



GPTs vs. Human Crowd in Real-World Text Labeling: Who Outperforms Who?
Last Updated on May 16, 2023 by Editorial Team
Author(s): Evgeniya Sukhodolskaya
Originally published on Towards AI.
Who outperforms text classification? We decided to find out.
The IT business world has been abuzz with controversy related to Large Language Models (LLMs). One of the hot topics is whether GPT-like models can replace humans for data annotation and generation tasks. The prospect seems likely since LLMs can handle text classification, machine translation, and other NLP-related tasks in a zero-shot manner with impressive quality.
The striking potential of LLMs has encouraged a lot of comparative research revolving around “humans vs. ChatGPT”. We decided to run an experiment on text classification because LLMs are known to be highly successful at solving this task. We took the perspective of an IT business looking for ways to optimize processes, and our goal was to find out who performs better on text classification: crowd or a GPT model.
The experiment setup
Many IT businesses can access GPT APIs and crowdsourcing solutions such as Amazon MTurk, Toloka, or CrowdANALYTIX, so it comes down to a choice of tools. In our experiment, two text classification tasks were given to GPT 3, GPT 3.5 (ChatGPT), and GPT 4 models and labelers from the Toloka crowdsourcing platform (Tolokers).
To make the comparison more “fair” and closer to a real-life setting, besides testing GPT models in a zero-shot manner, we downstream them using prompt engineering techniques and showed the same set of correctly labeled examples to the models and the Tolokers. For the same reason, we chose datasets in English because this is the most “understandable” language for LLMs.
Datasets
Usually, text classification tasks solved in production have two characteristics: they are unique (have never been “seen” before) and hard to describe using a strict set of rules. We separated these characteristics in our experiment for better explainability. That’s why we use two text classification datasets: one with data “previously unseen” by GPT models and human annotators, and one with non-trivial classification tasks from an e-commerce domain.
DS-I, Film Reviews
The idea here was to recreate a popular dataset for text classification. We had three requirements for the data:
- Binary classification
- Easily defined and detected classes
- Popular and relatively trivial task
Our final choice was the IMDB movie review dataset. Since our goal was to use an “unseen” task setting, we gathered a new dataset of film reviews with Tolokers to create a unique dataset.
Classifying movie reviews as “Positive” or “Negative” was the perfect task because it’s simple and well-studied. To establish ground truth, we had 3 crowdsourcing experts on our team label the data and we used majority vote to select the final results. Full agreement was reached in 97% of the labels, proving the task’s simplicity. For the experiment, we randomly sampled 1000 reviews; 53% of them were “Positive.”
DS-II, Amazon “Shopping Queries Dataset”
The authors of “Shopping Queries Dataset: A Large-Scale ESCI Benchmark for Improving Product Search” gathered a dataset of challenging customer queries paired with results shown on an Amazon website and classified pairs into four categories: “Exact”, “Substitute”, “Complement” and “Irrelevant”. This is a textbook example of a classification task in e-commerce, usually solved with the help of crowdsourcing due to its complex nature. It requires attentiveness and creativity to distinguish class labels because there is a high probability of “grey areas,” and the cost of a mistake is very high.
Since APIs for GPT models do not have any functionality for uploading non-textual inputs, we modified the original dataset. For each search query, we created a corresponding product description by combining the textual fields “product_title”, “product description”, “product_brand” and “product_color”.
The authors claim that “the resulting labels are not perfect and can be noisy,” so for transparency, we added an “Unjudgable” class and had a team of e-commerce experts label a random sample of 1000 items. Ground truth labeling used an overlap of 3, with a full agreement of 85% achieved between final labels selected by majority vote. In cases where all 3 labels were different, we selected the ground truth label randomly. The distribution of classes in the experimental dataset was: Exact — 465, Substitute — 304, Irrelevant — 107, Unjudgable — 15, Complementary — 1.
For both tasks, our experts designed labeling instructions based on their experience in designing crowdsourcing projects of a similar nature and provided class-balanced descriptive few shots for training GPTs and the crowd.
GPTs downstreaming
It is a well-known fact that the weights of GPT 3+ models are not open-source, and very few companies can afford to recreate an LLM model of the same size as GPT 3. Therefore, fine-tuning GPTs as a downstreaming technique seems like an unreasonably expensive option (a good solution might be to train a much smaller task-specific transformer).
However, it is even more well-known that “Large Language Models are few-shot learners” and with models the size of GPT 3+ prompting starts working reasonably well.
Prompt tuning
We designed three stages of prompt tuning, from basic to advanced, to kill two birds with one stone: to teach models to classify the two datasets and to check which prompt engineering techniques work better and are easier to apply. Prompts “competed” with each other — the best prompt at each stage was used as a starting point for the next one.
To avoid overfitting, we divided experimental datasets at a ratio of 9:1, where 0.1 of a dataset was used for selecting the best prompt for a task, and the 0.9 of it was used for testing.
Stage 1 — Mining and manual design
A good basic approach is to adopt a (reliable) existing solution. Thanks to the recent boom in prompt engineering, there are multiple openly-accessible databases with recommended prompts for various problems. We picked PromptSource — one of the biggest open prompt bases, containing 170+ English datasets. For each classification task, we mined 10 prompts closest to the classification problem description.
- DS-I, Film Reviews, datasets from PromptSource used: glue, imdb, rotten_tomatoes, sst
- DS-II, Amazon “Shopping Queries Dataset”, datasets from PromptSource used: stsb_multi_mt, biosses
However, there is a high chance that a particular IT business problem is unique enough to have no template prompts in an open source, and this turned out to be the case with the Amazon “Shopping Queries Dataset” relevance classification task. To compensate, we manually designed another 10 prompts for each task.
Stage 2— Paraphrasing
Even though per-word prompt engineering is a costly approach when paying per token (like with the GPT APIs), it is worth using a simplified version. That’s why we paraphrased the best prompt from Stage 1 in 5 different new versions.
Stage 3 — Few-shot learning + instruction
GPTs are few-shot learners like us, so it might make sense to give a model of this family the same information that a human labeler gets to solve a task. It is common practice to add a few shots directly in the prompts. We took the best prompt from Stage 2 and added labeling instructions and 10 examples generated by our experts during ground truth labeling.
Since the order of shots in a prompt might affect the resulting quality, we tested all the possible permutations.
Here are the best prompts we got after all three stages.
DS-I, Film Reviews

DS-II, Amazon “Shopping Queries Dataset”

Answer engineering
When asking autoregressive models to perform task classification, you need to consider that a model answer might need mapping to a set of task labels. This mapping is as important as prompt engineering for high-quality results.
Film Reviews classification
GPT 3 turned out to be pretty poetic in classification of film reviews, providing the best answers in an engaging form like “I think this movie might be pleasant to watch because…” We created a mapper that assigned the “Positive” label for answers with positive-sounding words and the “Negative” label for answers with negative connotations.
Amazon search relevance classification
For the search relevance classification task, the closest prompts we could find were structured more like a regression task: Give the answer on a scale from 0–4, where 0 is “not similar at all” and 4 is “means the same thing”. GPT 3 and GPT 3.5 showed < 50% accuracy on prompts with this structure, but GPT 4 started showing reasonable results.
Obviously, there is no perfect mapping between “Complimentary”, “Substitute” and “Unjudgable” classes and the numbers in this question format. However, to make this prompt work, we mapped numbers to classes in favor of the model: 0 to “Irrelevant”/”Unjudgable”, 1–3 to “Substitute” or “Complimentary” and 4 to “Exact”.
For high coherency of results, we set the temperature parameter in GPTs to low values for “training” and “testing”.
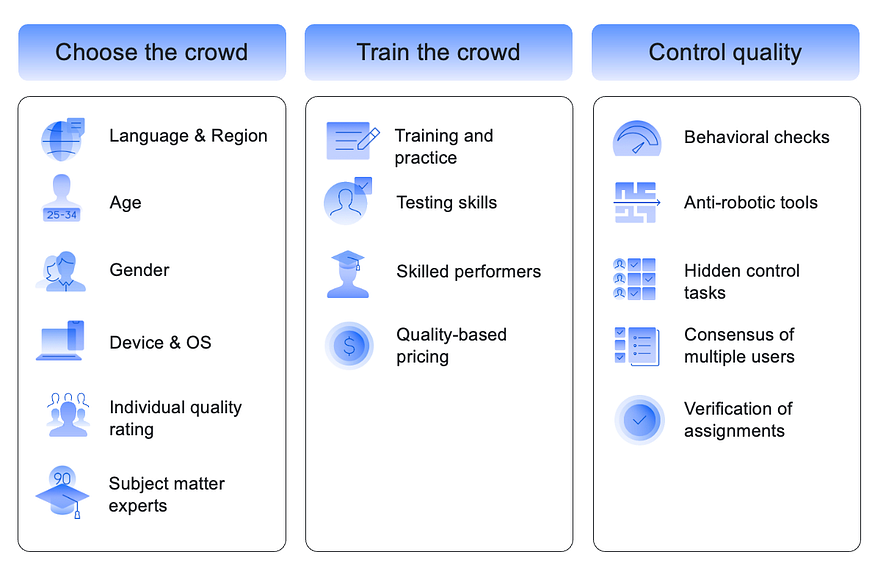
Crowd training
Training a crowd is similar to training a machine learning model: you need to develop an intuition for debugging and parameter selection for each particular task. The image below summarizes the best crowdsourcing practices that we developed at Toloka and applied in experiments.
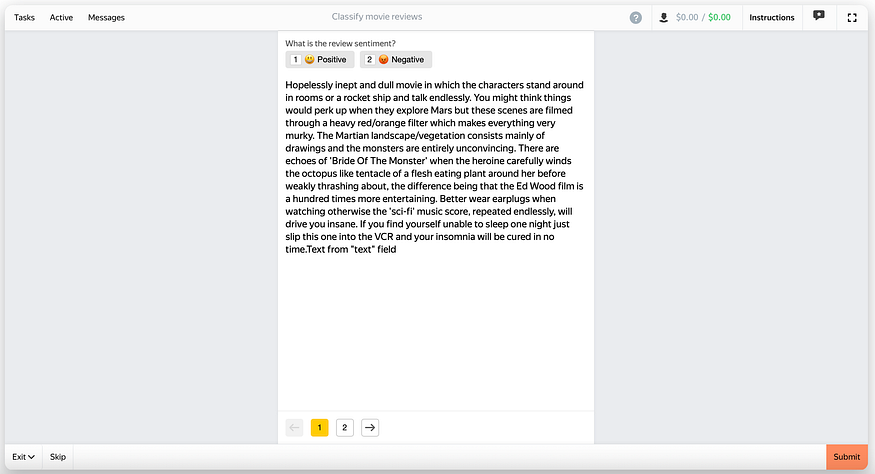
Film Reviews classification project
Labeling interface
Project configuration
- Tolokers must pass an English language test
- Training (instructions and 10 examples from experts)
- Dynamic pricing
- Overlap of 5 responses per item
- Automatic bans for people who submitted responses too fast or skipped too many tasks
- Control quality on hidden tasks with a ban for < 80% accuracy
Amazon search relevance classification project
Labeling interface
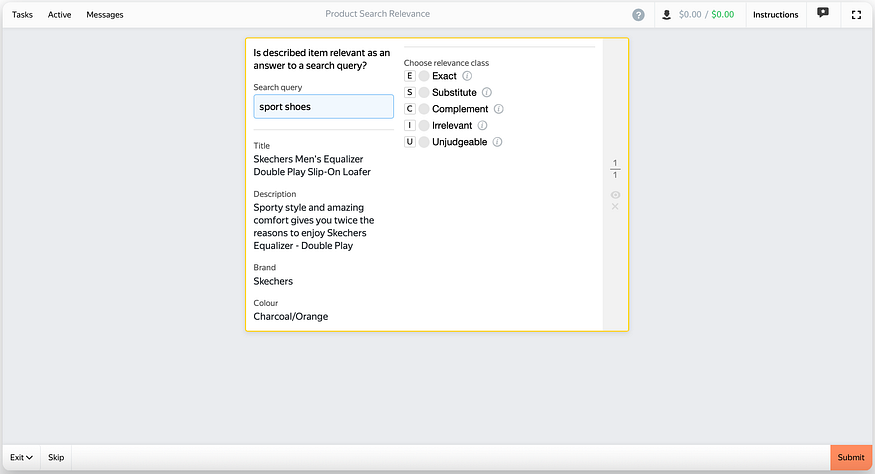
Project configuration
- Tolokers must pass an English language test
- Training (instructions) + Exam (10 examples from experts, ≥ 80% accuracy required to pass)
- Dynamic pricing
- Dynamic overlap of 2 + 2 + 1 based on labeling accuracy in hidden tasks
- Automatic bans for people who submitted responses too fast
- Control quality on hidden tasks with a ban for < 80% accuracy
Comparison
Metrics
Our goal was to use metrics that reflect a real-life setting. So we chose accuracy (along with balanced accuracy to check how class distribution affects results).
Results
Results for models were calculated using the best prompt identified after three prompt engineering stages.
Film Reviews classification: GPTs vs crowd
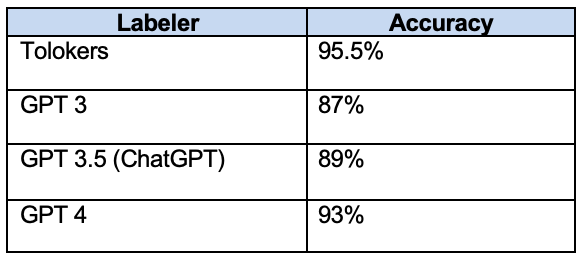
Calculating balanced accuracy is excessive here because we have a balanced binary classification task.
Adding a few-shot prompt wasn’t necessary because the accuracy of GPT 4 was very close to the accuracy of Tolokers (and it would have made the experiment much more expensive).
Amazon search relevance classification: GPTs vs crowd
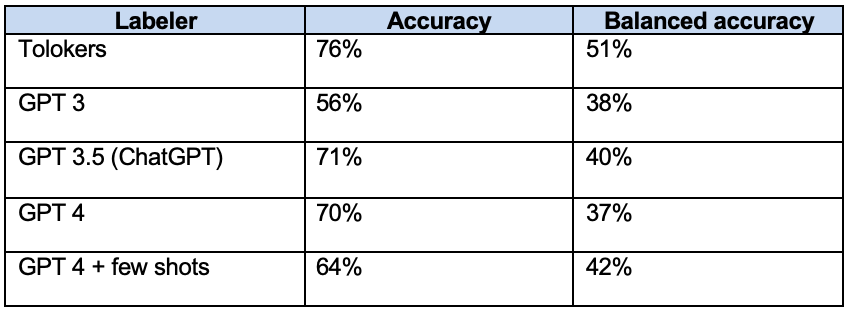
Accuracy for ChatGPT and GPT 4 does not show a statistically significant difference.
Discussion of results
Surprisingly, we discovered that the addition of few-shot prompts had a negative effect on accuracy. On the one hand, balanced accuracy improved, which is also an important metric for DS-II classification because it reflects the ability of a classifier to predict complex “Substitute” and “Complimentary” classes in addition to the more binary “Exact” and “Irrelevant” classes. On the other hand, it is counter-intuitive that additional information causes the model to degrade on one of the “easier” classes. We would like to look into this more in further experiments.
In general, we came away with several key takeaways:
- For simple binary classification tasks, both crowdsourcing and the GPT 4 model perform well. When it comes to harder problems, models are less stable.
- Regarding production classification tasks that experience data drift and domain shift, crowdsourcing looks like a much better approach because it is faster and free to retrain. With a classifier, any changes to the instructions require additional training and calibration.
- A low-quality threshold in tasks can be controlled transparently in crowdsourcing projects with filters on labeler skills.
Future work
Data drift & domain shift
We want to thoroughly check how domain shift and data drift affect crowdsourcing-based and GPT-based classifiers. In fields such as e-commerce and ad moderation, shifts and drifts tend to occur monthly or weekly. This is a crucial aspect to consider when selecting a classification tool for an IT business.
Low-resource languages
It would also be interesting to check how well GPTs perform the same tasks in languages other than English — especially low-resource languages that are available in crowdsourcing solutions.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


