


")
An AI Practitioner’s Guide to the Kdrama Start-Up (Part 2)
Last Updated on July 21, 2023 by Editorial Team
Author(s): Jd Dantes
Originally published on Towards AI.
Artificial Intelligence
Generating fun with adversarial networks (GANs).
In the previous post, we talked about neural networks, training, and loss. We’ll now dive into generative networks, as well as talk a bit more about what Start-Up touched on, besides the technical know-how.
Let’s pick up where we left off!
SPOILER WARNING: You may want to proceed only if you’ve finished the series.
#2 It’s actually pretty well-researched (continued).

Let’s go back to the scene where Dosan mentions two neural networks. On the whiteboard you’ll see the terms generator and discriminator, as well as some formula on the upper right with the log and whatnot.
These actually refer to Generative Adversarial Networks, or GANs. Why generative? As opposed to the typical neural network which takes an input image and outputs a classification like “dog” or “cat”, with GANs you have the opposite. You say that you want a dog, and its output is an image of a dog. Actually, it can generate a full spectrum of dog images — from short, fluffy Pomeranians to bigger Golden Retrievers.

So where are the two neural networks? You may have guessed it — the generator is one neural network, while the discriminator is yet another neural network.
While the generator is new to us, the discriminator functions as a classifier that we’re used to. Give it an input image and it tells you if it’s a dog or a cat. Except this time, the input image can come from either (1) actual training images, or (2) a fake image created by the generator! You can see this in the diagram on the whiteboard.

So usually we can assign the neural network to output “1” for a dog and “0” for a cat; in this case, there’s another difference. Rather than saying if it’s a dog or a cat, the discriminator instead predicts if the image is real or not. If the output is “1”, then the discriminator is guessing that the image is real, while an output close to “0” is a guess that the image was a fake created by the generator.
That’s it! If you’ve searched about GANs, then you’ve probably seen the analogy of the discriminator as a police officer trying to catch a criminal creating counterfeits (the generator in this case). Or in Dalmi’s case, trying to find out the real Dosan who sent the letters 15 years back.

So the discriminator tries to spot the discrepancies to know if it’s a fake.

When the generator gets caught though, it learns, and tries to step up its game.

After several repetitions of this back-and-forth of getting caught and learning to create better counterfeits, the generator becomes so good that the discriminator gets totally confused and can’t tell which is which. Like Dalmi earlier.
Or in some cases, maybe not. (GANs could be pretty hard to train to convergence.)

What about the equation with the log stuff?
Again, if you’d rather skip this part, feel free to go ahead. But if this is of interest, then read on. 🙂
Let’s go back again to the whiteboard. We’ve gone through the generator and the discriminator, but haven’t touched the formula on the upper right corner. Let’s zoom in on that, but grab the one from the official paper so things are easier to see:

Without the context, that may look confusing at first. Let’s break it down.
From the discriminator’s point of view, we want to have a high score for the real images that are predicted as “1”, as well as for artificial images that were correctly detected as fake (tagged as “0”). In pseudocode, it would be something like:

Then, over all training images (whether real or generated), we want the total score to be as high as possible.
So how does this translate into the equation? Recall that part in the previous post, where we used the absolute value for the loss? Translated to pseudocode, it would have been something like:

But instead of manually coding for the corner case, it turned out that there are other mathematical operations that are convenient, like squaring the numbers.
For the case of GANs, we can try to do the same. To represent the if-else logic, what mathematical operation or function can we use to toggle between “1” and “0”? You’ve probably guessed it — we can use the logarithm! If you’ve forgotten what a logarithm is, you can look at this graph:
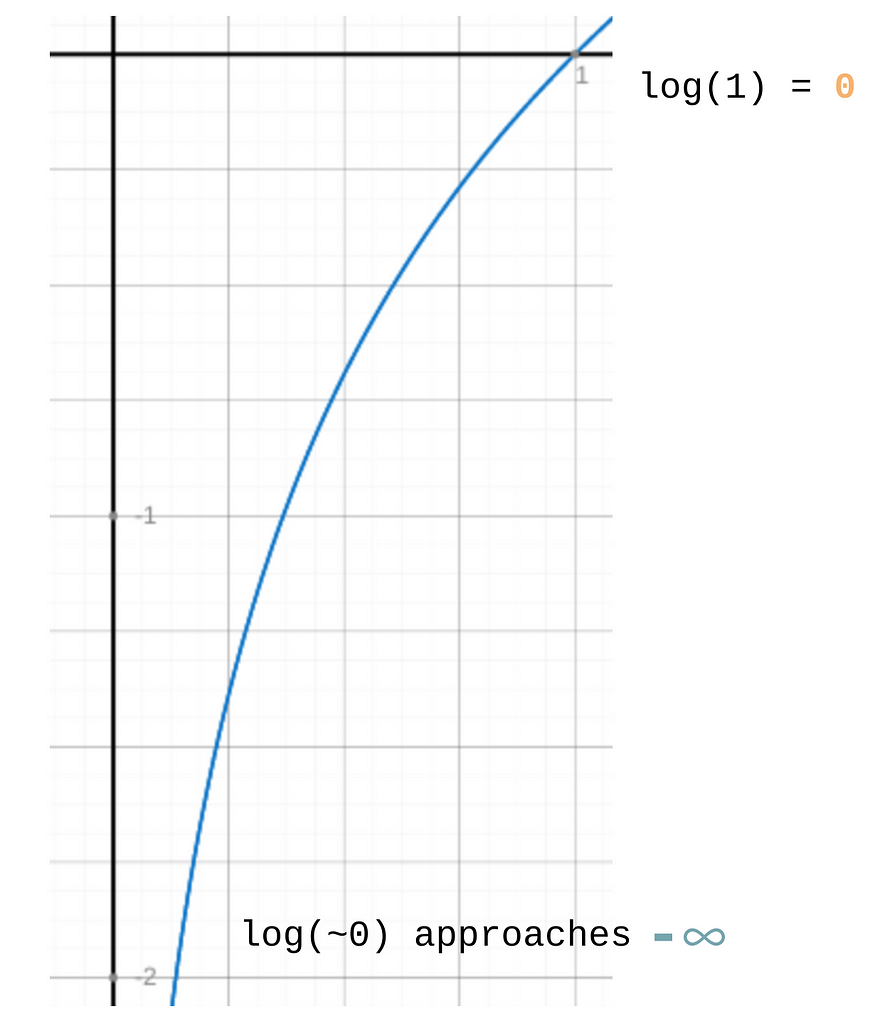
The logarithm as we approach zero is negative infinity, and the logarithm of one is zero. So if we wanted to maximize things, we don’t want them heading towards negative infinity, and try to get the sum towards zero instead. So in our pseudocode from earlier, negative infinity would be considered the LOW score, while a score near zero would be HIGH.
Let’s go through the case where the image is real. If the prediction ~1, then log(~1) = 0 (HIGH). If the prediction ~0, this is wrong, and log(~0) would evaluate to negative infinity; this is a bad score, so the neural network will learn to penalize such mispredictions. This is represented by the first term of our objective function:

For real images, the discriminator (D) should output near 1. log(~1) = 0 (HIGH). If it mispredicts it to be near 0, log(~0) approaches negative infinity (LOW), so the score is penalized. The Ex~pdata(x) thing just means get from the real images (i.e., the training data).
How about the case when the image is a fake created by the generator? The flow is similar, but first let’s smoothen out the notation. When we write D(x), this means the prediction of the discriminator for some image x. Again, D(x) = 1 means that it’s predicting the image x to be real, while D(x) = 0 is a guess that it’s a fake. For the generator, its output is not a prediction, but an image. So G(z) for some input z is an image. You don’t have to mind the z here, it can be anything, even random noise, such that if you change it a bit, you’ll be sweeping across the spectrum of possible images that can be produced (e.g., from a Pomeranian to a Golden Retriever).
So if the discriminator takes in a generated image as input, we write it as D(G(z)). Now, for this case, we don’t want to just take the logarithm directly. For a proper discriminator, D(G(z)) should be close to zero (i.e., it catches it as fake). If we take the logarithm directly, then log(D(G(z)) = log(~0) which approaches negative infinity (LOW). We’d be penalizing the discriminator for doing its job properly in catching the fakes. What can we do?
We can just flip things around! Rather than taking the log of D(G(z)), we can just take the log of (1 — D(G(z))! This way, things would be reversed. For fake images, log(1 — D(G(z)) = log (1 — predicted closed to zero) = log(1) = 0 (HIGH)!
Hence, we get…

…applicable to the fake images. See the Ez~pz(z)? That’s just shorthand for “over all fake images” (remember that z denotes the input to the generator, which can just be random noise).
So when we add them, we get the equation from before which the discriminator wants to maximize:

Now, the generator wants the opposite to happen — that’s why they’re called adversarial networks! So it wants to minimize things…
…which is the equation from before!
So the two networks are in a two-player minimax game, each doing their own gradient descent (or ascent). Training stops at equilibrium, where the generator has become so good that the discriminator can’t tell real from fake. So at this point, the discriminator really is just at 50% accuracy — essentially no different from doing a coin toss.
And we’re done, great! You can now understand the random scribbles behind Dosan. I doubt you’d use them to talk about people though, haha.
GAN Applications — more fun stuff!
You may not use GANs in casual conversation, but they do have their interesting applications. Look at the picture below. Can you guess which one is real, and which one isn’t?

Do you have your guess?
…
Well, both of them are fakes created by GANs! Amazing, right? You can refer to the paper and other articles for more details.
Aside from images, GANs can be used for video too! Just look at Injae here:
…except that the person there is Tzuyu, a K-pop group member, and not the actual actress Kang Hanna.
I’ve only shown these, but really, there are many more applications of GANs. If you’d like to learn more, I would recommend searching for compilation articles like this one (or his whole GAN series here), or look for “awesome Git” repositories like this one, or this other one.
Aside from being fun, GANs have potential for use in specific industries like media and graphics. Or simply for general machine learning! GANs can be used to generate training data to improve neural networks. Remember the face-off between Injae and Dalmi? GANs could possibly be used to improve models designed for detecting counterfeit.

And that’s all about GANs for now! Aside from the technical content that we’ve gone through, the show also managed to get a few more little things correct, such as:
- The use of Linux (Ubuntu). Developers (even for software outside machine learning, like websites) tend to use Linux as their operating system. Not only is it open source and free to use, but the tools and environment as a whole are generally easier to work with compared to if you were developing on other operating systems.

- Actually using code for AI. The programming languages and libraries that they used are actually for AI. We see lots of examples of this during the hackathon episode.
- For starters, they’re using actual programming libraries for machine learning. Numpy is used for representing data as matrices, sklearn (scikit-learn) is useful for modeling data, and matplotlib is for visualizations. The code itself is in Python, one of the most common programming languages used for this kind of stuff.

- Weights and biases. We already know from Part 1 that weights are what you multiply to inputs (e.g., the image pixels) before summing them together. We can add an extra number to this sum to shift things around and make the equations nicer. This extra number is called the “bias” term. As someone pointed out, this shouldn’t be confused with your K-pop bias. Extra reading.

- We’ve already seen “epochs” before, which relates to the number of times that the neural network has seen the whole dataset. Usually, going over the whole dataset at once is too computationally intensive, so we chunk our operations in “batches”.

- Activation functions. After summing the weighted inputs and bias, this sum is actually squashed together to clamp the possible values between a minimum and maximum value for mathematical convenience. Values can be clamped between 0 and 1 (and be interpreted as probabilities) using the sigmoid as the mathematical operation. There are other options; for example, if you wanted the minimum to be -1 instead of 0, then the hyperbolic tangent function is a good fit.

- Sigmoid and sigmoid prime. We’ve just mentioned the sigmoid function, usuallly written as the Greek letter sigma (σ). If you’ve checked the definition of the sigmoid, you can verify that the code below matches σ(x) = 1/(1 + exp(-x)). What about sigmoid prime? Recall Part 1, where we discussed how we want to get to the bottom of the loss curve by rolling against the incline. Other words used to refer to the incline are slope, gradient, and derivative. Generally, if you have some math function f(x) (read as “F of x”), the derivative is written as f’(x) (note the apostrophe after f). “F apostrophe” sounds too long, so it’s commonly read as “F prime”. So for the sigmoid function, “sigmoid prime” is its derivative, and by coincidence, conveniently turns out that σ’(x) = σ(x) * (1 — σ(x)), which you see in the code. More reading here and here.

Those said, there were a couple of scenes that could raise some eyebrows:
- In the face-off between Dalmi and Injae, they were using these boxes. Except those looked like Raspberry Pis (RPis), which are mini-computers and useful for home automation projects, but not really for AI. More likely candidates for AI embedded boards are from GPU makers, or companies that make custom AI hardware themselves. Sure, a case is a case, and maybe we can say that in Start-Up they had other hardware inside. Or I guess you really could try running neural networks on a Raspberry Pi — it will likely be slower, but I guess that’s the point. Yet another question is how easy it is to port a mobile app to a Raspberry Pi; let’s just say that they used a separate prototype and/or used the parts of the code that could run on a laptop and RPi, not necessarily the whole app per se. Or yeah, maybe they did go ahead and set up something like this.


- Then, there was the part where they had no backup code. Hard to imagine that the team of Dalmi and Injae really didn’t have backups for their code, even locally. Or maybe we can say that for security purposes they only had it on some remote-access servers? But still. I guess we can say that the twins really just screwed them up.


And that’s about it!
So overall, Start-Up was pretty well-researched. There were a few points of contention, but we could bridge those over a bit. Aside from the technical know-how, Start-Up also hit a few other aspects of AI, such as the experiences you would likely encounter when working in the field, as well as situations that could lead to a moral dilemma.
We already covered a lot so we can stop here, but if you’re ready for more, let’s wrap up in the third and final part of this series, which will be out next weekend! You can get updated when that comes out here.
If you’d like to go back to the first post, you can do so here.
Acknowledgments
Thanks to Lea for her suggestions and reviewing early drafts of this post.
Connect on Twitter, LinkedIn for more frequent, shorter updates, insights, and resources.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

