



Which NLP Task Does NOT Benefit From Pre-trained Language Models?
Last Updated on August 29, 2022 by Editorial Team
Author(s): Nate Bush
There is such a long history of pre-trained general language representation models with a massive impact that we take for granted that they are a completely 100% necessary foundation for all NLP tasks. There were two separate step function innovations that pushed the accuracy of all NLP tasks forward: (1) statistical language models like Word2Vec and GloVe and, more recently, (2) neural language models like BERT, ELMo, and recently BLOOM. Inserting pre-trained neural language models at the beginning of a modeling workflow is almost guaranteed to increase performance, but there is at least one situation where it does not.
Named Entity Recognition (NER)
Look no further than the original BERT paper titled “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding” to see a detailed analysis of how pre-trained BERT embeddings improve NER performance in section 5. The BERT diagram below shows a typical machine learning workflow for exploiting any language model for general NLP tasks.
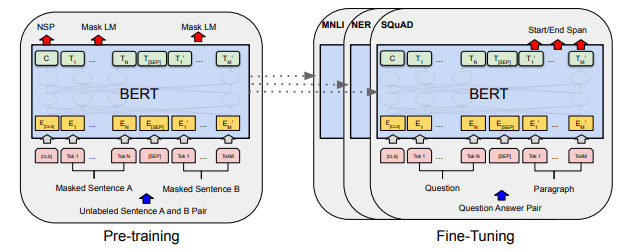
The papers also show significant improvement on Question Answering (QA) evaluated against SQUAD, and a hodgepodge of natural language understanding (NLU) tasks called GLUE.
Entity Disambiguation (ED)
The global ED task also achieved new state-of-the-art results across multiple datasets using BERT. See the related work section of this “Global Entity Disambiguation with BERT” for a rundown of various workflows for applying BERT as a preprocessing step for ED.
Extractive Summarization (ES)
A simple variant of BERT achieving once again state-of-the-art performance on several ES datasets can be found in “Fine-tune BERT for Extractive Summarization”.
Sentiment Analysis (SA)
Once again, sentiment analysis is equally graced by the existence of BERT language models in the recent paper “BERT for Sentiment Analysis: Pre-trained and Fine-Tuned Alternatives”.
I could keep going… but I won’t. The glory of pre-trained language models is obvious. We only need to stand on the shoulders of giants who spent countless hours preparing massive corpora of data, deploying expensive GPUs to pre-train these models for us. These models aren’t a silver bullet, though.
The main natural language task that has failed to show consistent performance improvements from sesame street and friends is Neural Machine Translation (NMT).
NMT usually doesn’t benefit from Pre-trained language models
It’s difficult to find papers that discuss why it doesn’t work, and it’s easy to imagine why. Writing papers about what doesn’t work is not very popular… and unlikely to gain recognition or be frequently quoted. Ah shoot — so why am I writing this article again?
I found one paper that covered this topic: “When and Why are Pre-trained Word Embeddings Useful for Neural Machine Translation?” and it was an interesting read. They break NMT down into two categories of tasks:
- NMT for low-resource languages
- NMT for high-resource languages
What they mean by low/high resource language is in reference to the size of the parallel corpus that can be obtained. For the world’s most popular languages, it can be easy to find open-source large parallel corpora online. The largest such repository is OPUS, the Open Parallel Corpus, which is an amazing resource for any machine learning engineer looking to train NMT models.
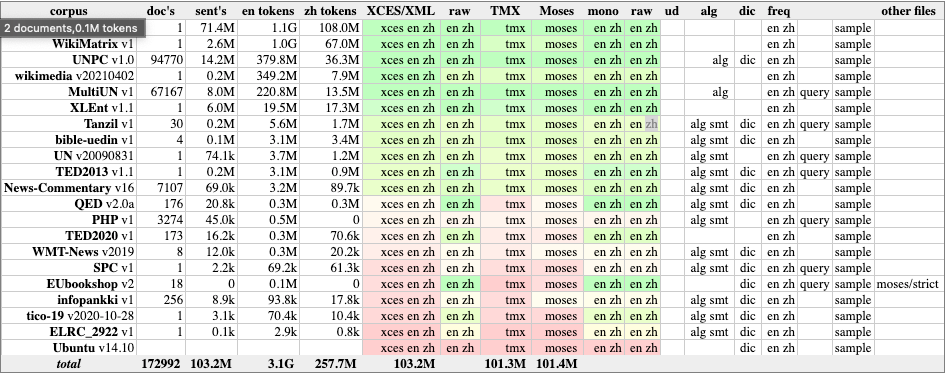
The image above shows that the open parallel corpus between English and Chinese has 103 million parallel sentences or 172K parallel documents. But what if you wanted to train an NMT model to translate Farsi to Chinese? In that case, you only have 6 million parallel sentences from 517 documents to work with.

As you might expect, low-resource languages benefit from pre-trained language models and are able to achieve better performance when fine-tuning the embeddings while back-propagating errors through the NMT network. Surprisingly, however, for high-resource languages, the effect of using pre-trained language models as a pre-processing step before NMT model training does NOT result in performance gains.
It’s critical to point out that language models only make sense to use for machine translation if they are trained on both source and target language (for example, Chinese and English in the first example). These are commonly referred to as multilingual embedding models or language agnostic embeddings. They are able to achieve the interesting result that words in multiple languages achieve similar vector representations in the embedding space.
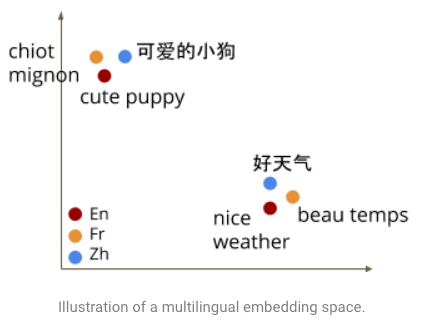
But how are multilingual language models trained? Turns out they are trained over the exact same data as NMT: a massive parallel corpus between the source and target language. So, is there a fundamental shortcoming to language models that prevent them from being effective for this NLP task? No, language models use the same data as NMT models, and they are both built from the same powerhouse building block: the transformer.
To review, language models and NMT are trained over the same data, using very similar fundamental architectures. When you consider the similarities, there isn’t really anything new that the language models are bringing to the table so it shouldn’t be surprising to you that BERT, ELMo, ERNIE, and our other sesame street friends aren’t appearing in NMT papers touting huge breakthroughs in model performance.
A skeptical reader will likely be able to poke holes in this explanation. There are certainly devisable use cases were training an LM on a large parallel corpus but then training BERT + NMT workflow on a much smaller corpus would intuitively result in performance gains. But I think it’s unlikely that a serious deep learning engineer would attempt to build an NMT model without all available data at their disposal… outside of purely academic curiosities.
I tip-toed over some hairy details, so I recommend reading the original paper if you’re interested!
I hope you enjoyed this short exploration into the intuition behind what makes NLP algorithms successful. Please like, share, and follow for more deep learning knowledge.
Which NLP Task Does NOT Benefit From Pre-trained Language Models? was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts



Recent Posts




")

