



Artificial Intelligence to Detect Hate Speech related Sinhala comments in Social Media
Last Updated on November 15, 2020 by Editorial Team
Author(s): Santhoopa Jayawardhana
Deep Learning
Using Deep learning models to detect Sinhala hate speech on social media
Social Media has enabled us to share information in real-time. With the emerging digital culture, social media usage is constantly increasing. According to statistics, social media usage in Sri Lanka is around 6.4 million, which is around 30% of the population. Hate speech on social media like abusive, insulting, and hateful comments has resulted in an increase in violence in society. Therefore a mechanism is needed to detect hate speech in the Sinhala Language on Social Media platforms.
Deep learning is an Artificial Intelligence (AI) function that imitates the functionality of the human brain. Deep learning techniques have become very popular for solving complex problems. With the help of these techniques, it is possible to detect Sinhala hate speech on social media platforms. Deep Learning techniques like Long Short-Term Memory(LSTM) can be used for Natural Language Processing(NLP) applications like hate speech detection. LSTM is a specialized neural network architecture that can capture long-range dependencies in sequential data like text. LSTM can have memory about previous inputs for extended time durations. There are 3 gates in an LSTM cell (Input, output, and Forget gates). Memory manipulations in LSTM are done using these gates. Long short-term memory (LSTM) utilizes gates to control the gradient propagation in the recurrent network’s memory.
The semantic meaning of social media posts is very important to determine if it is a hate speech related comment. To capture semantic meanings, word embeddings techniques like FastText can be used. When using word embedding, each word is reprinted in a vector space. These word vectors capture hidden information about a language, like word analogies or semantic. Hence it can be used to improve the performance of text classifiers. FateText is an extension to the Word2Vec proposed by Facebook. They have already published trained FastText word embedding in the Sinhala Language. (https://fasttext.cc/docs/en/crawl-vectors.html. These pre-trained word embedding can be used for feature extraction.
In this article, I will show how the LSTM algorithm with Sinhala word embeddings can be used to detect Sinhalese hate speech related comments on social media platforms. Tensorflow is used to implement the deep learning model.
Step 1: Loading and Splitting the dataset
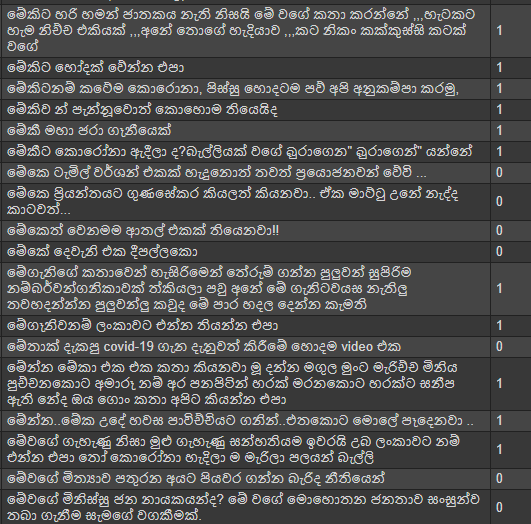
As the data source to train the deep learning model, the Sinhala Unicode Hate Speech dataset (6345 Facebook comments) published in Kaggle is used. (https://www.kaggle.com/sahanjayasuriya/sinhala-unicode-hate-speech)
First, the dataset is loaded and split as 6000 for the model training phase and 345 for the model evaluation phase. The following is a sample of the dataset.
Step 2: Preprocessing
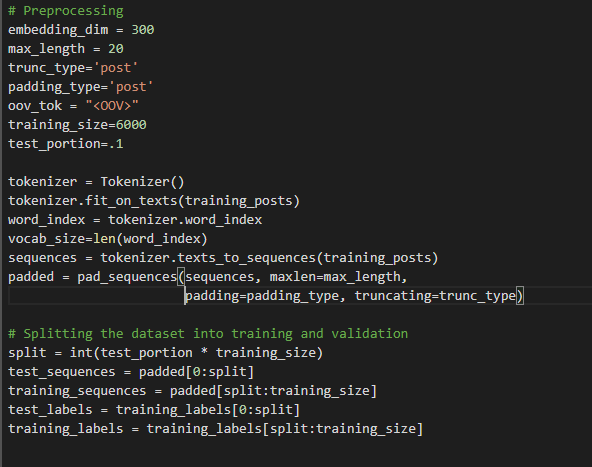
During the preprocessing stage, facebook comments in Sinhala are preprocessed using Tokenization (Breaking comments into word tokens) and Padding. Dataset of 6000 comments is further divided as training and validation split (90% for training and 10% validation). Sinhala word vocabulary is also created using the tokenizer.
Step 3: FastText word vectors (Feature Representation)
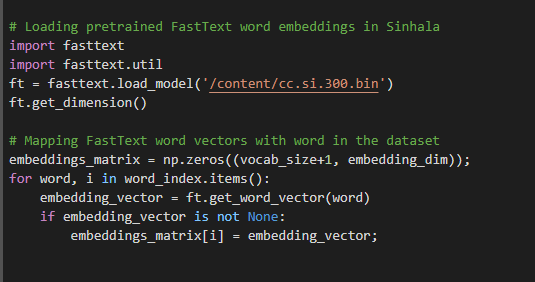
FastText word embedding is used as the feature extraction technique. The next step is loading the pre-trained FastText word embedding in Sinhala Language and mapping the created word vocabulary with the word vectors. Pre-trained FastText Sinhala word embeddings can be found at: https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.si.300.vec.gz
Step 4: Training the model using the LSTM algorithm
The next stage is building the deep learning model. LSTM, which is a specialized Recurrent Neural Network (RNN) architecture, is used to build the model. The first layer of the model is the word embedding layer. For this layer, a pre-trained Sinhala word embedding of 300 dimensions is used. The next layer is the LSTM layers consisting of 128 cells. As the final layer, a dense layer with a sigmoid activation function is used. Binary cross-entropy is used as the loss function to training the model.
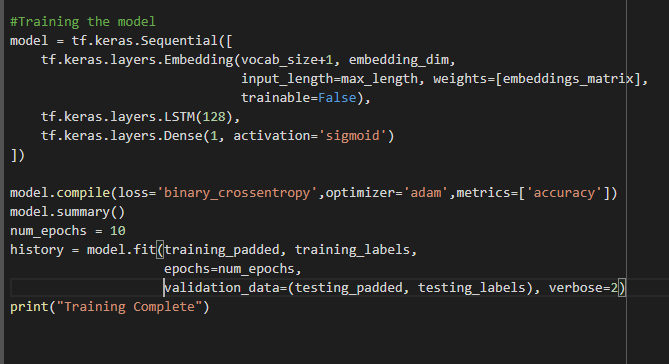
The model is trained for 10 epochs, and at the end of the training, a training accuracy of 88.9% and a validation accuracy of 87.7% is achieved. This implies that the trained deep learning model is capable of accurately detecting hate speech comments in the Sinhala language.
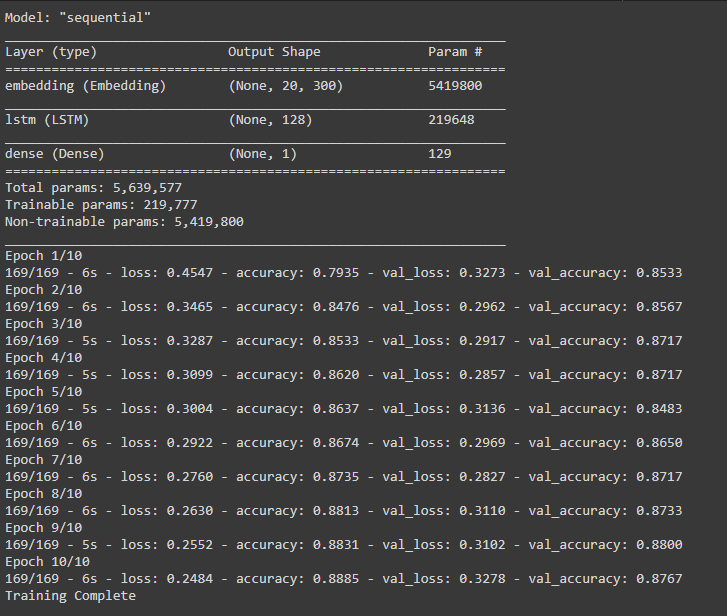
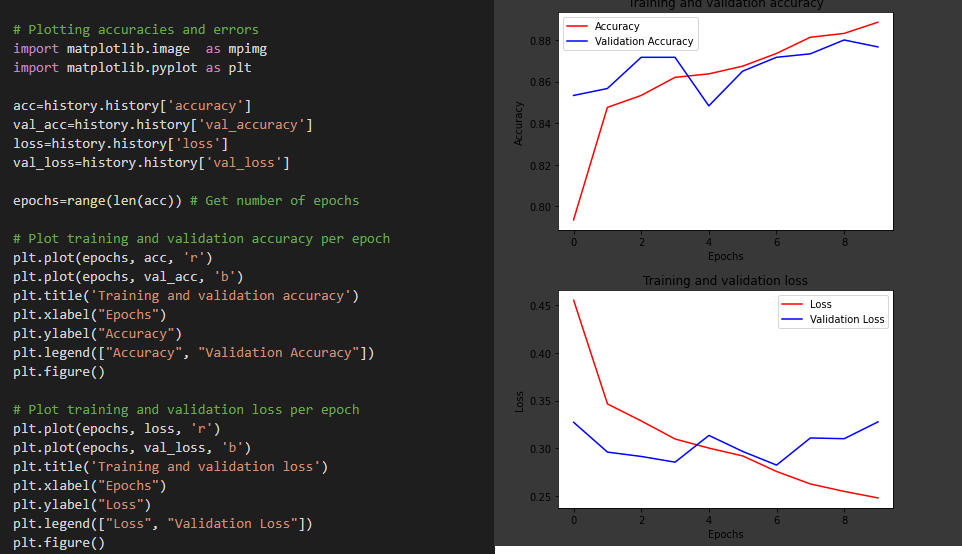
Next, the accuracies and losses during the training phase are plotted using a graph. Matplotlib is used for this.
Step 5: Model Evaluation
Next, the model is evaluated using the evaluation dataset of 345 Facebook comments. The performance of the model is evaluated using metrics precision, recall, F1-score, and accuracy. The trained model has performed accurately on the evaluation dataset with an accuracy of 88%.
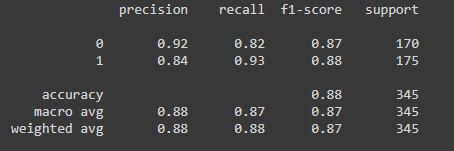
To further evaluate the performance of the model sample is tested with sample text.
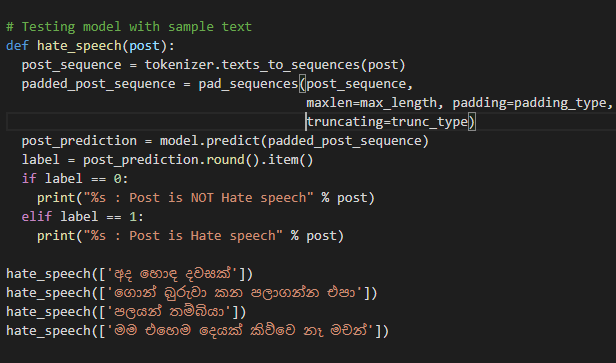

The trained deep learning model is capable of accurately distinguishing hate speech comments in the Sinhala language. This implies the efficiency of LSTM when determining complex classification boundaries and word embedding techniques when capturing the semantics of words. From the results, it can be concluded that the trained deep learning model is an accurate approach to detect hate speech related social media comments in the Sinhala Language.
Complete source code is available at: https://github.com/santhoopa/hate_speech_sinhala
References
https://www.kaggle.com/sahanjayasuriya/sinhala-unicode-hate-speech
https://fasttext.cc/docs/en/crawl-vectors.html
https://www.researchgate.net/publication/2562741_Long_Short-Term_Memory_in_Recurrent_Neural_Networks
https://www.investopedia.com/terms/d/deep-learning.asp
https://datareportal.com/reports/digital-2020-sri-lanka
Artificial Intelligence to Detect Hate Speech related Sinhala comments in Social Media was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts



")
Recent Posts




")

