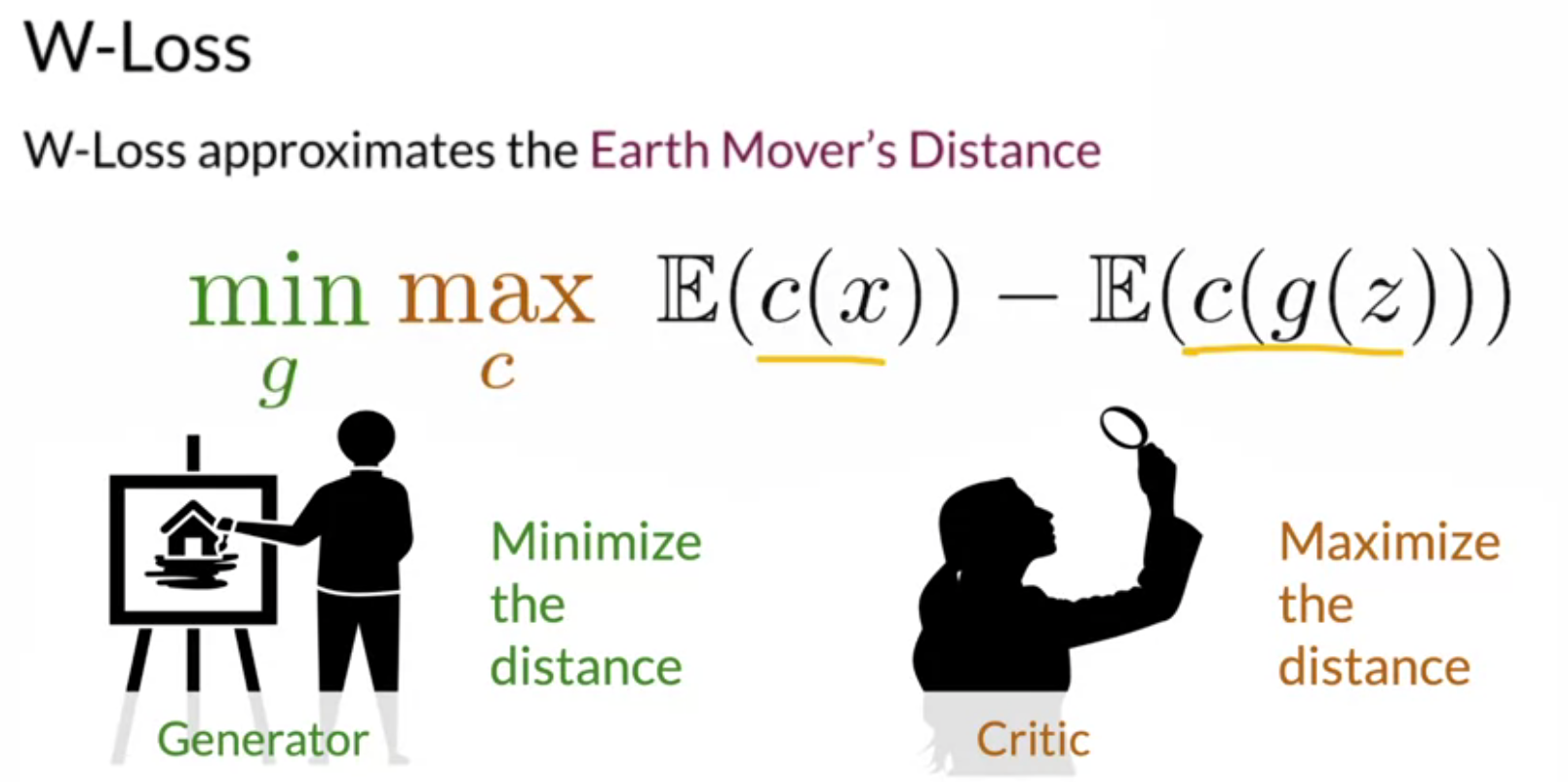
The above picture denotes the equation for the Wasserstein loss, which is relatively simple compared to the BCE loss. The initial part of the equation is the expected value of the prediction that the critic provides on the real data. The second part of the equation is the expected value of the prediction that the critic provides on the generated data. The goal of the critic is to maximize the distance between the real and generated data, and the goal of the generator is to minimize that difference.
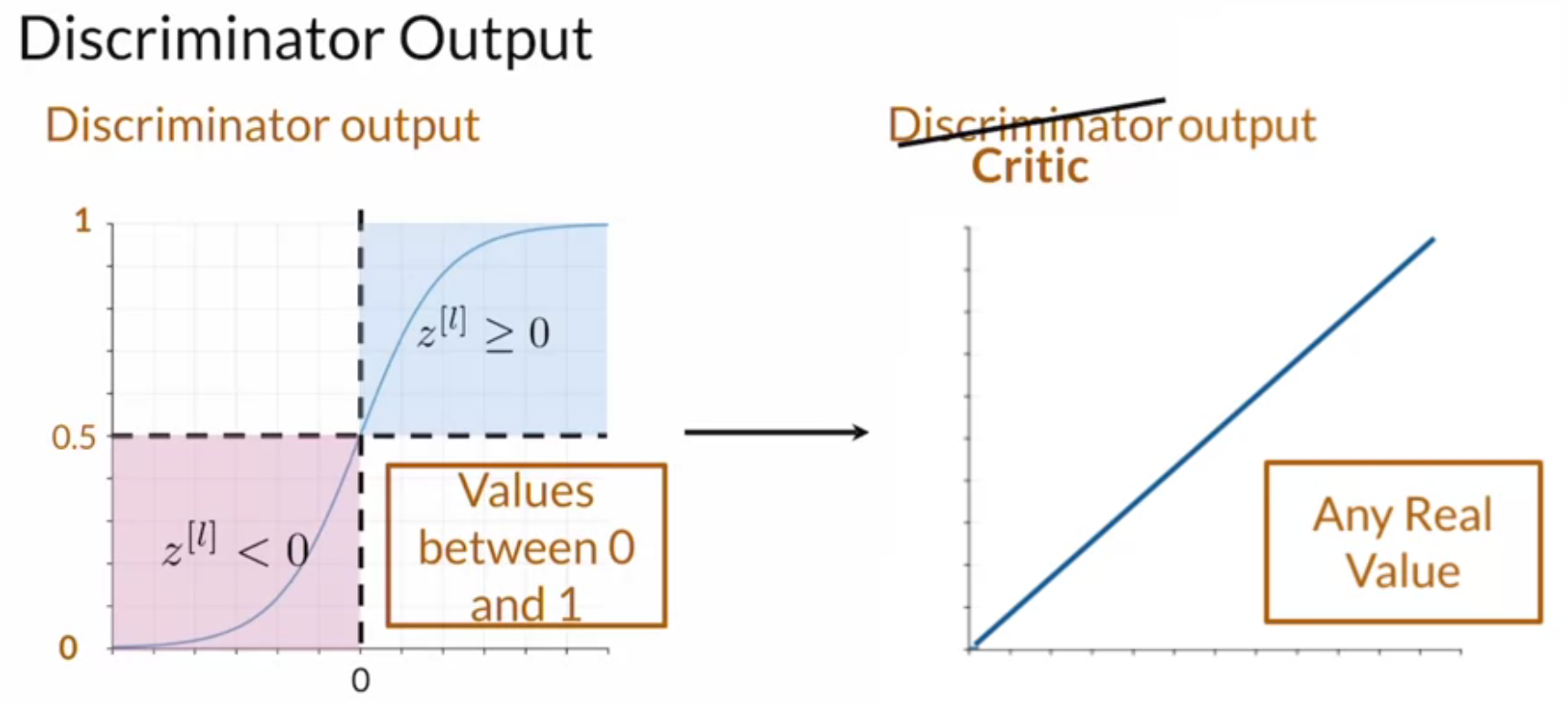
WGANs are prone to exploding gradient problems, as the Wasserstein loss outputs any value that is positive and real; therefore, the value of the gradients can uncontrollably increase when the distribution of the generated data differs from the real data’s distribution. This is solved by introducing a regularisation term, gradient penalty [7], which makes sure the gradients are contained, and this ensures better optimization of the WGAN model.
To learn in-depth about GANs, the Coursera specialization on GANs, by deeplearning.ai and Sharon Zhou, is highly recommended.
Implementing a GAN for Synthetic Data Generation
The ydata-synthetic library helps immensely in building GANs to generate synthetic data for tabular datasets, which otherwise would have been challenging and tedious.
There are a plethora of different types of GANs that can be used to generate synthetic data: the standard Vanilla GAN and Conditional GAN, and the advanced WGAN, WGAN with gradient penalty, Deep Regret Analytic GAN, CramerGAN, and Conditional WGAN, and a GAN option available for time series as well (TimeGAN).
The models can be used out-of-the-box with little modifications and can be used on almost any tabular dataset.
The library can be installed in the python environment with just one simple command:
pip install ydata-synthetic
The Dataset
The Diabetes Health Indicators dataset is chosen, which is CC0 licensed. The dataset has sensitive data, which are medical records of patients, and there is a need to obtain more data regarding the patients diagnosed with diabetes; therefore, the use of synthetic data would be highly beneficial. The dataset consists of 21 features, and the target feature is whether the patient is diagnosed with diabetes.
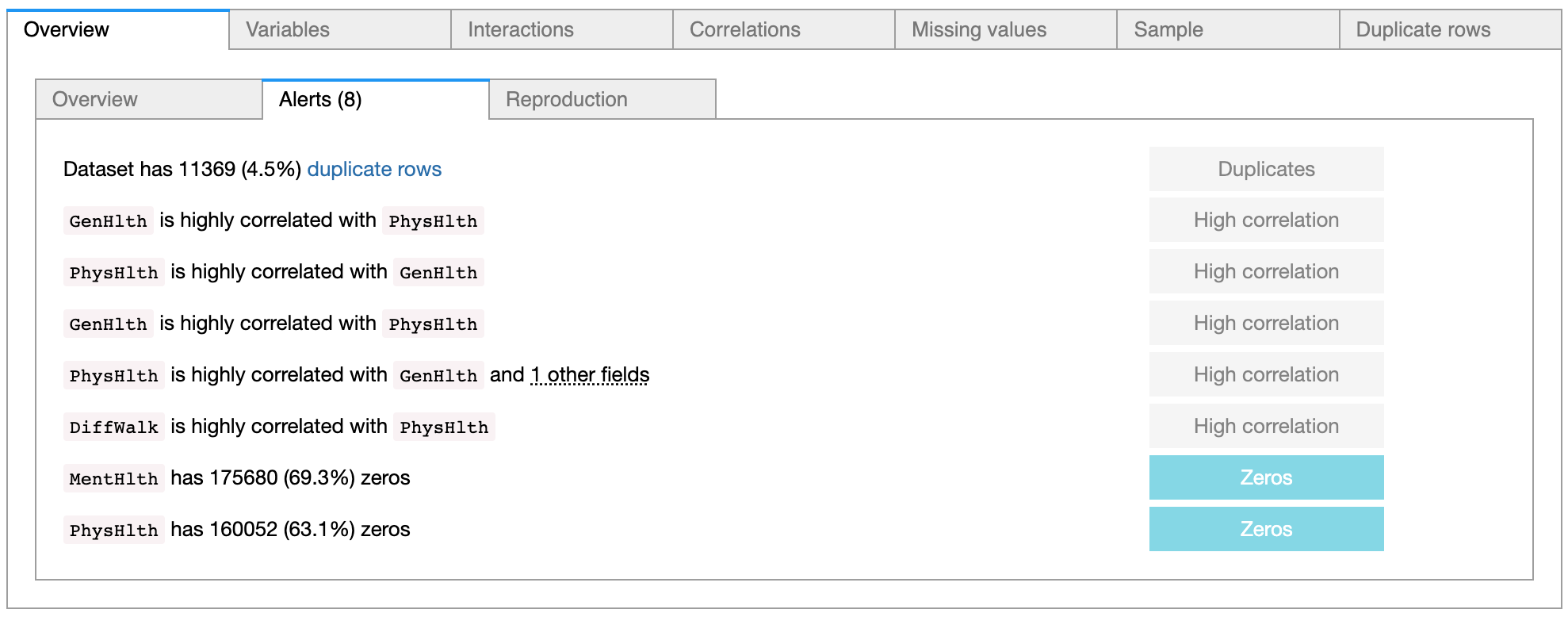
Another open-sourced tool, pandas-profiling, is useful for exploratory data analysis, visualizing features and relationships with just two lines of code, and that tool is used to conduct the exploratory data analysis on the Diabetes Health Indicators dataset. This generates a detailed report on all the variables present in the dataset, alerts for any abnormalities present in the data, displays the relationship (or correlation) between variables, and shows the missing values in each column and the duplicates present in the data.

There are more than 218,000 examples of non-diabetes patients and more than 35,000 patients diagnosed with diabetes.

All the variables are of float type, as the dataset has undergone pre-processing. With the help of the pandas-profiling library, it was discovered that there are 3 numerical variables (BMI, MentHlth, and PhysHlth), and the other variables are categorical. The pandas-profiling tool highlighted that about 4% of the dataset comprises duplicates.

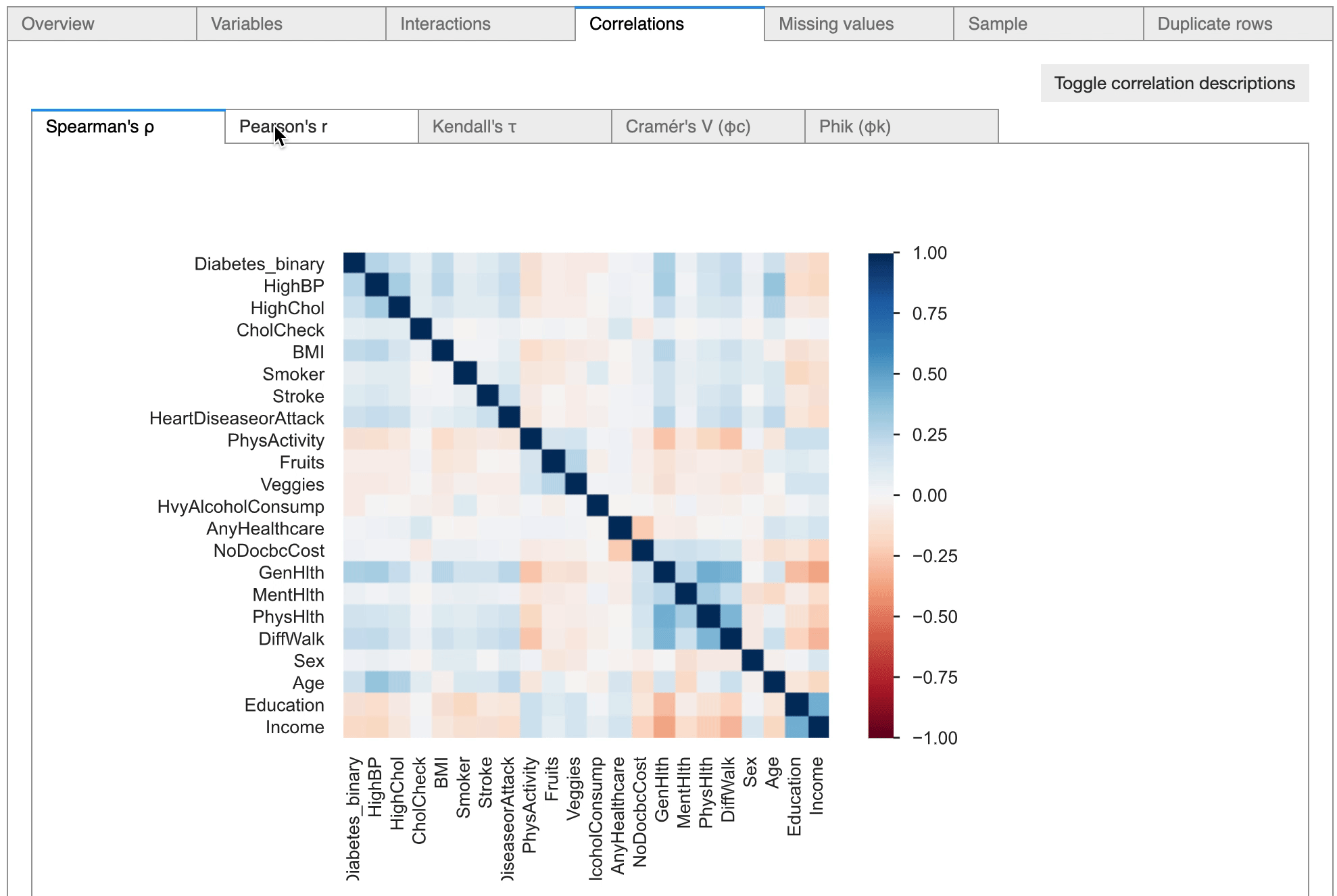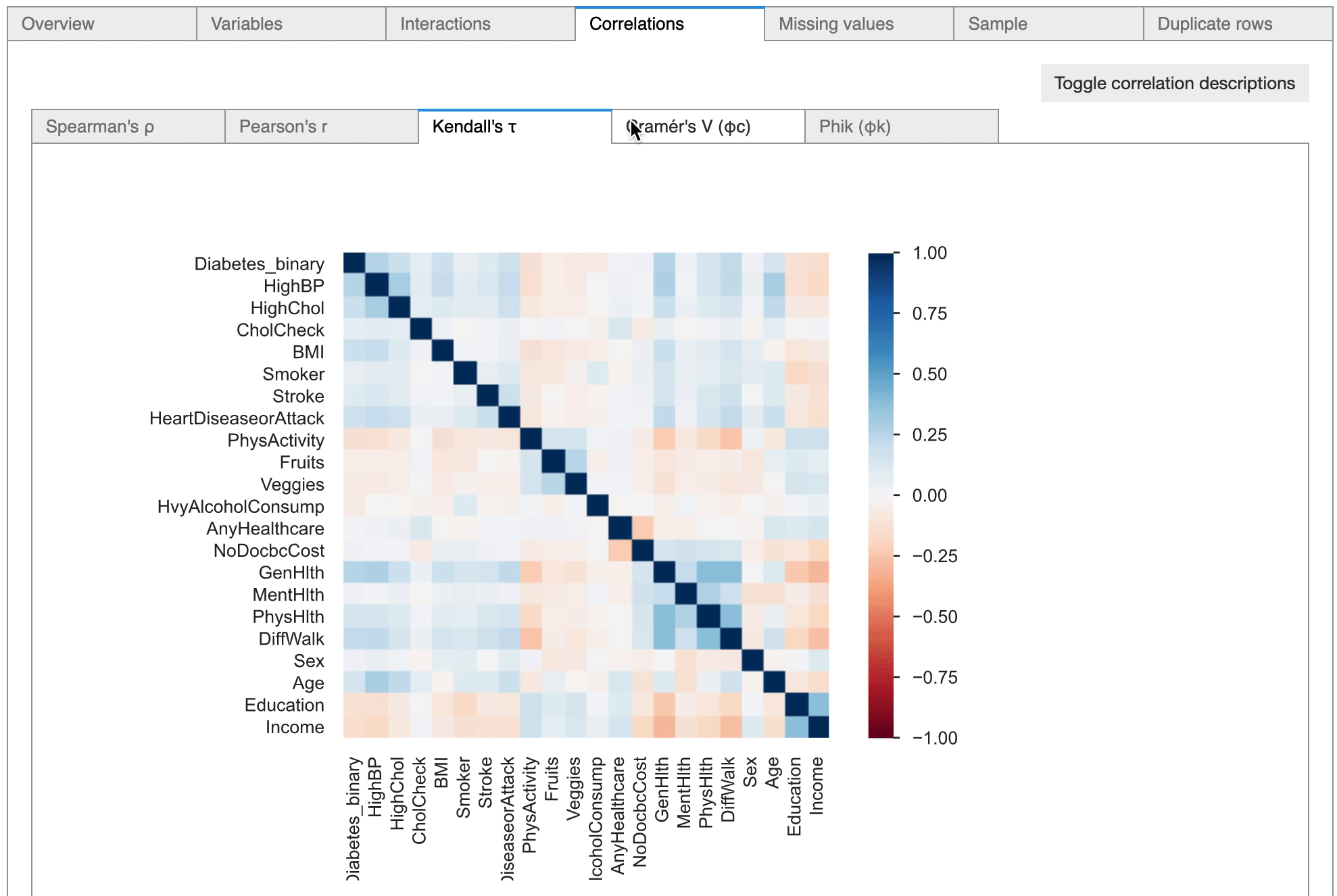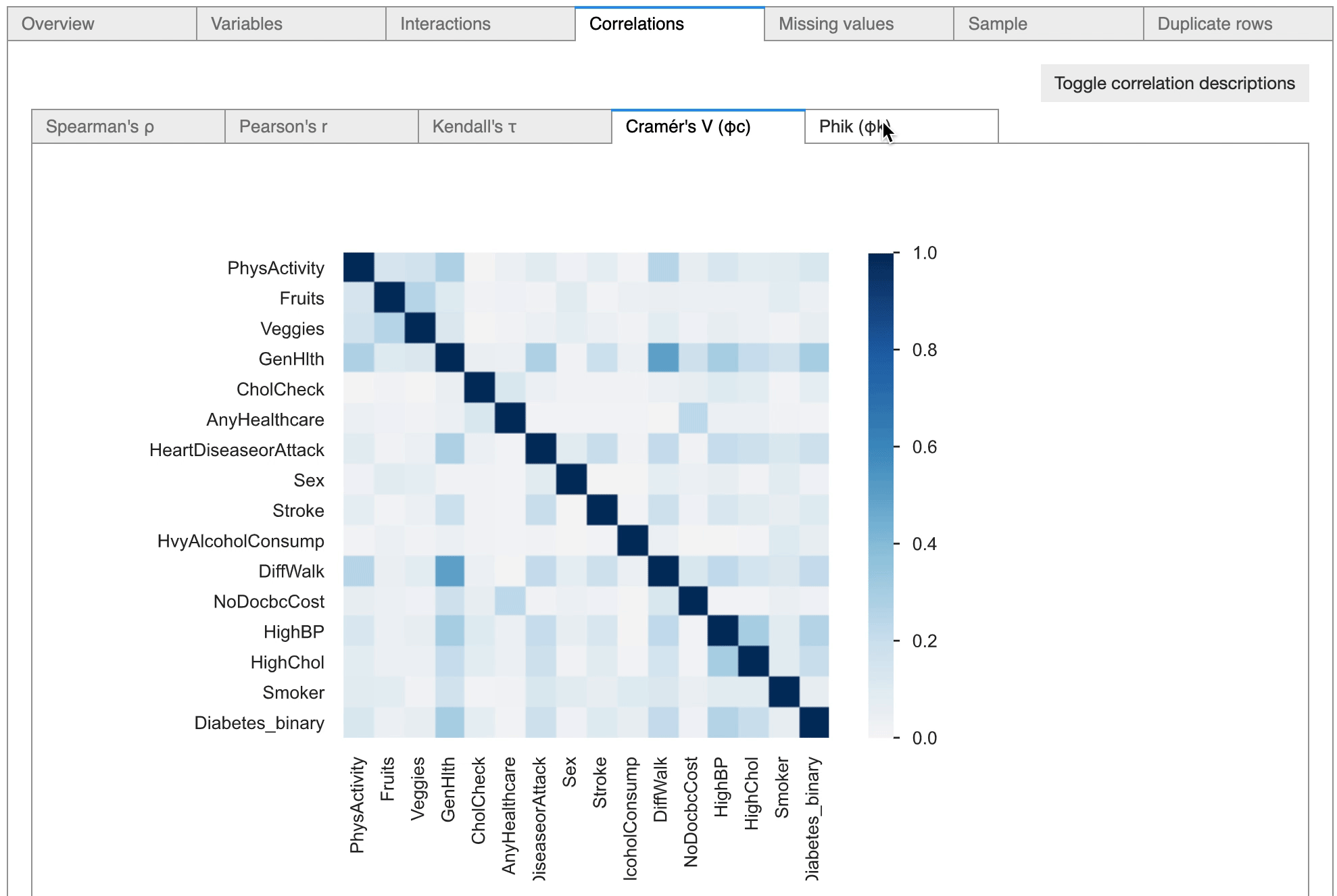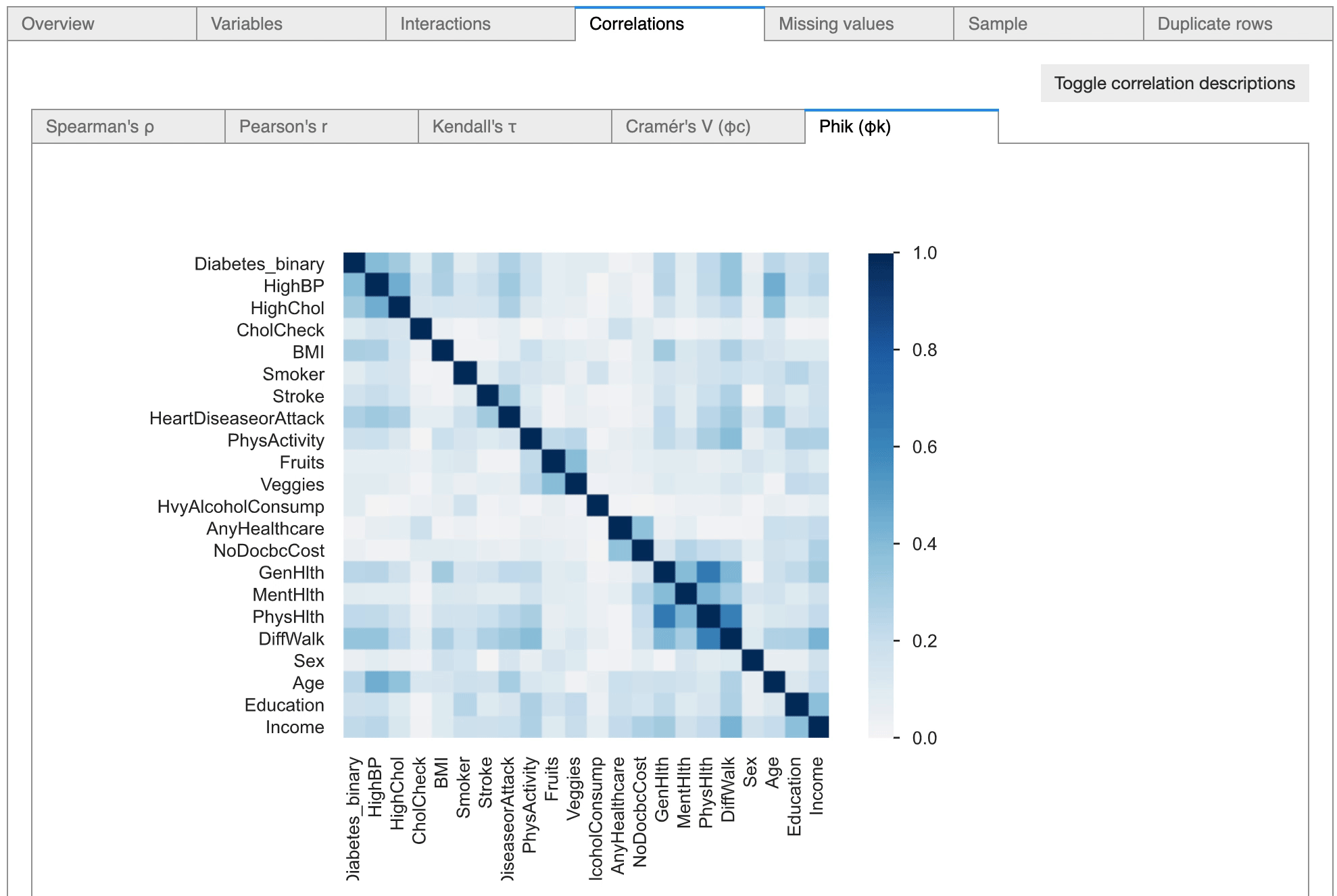
The pandas-profiling tool also highlighted highly correlated relationships between certain variables, which can be considered later for feature engineering tasks.
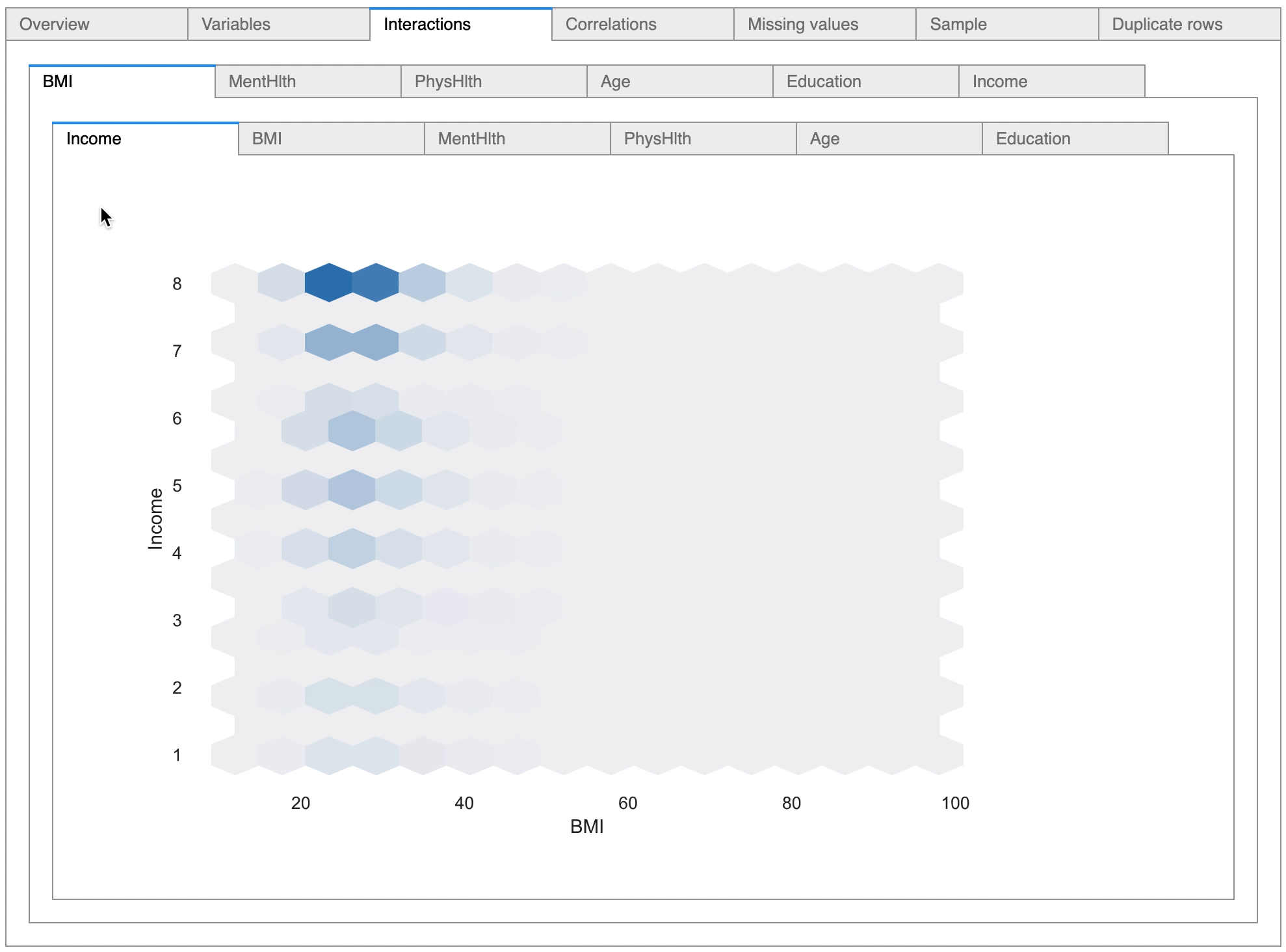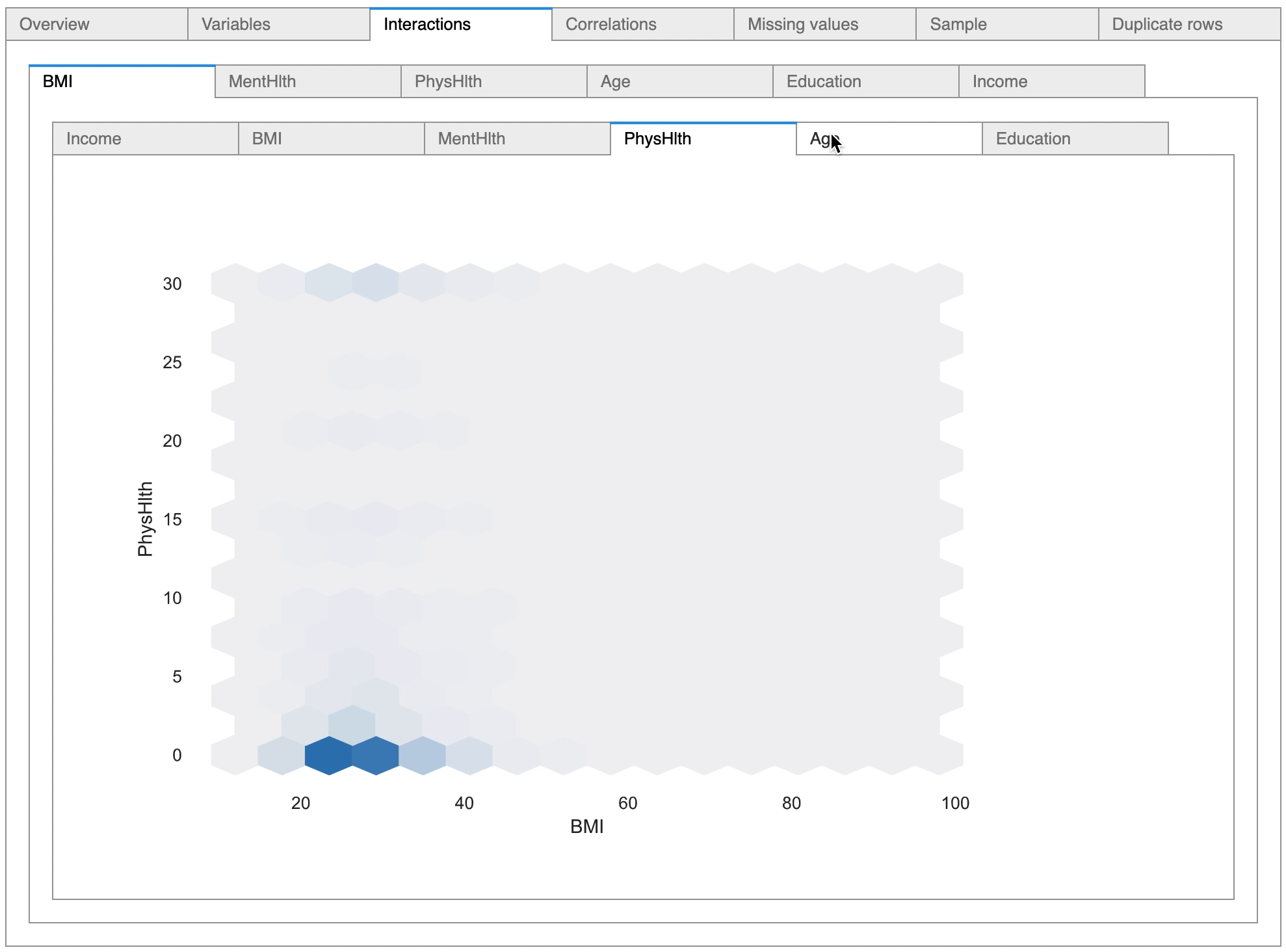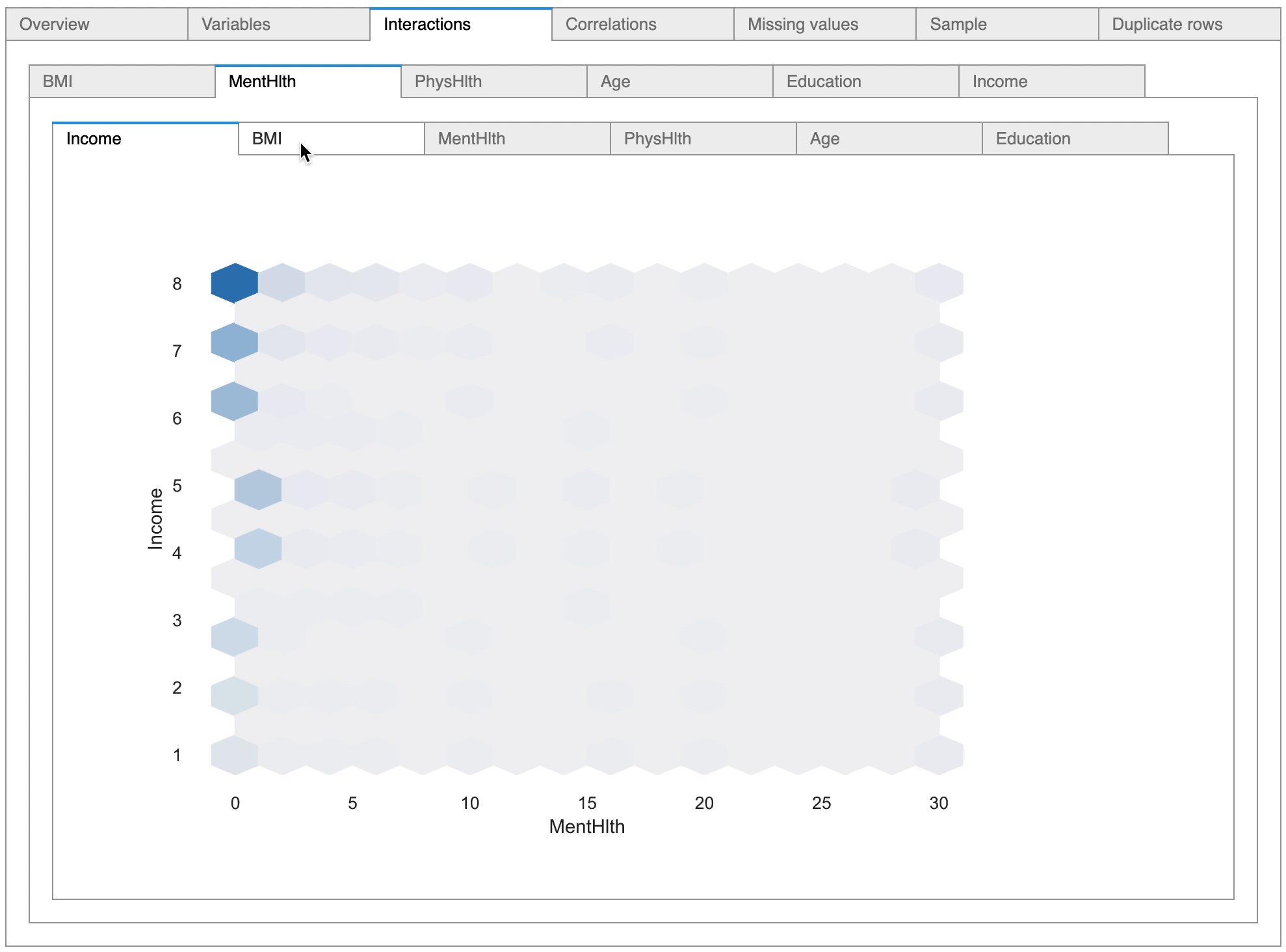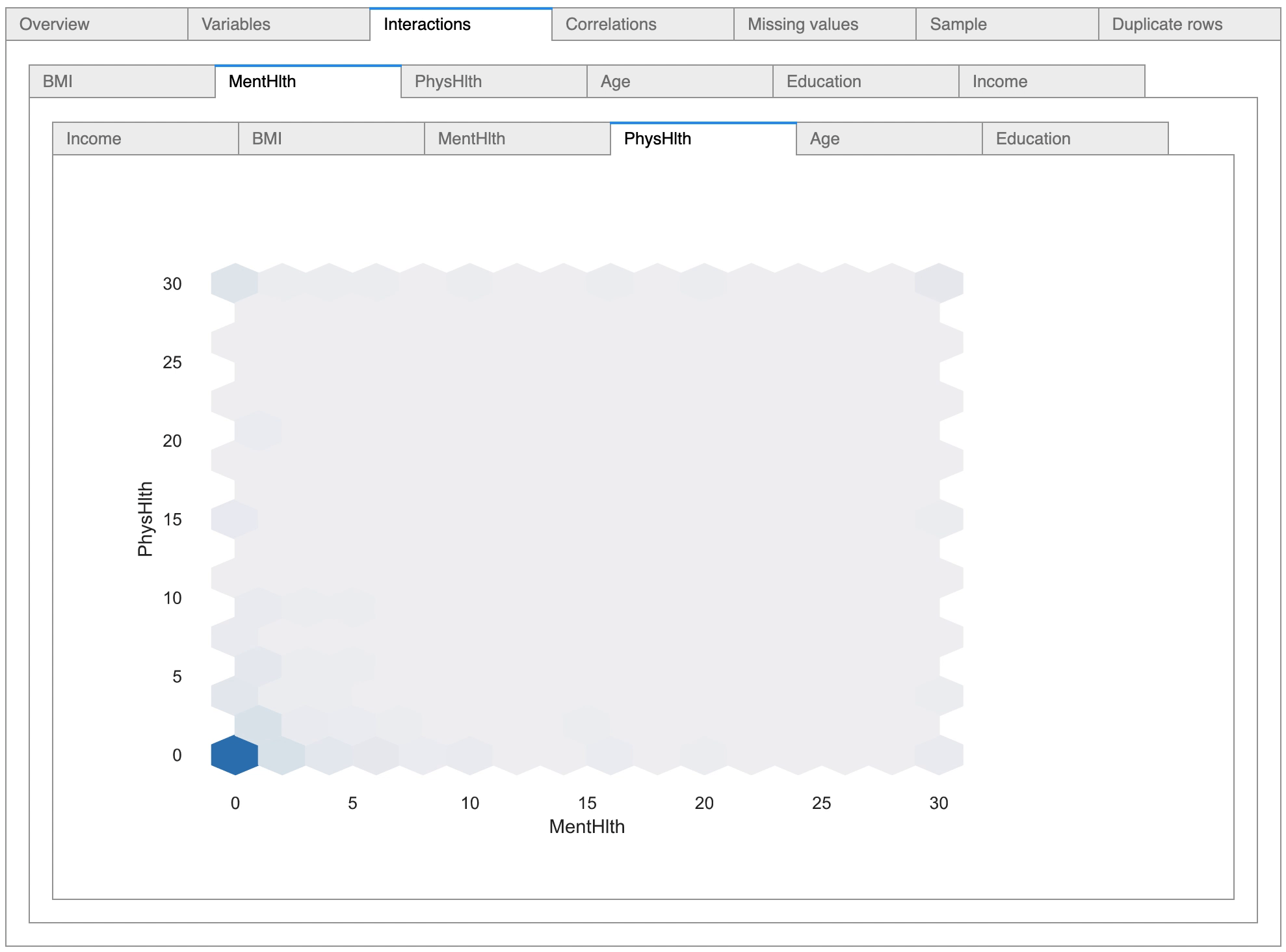
There are options to view the relationship between variables, and as can be seen in the above diagram, the pandas-profiling tool has detected six numerical variables and has plotted scatter plots depicting the relationship between the variables.
The tool is also highly useful in conducting statistical correlation tests between variables, as it provides options to conduct numerical correlation tests as well as categorical correlation tests.
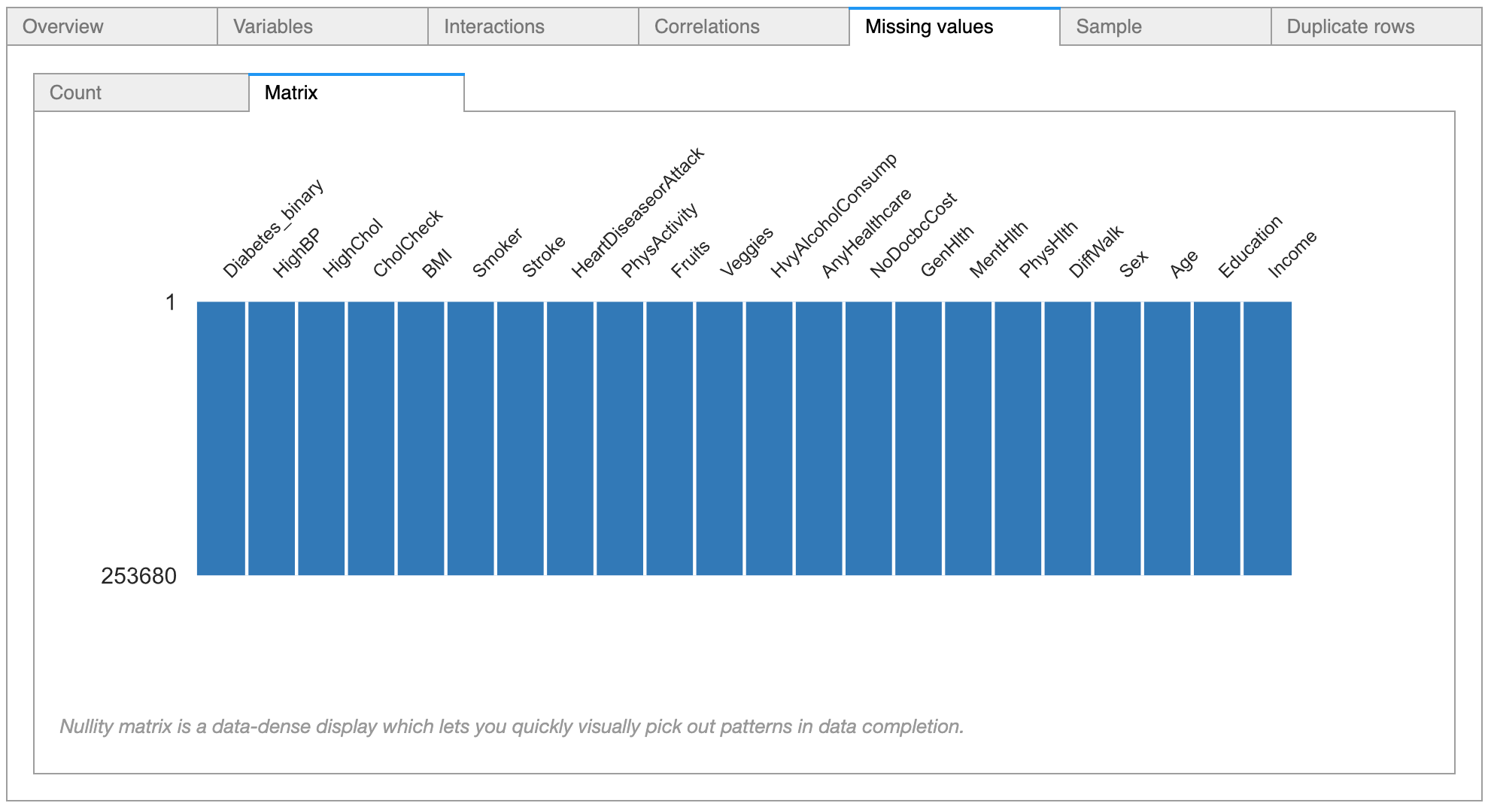
The pandas-profiling tool indicates that there are no missing values in the dataset.
Since 4.5% of the data consists of duplicates, it is possible to check the exact duplicate rows and how many times such rows are repeated.
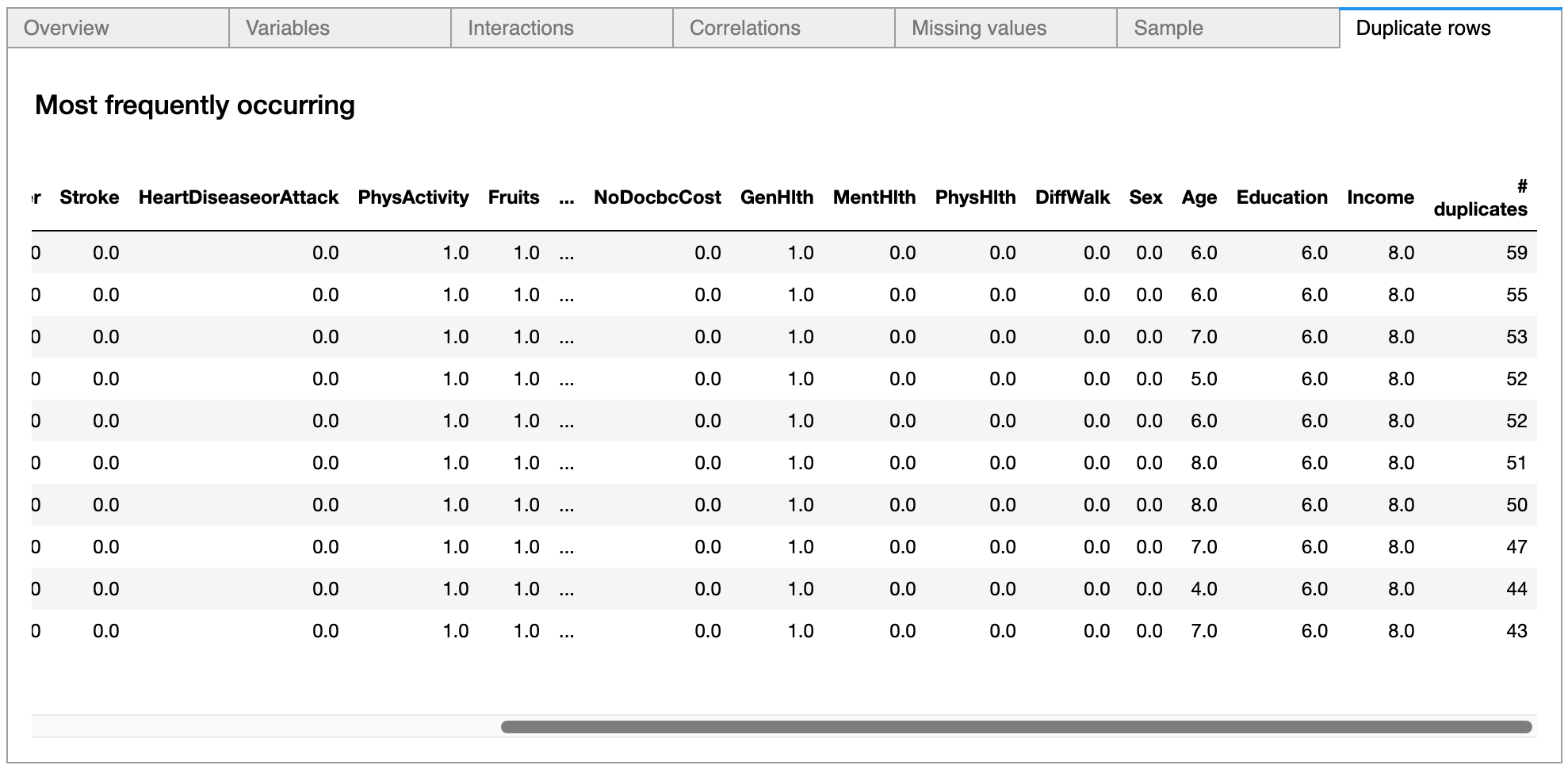
The entire pandas-profiling report can be viewed here.
Designing and Training the Synthesizer
Initially, the numerical and categorical columns are separated, as the type of variables is necessary to train the GAN model. Based on the data analysis that was done earlier, there are three numerical variables, and the rest are categorical variables.
To begin the process of generating synthetic data, the labels of the patients are separated based on their diabetic status. At first, a GAN is trained to generate synthetic data for patients who are diabetic.
The next step is to select the GAN model, and as discussed earlier, the Wasserstein GAN with Gradient Penalty is chosen. It is quite easy to initialize the GAN using the ydata-synthetic library.
Once the GAN is initialized, the training process is initiated.
The training time depends on the machine that is used for training. With an NVIDIA GPU, the training is much faster compared to training on the CPU. However, the library is also optimized to train well on the CPU.
Once the training is completed, the next step is to generate synthetic data. The GAN model is trained to understand the distribution of the data of diabetic patients, and 100,000 rows of data representing the diabetic patients are generated.
Compared to the 35,000 rows of diabetic patients that are present in the original dataset, using a GAN-based model, 100,000 rows of synthetic data of the diabetic patients are available. And another advantage of using ydata-synthetic is that the synthetic data is returned in the form of the input data, with all the columns intact.
The steps for training the GAN on the majority class are similar to the previous steps taken to generate data for the minority class. The number of epochs to train the GAN for the non-diabetic patients’ data is set to 100 to reduce the training time.
A simple code function is used to merge the synthetic samples of the majority and the minority classes.
The pandas-profiling tool is used to obtain a quick exploratory data analysis of the synthetic data.
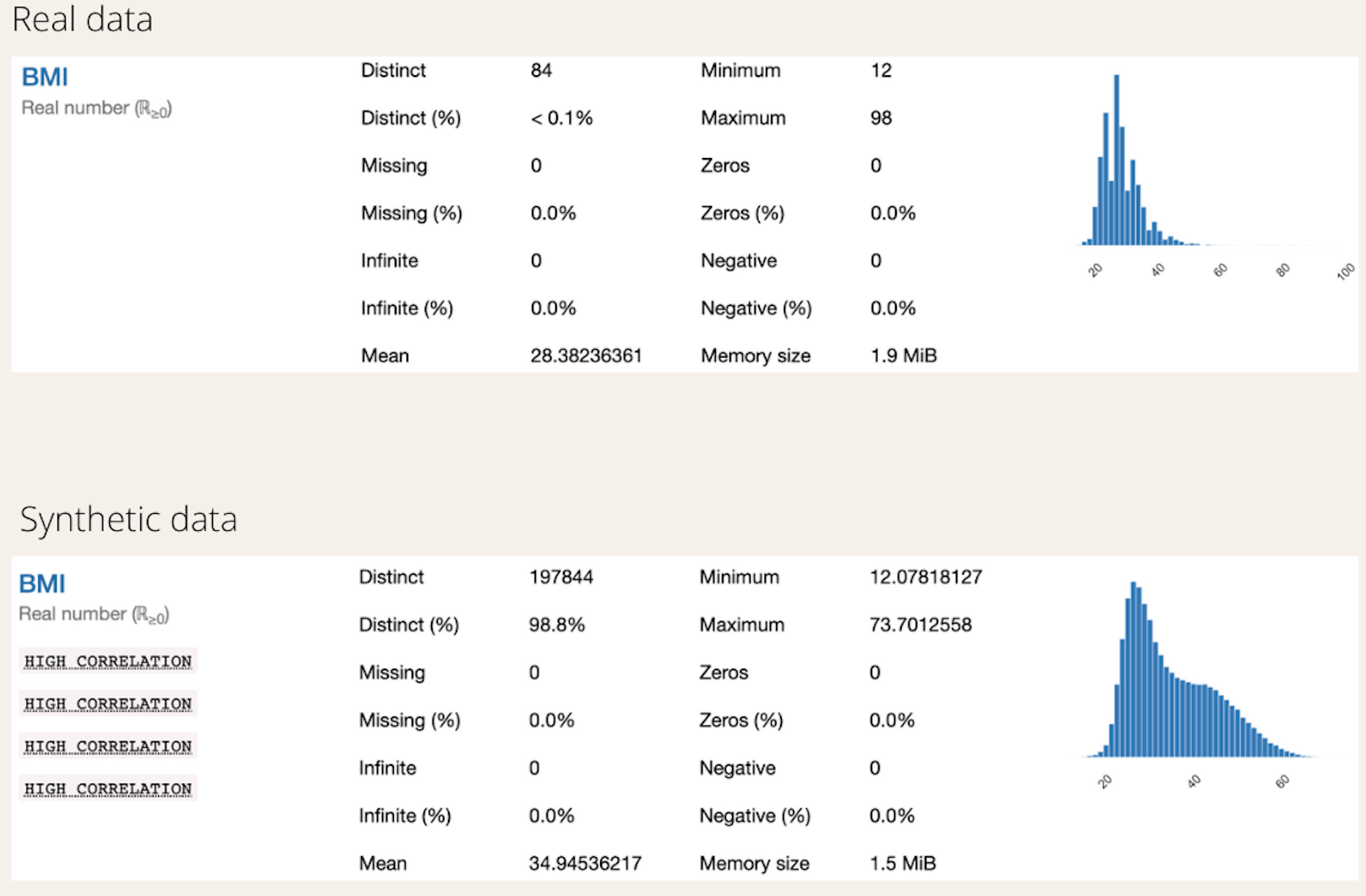
The distributions of the numerical columns from the real dataset and the generated dataset are evaluated.
Considering the BMI feature, the synthetic data has an acceptable representation of the real dataset. The range of values of the synthetic data is within the range of values of the real data. The mean of the synthetic data has shifted to the right, but overall, the BMI column of the synthetic data is comparable with the real data.
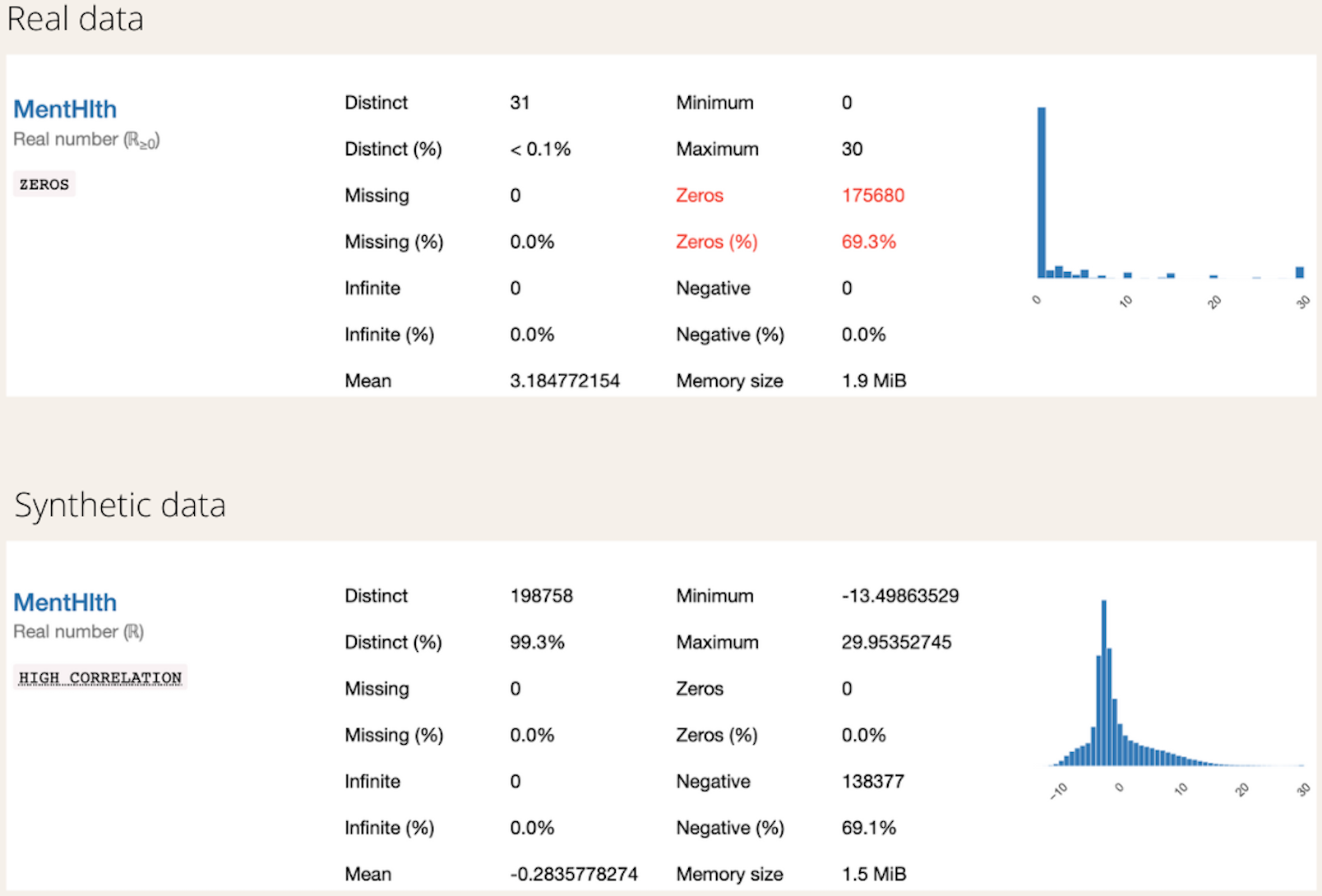
Comparing the “MentHlth” and “PhysHlth” can be a bit tricky. According to the definition of the columns based on the data, these two columns represent the number of days of poor mental health in the past 30 days and the number of days of a physical injury in the past 30 days, respectively. Therefore, a lot of values in these columns are zero, and the data is numerical, as the number of days is considered.
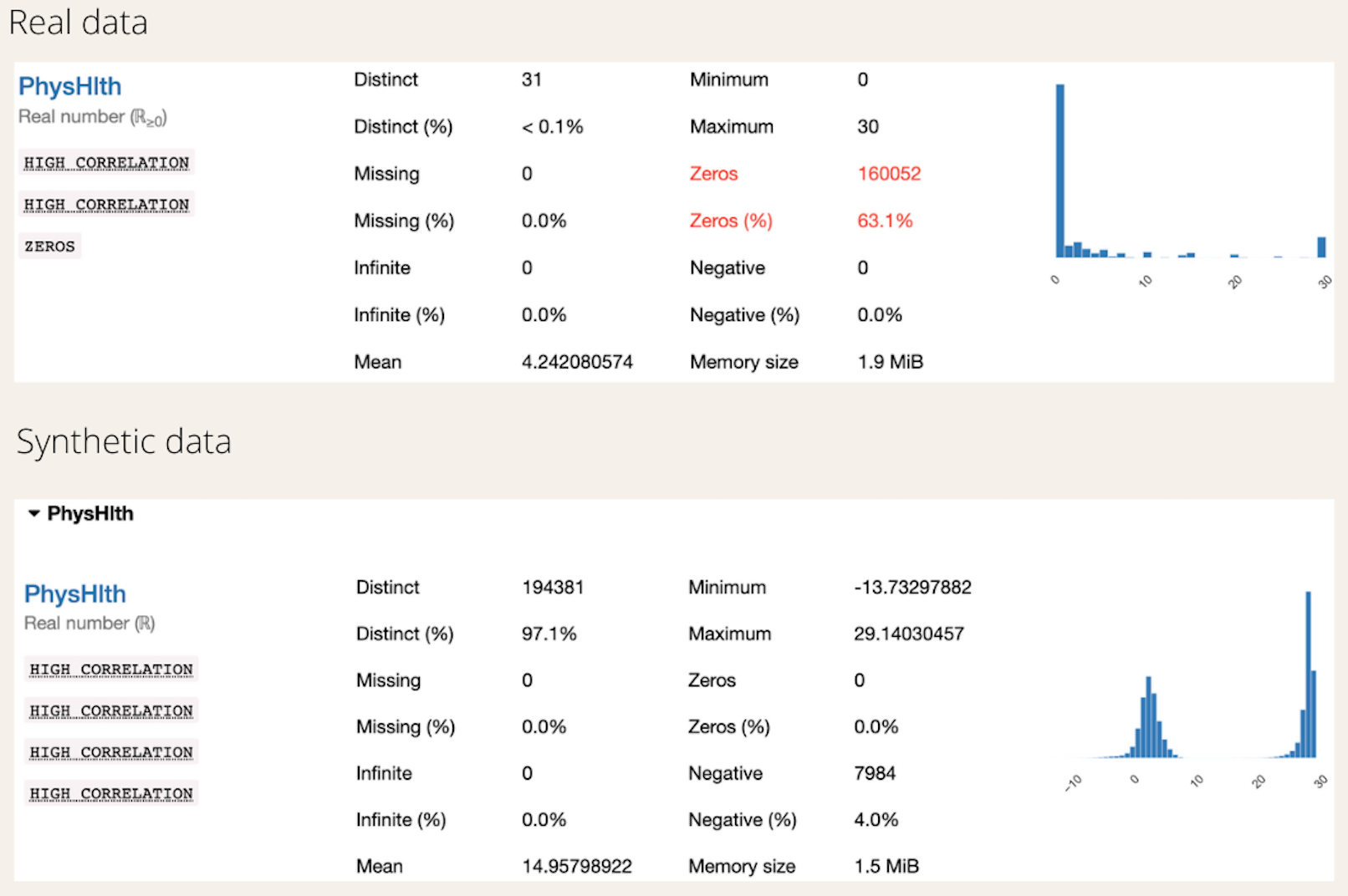
The synthetic data has generated negative values for the two columns, and this requires some feature processing before moving on to modeling, as the negative values would be converted to zeros.
When considering the feature “MentHlth”, the synthetic data has generated an acceptable distribution, as all the generated values are under 30. The mean of the synthetic data has shifted to the left.
However, the mean of the synthetic data for the column “PhysHlth” has shifted significantly to the right. But the generated values are less than 30, and replacing the negative values with zero might slightly improve the generated results.
The full pandas-profiling HTML report for the synthetic data can be viewed here, and the repository for the entire workings can be found here.
Final Words
The paradigm of AI is being transformed from model-centric to data-centric approaches, and the usage of synthetic data accelerates that transformation.
Synthetic data provides a low-cost and privacy-secured alternative to collecting and labeling real-world data, and anyone can utilize open-sourced powerful tools to generate data for their specific use cases.
There are many open-sourced tools available for generating quality synthetic data, and as discussed in this article, it is relatively easy to generate synthetic data by leveraging the power of GANs with the help of ydata-synthetic.
I hope you have learned how simple it is to generate synthetic data for tabular datasets, and looking forward to seeing how you will use these powerful tools to play with and create synthetic data. Cheers!
References
[1] T. Karras, S. Laine, and T. Aila, “A Style-Based Generator Architecture for Generative Adversarial Networks,” IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 1–1, 2020, doi: 10.1109/tpami.2020.2970919.
[2] I. J. Goodfellow et al., “Generative Adversarial Networks,” arXiv.org, 2014. https://arxiv.org/abs/1406.2661
[3] G. H. de Rosa and J. P. Papa, “A survey on text generation using generative adversarial networks,” Pattern Recognition, vol. 119, p. 108098, Nov. 2021, doi: 10.1016/j.patcog.2021.108098.
[4] M. Pasini, “10 Lessons I Learned Training GANs for a Year,” Medium, Jul. 28, 2019. https://towardsdatascience.com/10-lessons-i-learned-training-generative-adversarial-networks-gans-for-a-year-c9071159628
[5] U. R. Dr A, “Binary cross entropy with deep learning technique for Image classification,” International Journal of Advanced Trends in Computer Science and Engineering, vol. 9, no. 4, pp. 5393–5397, Aug. 2020, doi: 10.30534/ijatcse/2020/175942020.
[6] M. Arjovsky, S. Chintala, and L. Bottou, “Wasserstein GAN,” arXiv.org, 2017. https://arxiv.org/abs/1701.07875
[7] I. Gulrajani, F. Ahmed, M. Arjovsky, V. Dumoulin, and A. Courville, “Improved Training of Wasserstein GANs,” arXiv:1704.00028 [cs, stat], Dec. 2017, [Online]. Available: https://arxiv.org/abs/1704.00028
[8] “Build Basic Generative Adversarial Networks (GANs),” Coursera. https://www.coursera.org/learn/build-basic-generative-adversarial-networks-gans?specialization=generative-adversarial-networks-gans (accessed Jul. 28, 2022).
GANs for Synthetic Data Generation was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


