



Create your first Text Generator with LSTM in few minutes
Last Updated on March 10, 2021 by Editorial Team
Author(s): Maissa Ouni
What if I tell you that an entire short sci-fi film has been written by an AI bot built on LSTM recurrent neural network, and it has even received positive reviews and critics, Surprised ?! well, I’m sure you are because that’s what I felt watching “Sunspring” for the first time, I mean I know it can’t be compared to Steven Spielberg’s or Alex Garland’s screenwriting quality but no wonder if in the next few years AI bots will compete against them in the Academy Awards. Indeed, we should no longer be surprised by what artificial intelligence is capable of in order to flip our world upside down, making it a better, “easier”, and most comfortable place to live in.
From all of the AI subfields, in my opinion, NLP has the coolest and most exciting applications. One of them is text generation that we should have a deep look at it.
In this article, I will briefly explain how RNN and LSTM work and how we can generate texts using LSTM in Python.
But before we do, for those who didn’t watch it yet, I want you yo to go and check on“Sunspring” https://www.youtube.com/watch?v=LY7x2Ihqjmc
Table Of Content
· 1.Recurent Neural Network
· 2.Long short-term memory
· 3.Text Generation
∘ 1.Text Processing
∘ 2.Creating Batches
∘ 3.Creating & training the Model
∘ 4.Generating text
1.Recurrent Neural Network
Texts, audios, videos, time-series data … what do they have in common? The answer is clear that each one of them is made up of ordered sequences in which each chunk depends on the precedent ones to make sense. And that’s what makes the classic feed-forward networks incapable of handling this kind of data as they don’t have any time dependency or memory effect. This is where RNNs come into play, by incorporating an extra dimension, which is the time they function more efficiently than the other types of ANN in processing sequential data to create predictive and generative models.
It works like this: Each generated output not only relies on its input but also on the entire history of the inputs that have been fed to the network in previous time steps. That can be summarised into two major equations:
•INTERNAL STATE UPDATE:
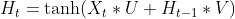
•OUTPUT UPDATE:
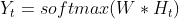
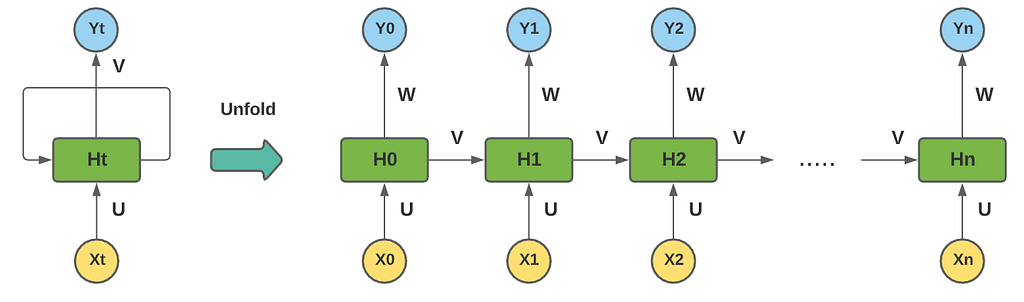
- X(t) is the input, Y(t) is the output, H(t) is the internal state (who plays the role of internal memory ) at the current time step, and H(t-1) the internal state of the previous time step.
- U, W, and V are the weights shared by the network. In fact, in RNN, the same parameters are shared across all the steps, which mainly reduce the number of parameters and the computation costs.
At time step t=0, X0 is passed to the network where it gets analyzed and processed by the cell in order to compute H0 and generate the output Y0, then at the next time step t=1, X1 incorporate with H0 to compute the new internal state H1 and then produce Y1, and the same process continues running till the nth time step.
RNN’s Issues
RNN’s applications are versatile and can be found everywhere, it’s used for stock prediction, speech recognition, text summarization and generation, search engines, machine translation … so in order to give accurate results, it has to be trained on “infinity” of sequences which leads to two main problems:
- Gradient Vanishing
- Gradient Exploding
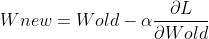
We know that the goal of calculating gradient by backpropagation (in this case backpropagation through time ) is to find the optimal weights that will minimize the total loss of each connection, so if the sequences are too long and in the case of the gradients are too small (smaller than 1), the weights will remain the same, means the network will not be able to learn and recall what happened in the first layers and that’s the problem of Vanishing Gradient, but, on the opposite side where the gradients are too large (greater than 1), the learning will diverge as the weights will be very far from the optimal values and that’s the issue of the Exploding gradient.
2.Long short–term memory
As we’ve seen, RNNs work well only on small sequences as they fail to memorize information for a prolonged period of time. That’s where LSTM joins the game. By overcoming the traditional RNN’s limitations thanks to its Gated cell structure, it establishes a long-term dependency and becomes able to recall and remember data over multiple time steps, which makes the LSTM one of the most popular and efficient recurrent neural network model to date.
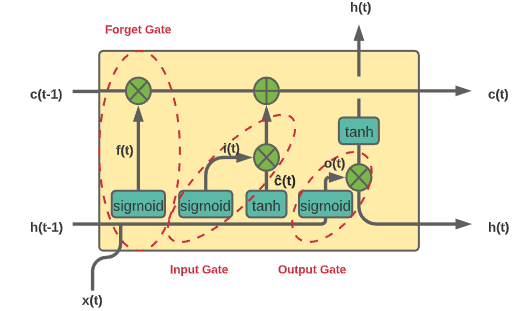
Each LSTM unit is composed of a simple RNN cell and another cell responsible for the long term memory, and 3 gates: the Input Gate, the output Gate, and the Forget Gate. They work as filters that decide which information is going to be remembered and which is going to be forgotten by the network.
The whole process works like this :
- In the first step, the Forget gate assesses which data is going to get rid of from the cell state by applying a sigmoid layer to the combination of the current input x(t) and the hidden state from the previous time step h(t-1), it produces values between 0 and 1, for 0 means this information is going to be thrown away and 1 it’s going to be kept.
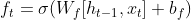
- In the second step, the input gate controls whether the memory cell is updated by combining the output of a sigmoid layer and the output of a tanh layer. The sigmoid layer applied to both x(t) and h(t-1) produces values ranges from 0 to 1, where 1 signifies that this information is important needs to be added to the cell state, while 0 it’s not. The tanh layer returns values between -1 and 1 to help regulate the network and creates a vector of new candidate values č(t) that could be added to the state.
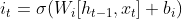
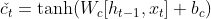
- Then in the next step, the new cell state is created based on the previous steps calculations.
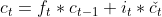
- Finally, in the last step, the output gate chooses what the next hidden state should be. First, the previous hidden state and the current input are passed to the sigmoid layer to produce o(t), then it is multiplied with the output of the tanh function applied to the new calculated cell state in the previous step.
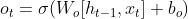
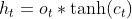
3.Text Generation
By definition, text generation is the mechanism of producing new texts automatically by the neural network based on a huge corpus of texts, so let’s see how it’s made using LSTM.
First of all, you need to import Numpy, Pandas, and Tensorflow libraries. For the dataset, we’ll choose all of Shakespeare’s works, mainly for two reasons:
- It’s a large corpus of text. It’s usually recommended you have at least a source of 1 million characters total to get realistic text generation.
- It has a very distinctive style. Since the text data uses old-style English and is formatted in the style of a stage play, it will be very obvious to us if the model is able to reproduce similar results.
You can download Shakespeare’s dataset or grab any free text you want from Gutenberg: https://www.gutenberg.org/
The text looks like this.
1 From fairest creatures we desire increase, That thereby beauty's rose might never die, But as the riper should by time decease, His tender heir might bear his memory: But thou contracted to thine own bright eyes, Feed'st thy light's flame with self-substantial fuel, Making a famine where abundance lies, Thy self thy foe, to thy sweet self too cruel: Thou that art now the world's fresh ornament, And only herald to the gaudy spring, Within thine own
1.Text Processing
Text Vectorization
We know that a neural network can’t take in the raw string data, so we need to encode it by assigning numbers to each character. Let’s create two dictionaries that can go from numeric index to character and character to numeric index.
2.Creating Batches
Overall what we are trying to achieve is to have the model predict the next highest probability character given a historical sequence of characters. It’s up to us (the user) to choose how long that historical sequence. Too short a sequence and we don’t have enough information (e.g., given the letter “a”, what is the next one), too long a sequence and training will take too long and most likely overfit to sequence characters that are irrelevant to characters farther out. While there is no correct sequence length choice, you should consider the text itself, how long normal phrases are in it, and a reasonable idea of what characters/words are relevant to each other.
Training Sequences
The actual text data will be the text sequence shifted one character forward. For example:
Sequence In: “Hello my nam” Sequence Out: “ello my name”
The batch method converts these individual character calls into sequences we can feed in as a batch. We use seq_len+1 because of zero indexing.
Here is what drop_remainder means: drop_remainder: (Optional.) A tf.bool scalar tf.Tensor, representing whether the last batch should be dropped in the case, it has fewer than batch_size elements; the default behavior is not to drop the smaller batch.
sequences = char_dataset.batch(seq_len+1, drop_remainder=True)
- Grab the input text sequence
- Assign the target text sequence as the input text sequence shifted by one step forward
- Group them as a tuple
Generating training batches
Now that we have the actual sequences, we will create the batches. We want to shuffle these sequences into a random order, so the model doesn’t overfit to any section of the text but can instead generate characters given any seed text.
3.Creating & training the Model
We will use an LSTM based model with a few extra features, including an embedding layer to start off with and two LSTM layers. We based this model architecture on the DeepMoji.
The embedding layer will serve as the input layer, which essentially creates a lookup table that maps the numbers indices of each character to a vector with an “embedding dim” number of dimensions. As you can imagine, the larger this embedding size, the more complex the training. This is similar to the idea behind word2vec, where words are mapped to some n-dimensional space. Embedding, before feeding straight into the LSTM usually leads to more realistic results.
4.Generate text function
Currently, our model only expects 128 sequences at a time. We can create a new model that only expects a batch_size=1. We can create a new model with this batch size, then load our saved model’s weights. Then call .build() on the model, and then we create a function that generates a new text.
And Voila !! this is what the generated text looks like

You might notice that some of these generated scenes are somehow not realistic, but You can squeeze some parameters and also add a Dropout layer to avoid overfitting, then the model could be better at generating texts.
References & Additional Resources:
[1] https://en.wikipedia.org/wiki/Sunspring
[2] https://medium.com/analytics-vidhya/understanding-rnns-652b7d77500e
[3]https://towardsdatascience.com/understanding-rnns-lstms-and-grus-ed62eb584d90
[4]https://machinelearningmastery.com/text-generation-lstm-recurrent-neural-networks-python-keras/
Create your first Text Generator with LSTM in few minutes was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts



Recent Posts


")



