


")
Synopsis: Taming Transformers for High-Resolution Image Synthesis (VQ-GAN & Transformer)
Last Updated on March 24, 2022 by Editorial Team
Author(s): ROHAN WADHAWAN
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
VQ-GAN & Transformer — Taming Transformers for High-Resolution Image Synthesis: Synopsis
Summary
This post summarizes the work “Taming Transformers for High-Resolution Image Synthesis” by Patrick Esser, Robin Rombach, and Björn Ommer. It highlights the key take-home messages, the scope of improvement, and the applications of this work. The article is helpful for readers interested to understand how state-of-the-art neural architectures and techniques like Convolutional Neural Network (CNN)[1], Transformers[2], Autoencoder[3], GAN[4], and vector quantized codebook[5] can be combined for image synthesis, without diving deep into each of them. The mind map demonstrated below serves as a pre-requisite knowledge pyramid that one must possess or subsequently attain to understand the techniques defined in the discussed paper and similar methods that are transforming the field of generative AI.
The article is structured as follows:
- Problem Statement
- Intuition behind the Methodology
- Conclusions
- Opportunities
- Applications
- References
Problem Statement
To demonstrate the effectiveness of combining the inductive bias of CNNs with the expressivity of transformers for synthesizing high-resolution and perceptually rich images in an unconditional or controlled manner.
The intuition behind the Methodology
To understand how taming transformers can facilitate high-resolution synthesis, we need to start from the beginning, Vector Quantized — Variational Autoencoders (VQ-VAE)[5]. VQ-VAE is a variational autoencoder network that encodes image information into a discrete latent space. It maps the latent vector produced by the encoder to a vector, which is closest to it and belongs to a fixed list of vectors, known as the codebook of vectors. The degree of closeness is calculated using measures like Euclidean distance (𝘓₂ norm). To ensure diversity of generated output, the encoder outputs a grid of latent vectors rather than a single one, and each latent vector is mapped to one of the vectors belonging to the same codebook. This process is termed quantization of the latent space. Consequently, we obtain a 2D grid of whole numbers representing the latent space, where each grid value corresponds to the index of the vector within the codebook list. Finally, the vectors selected post quantization of the latent space are fed to the decoder to generate the output image. This is demonstrated in the following architecture diagram:
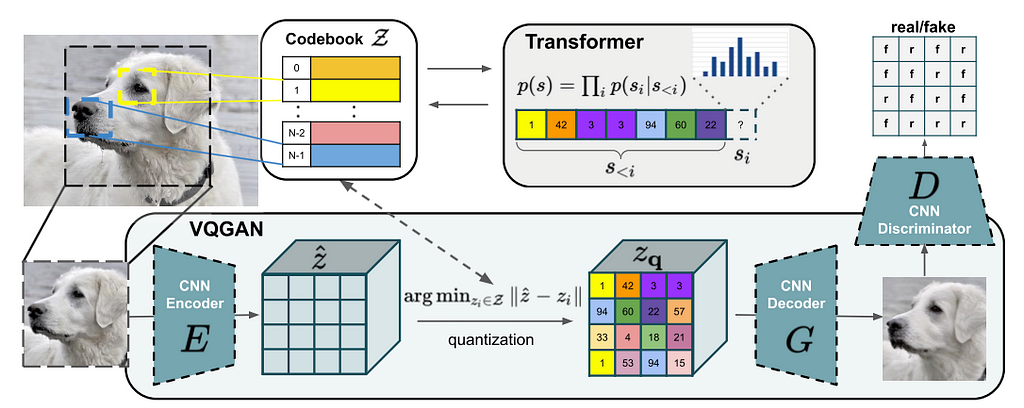
Mathematically, the VQ-VAE model simulates the image reconstruction problem during training. The encoder sub-network simulates a function E(x) that outputs a grid of latent vectors for an image x. Each latent vector in the grid undergoes quantization using a function q(ẑ), which maps it to a vector (ẑ) from the available codebook of vectors. Finally, the decoder simulates a function G(zᵩ) that reconstructs the image (x′) from the grid of codebook vectors (zᵩ). (here ᵩ = q)
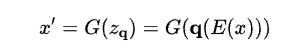
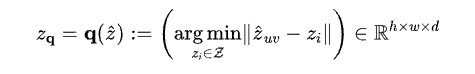
where ẑᵤᵥ represents encoder predicted latent vector at (u, v) position in the grid, zᵢ represents a codebook vector, h represents grid height, w represents grid, and 𝒹 is the dimension length of each codebook vector.
The VQ-VAE and the codebook vectors are jointly learned by optimizing the following objective function:
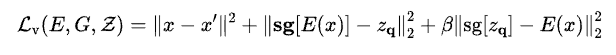
where 𝘓ᵥ is the vector quantized loss for training the model and the codebook together, the first term is the reconstruction loss (𝘓ᵣ), the second term, also know as codebook alignment loss, helps align codebook vectors to encoder outputs, and the third term, also know as commitment loss, helps in the inverse alignment, that is, encoder outputs to codebook vectors, whose importance to the overall loss is scaled by the tunable hyperparameter β. sg[] represents stop gradient, that is, gradient flow or weight updation does not happen through variable enclosed within []. For a detailed and intuitive understanding of these concepts, you can refer to these posts VAE and VQ-VAE.
Now comes the set of improvements to VQ-VAE proposed in the discussed paper. The 𝘓₂ reconstruction loss was replaced with the perceptual loss[6], and an adversarial training procedure with a patch-based discriminator [7] was introduced to differentiate between real and reconstructed images. This change ensured good perceptual quality at an increased compression rate. I will explain the relevance of compression while discussing how transformers help the image synthesis process. The authors named this approach Vector Quantized — Generative Adversarial Network (VQ-GAN). Following is the overall objective function:
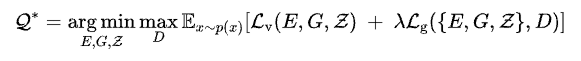
Here 𝘓g is the Generative Adversarial Network loss, λ is the adaptive weight given by the following equation, where 𝛿 is for numerical stability.
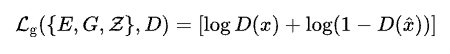
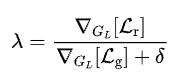
Let us digress for a moment and look at the VQ-GAN framework from a probabilistic perspective. We have a prior over the latent space p(z), the encoder approximates the posterior distribution of the latent p(z|x), and the decoder approximates the reconstruction from the latent space via the distribution p(x|z). To define the prior, we flatten the 2D grid of codebook vector indices that form the quantized latent space and obtain a sequence of indices s. Until now, a uniform prior was assumed over all the latent codes, making their selection at step i in the sequence equally likely and independent of previous steps. But this may not be true for a given dataset that the model is trying to learn. In other words, the distribution of latent codes should be learned from the data. This will have two benefits. Firstly, the data we generate by sampling latents from the new trained prior will represent the underlying dataset better. Secondly, if the distribution of latents is non-uniform, then the bits representing the sequence of latents can be further compressed by applying standard Huffman or arithmetic coding. This is the compression I had mentioned earlier in the post.
Learning the latent prior gives rise to an autoregressive problem. Recently, Transformers have become the go-to architecture for autoregressive and sequential modeling tasks, outperforming their convolution counterparts (CNNs) for low-resolution image synthesis. The working of the transformer has been explained well in this blog using an NLP example. Traditionally, the image transformers deal with discrete values and perform sequential learning at a pixel level, whose cost scales quadratically with image resolution. Although they are highly suited for high-resolution image synthesis that requires a model to learn local realism and understand global composition, the computational cost has been the inhibitory factor. However, by representing an image as a sequence of codebook vector indices s, the use of the transformer model becomes computationally tractable. After choosing some ordering of the indices in s, learning the prior can be formulated as an autoregressive next-index prediction (sᵢ) problem.
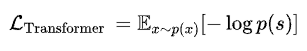
where p(s) is the likelihood of full image representation,
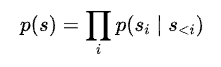
Lastly, the attention mechanism, which is the essence of the transformer’s architecture, sets a computational upper limit to the length of the sequence s input to the transformer. To mitigate this issue and generate images in the megapixel regime, the transformer is applied on image patches with the help of a sliding window approach, as shown in the figure below. VQ-GAN ensures that the available context is still sufficient to faithfully model images, as long as the dataset’s statistics are approximately spatially invariant or spatial conditioning information is available.

Conclusions
- The proposed approach enables modeling image constituents via a CNN architecture and their compositions via the versatile and generalizable transformer architecture, thereby tapping into the full potential of their complementary strengths for image synthesis.
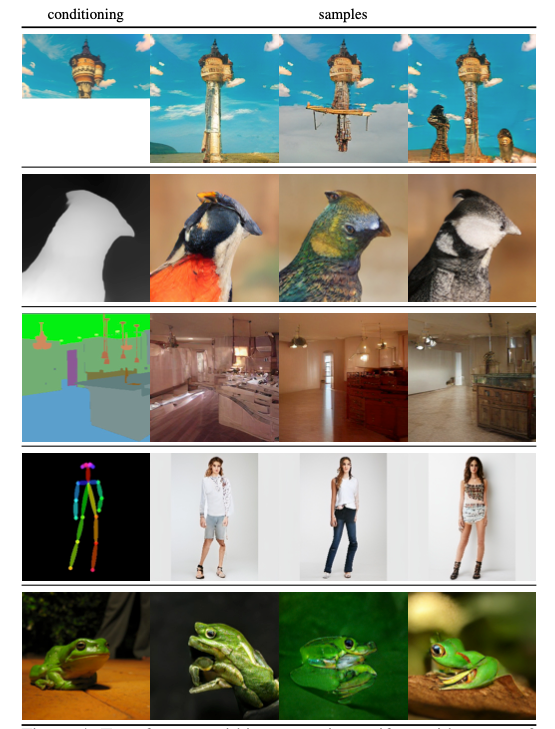
- It outperforms state-of-the-art convolutional approaches for high-resolution image synthesis and is near state-of-the-art for conditional generation tasks. Some results are shown below,

- VQ-GAN outperforms the closest comparable network VQ-VAE-2[8] while providing significantly more compression that helps reduce computational complexity.
Opportunities
- Methods to enhance this approach’s real-time usability, as vanilla transformer-based techniques are computationally expensive.
- Extending the given procedure for multi-modal image synthesis, like text-to-image generation.
Applications
- High-resolution image synthesis
- Semantic image synthesis, which is conditioned on semantic segmentation mask.
- Structure-to-image synthesis, which is conditioned on either depth or edge information.
- Pose-guided synthesis, which is conditioned on Pose information of human subjects, like fashion modeling.
- Stochastic Super-resolution synthesis, which is conditioned on low-resolution images
- Class-conditional synthesis, is conditioned on the single index value that defines the class of interest (object, animal, human, etc).
References
- Y. LeCun et al., “Handwritten digit recognition with a back-propagation network,” in Proc. Adv. Neural Inf. Process. Syst., 1990, pp. 396–404.
- A. Vaswani, N. Shazeer, N. Parmar, J. Uszko- reit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is All you Need,” in Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems, NeurIPS, 2017.
- G. Hinton, and R. Salakhutdinov. “Reducing the dimensionality of data with neural networks.” science 313.5786 (2006): 504–507.
- I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,” in Advances in neural information processing systems, 2014, pp. 2672– 2680.
- A. Oord, O. Vinyals, K. Kavukcuoglu. “Neural discrete representation learning.” Advances in neural information processing systems 30 (2017).
- J. Johnson, A. Alexandre, and F. Li. “Perceptual losses for real-time style transfer and super-resolution.” European conference on computer vision. Springer, Cham, 2016.
- P. Isola, J. Zhu, T. Zhou, and A. Efros, “Image-to-Image Translation with Conditional Adversarial Networks,” In 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR, 2017.
- A. Razavi, A. Oord, and O. Vinyals, “Generating diverse high-fidelity images with vq-vae-2,” 2019.
Thank you for reading this article! If you feel this post added a bit to your exabyte of knowledge, please show your appreciation by clicking on the clap icon and sharing it with whomsoever you think might benefit from this. Leave a comment below if you have any questions or find errors that might have slipped in.
Follow me in my journey of developing a Mental Map of AI research and its impact, get to know more about me at www.rohanwadhawan.com, and reach out to me on LinkedIn!
Synopsis: Taming Transformers for High-Resolution Image Synthesis (VQ-GAN & Transformer) was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.




Recent Posts
")



")


