



Feature Engineering for NLP
Last Updated on November 18, 2020 by Editorial Team
Author(s): Bala Priya C
Natural Language Processing
Part 2 of the 6 part technical series on NLP
Part 1 of the series covered the introductory aspects of NLP, techniques for text pre-processing and basic EDA to understand certain details about the text corpus. This part covers linguistic aspects such as Syntax, Semantics, POS tagging, Named Entity Recognition(NER) and N-grams for language modeling.
Outline
- Understanding Syntax & Semantics
- Techniques to understand text
-- POS tagging
-- Understanding Entity Parsing
-- Named Entity Recognition(NER)
-- Understanding N-grams
As we know, one of the key challenges in NLP is the inherent complexity in processing natural language; understanding the grammar and context(syntax and semantics), resolving ambiguity(disambiguation), co-reference resolution, etc.
Understanding Syntax and Semantics
Syntactic and Semantic Analysis are fundamental techniques to understand any natural language. Syntax refers to the set of rules specific to the language's grammatical structure, while Semantics refers to the meaning conveyed. Therefore, semantic analysis refers to the process of understanding the meaning and interpretation of words and sentence structure.
Sentence that is syntactically correct need not always be semantically correct!
The following picture shows one such example where a person responds to “Call me a cab!” with “OK, you’re a cab!” clearly misinterpreting the context, which is not meaningful. This example shows how a syntactically correct sentence (“OK, you’re a cab!” is grammatically perfect!🙂) fails to make sense.

Techniques to understand a text
POS Tagging
POS Tagging, also called grammatical-tagging or word category disambiguation, refers to the process of marking a word in the corpus as corresponding to a particular part of speech, based on both its definition and context. The POS tags from the Penn Treebank project, which are widely used in practice, can be found in the below link.
Here’s an example of a simple POS-tagged sentence, following the convention from the Penn Treebank project.

POS Tags: PRP– Personal pronoun; VBZ– Verb,3rd person, singular, present; NNS-Noun plural, IN– preposition; DT– Determiner, NN– Noun Singular
Why is POS Tagging important?
- POS tagging is important for word sense disambiguation
- For example, consider the sentence “Time flies like an arrow”; As illustrated below, the syntactic ambiguity gives rise to several possible interpretations out of which only one is semantically meaningful.
- POS tagging is of importance in applications such as machine translation and information retrieval.
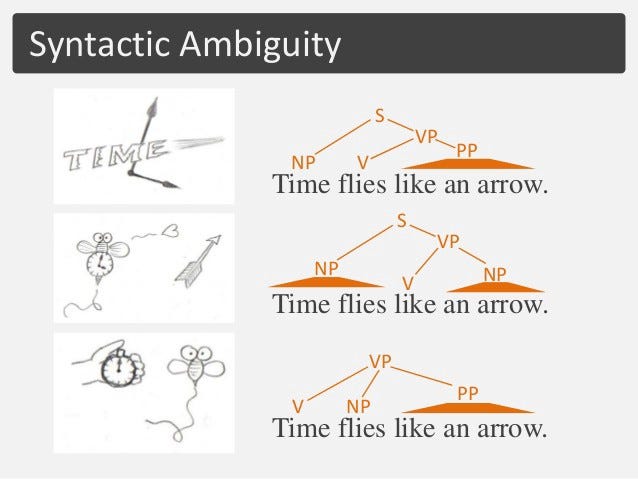
Challenges in POS tagging: Due to the inherent ambiguity in language, POS tags are not generic.
“The same word may take different tags in different sentences depending on different contexts.”
Examples:
- She saw a bear (bear-Noun); Your efforts will bear fruits (bear-Verb)
- Where is the trash can? (can-Noun) ; I can do better! (can-Modal verb)
There are several approaches to POS tagging, such as Rule-based approaches, Probabilistic (Stochastic) POS tagging using Hidden Markov Models.
Shallow Parsing/Chunking
Shallow parsing or Chunking is the process of dividing a text into syntactically related groups. It involves dividing the text into a non-overlapping contiguous subset of tokens. Shallow parsing segments and labels a multi-token sequence. It’s important in information extraction from text to create meaningful subcomponents.
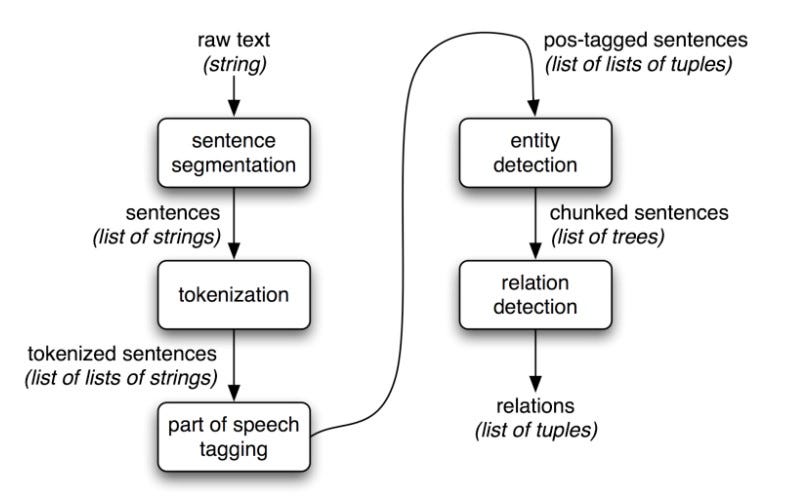
We start with raw text, clean it (text pre-processing), identify the part of speech of the words (POS tagging), identify entities within the text (Shallow parsing/chunking), and finally identify relationships between the entities. Hence, shallow parsing is important to effectively parse dependencies between entities. Here’s a simple illustration of how a chunked tree helps us understand dependencies between entities.

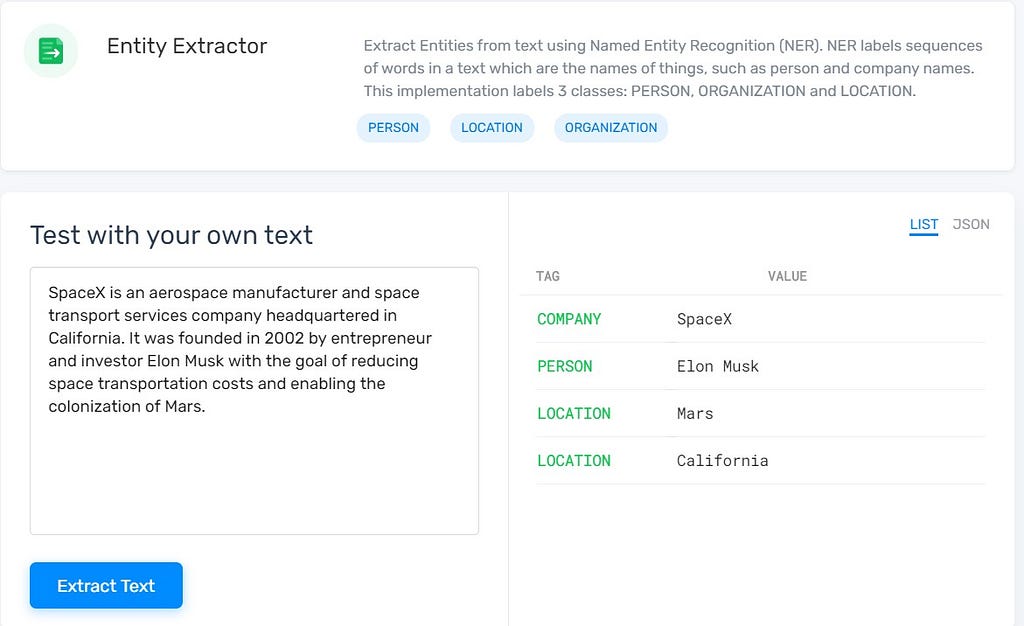
Named Entity Recognition(NER)
The goal of Named Entity Recognition(NER) is the process of automatically finding names of people, places, and organizations in text across many languages. NER is used in information extraction to identify and extract named entities in predefined classes. Named Entities in a text are those entities that are often more informative and contextually relevant.
The key steps involved include
- Identifying the named entity
- Extracting the named entity
- Categorizing the named entity into tags such as PERSON, ORGANIZATION, LOCATION, etc.
Understanding N-Grams
N-Grams is a useful language model aimed at finding probability distributions over word sequences. N-Gram essentially means a sequence of N words. Consider a simple example sentence, “This is Big Data AI Book,” whose unigrams, bigrams, and trigrams are shown below.

Understanding the Math
- P(w|h): Probability of word w, given some history h
- Example: P(the| today the sky is so clear that)
- w: the
- h: today, the sky is so clear that
Approach 1: Relative Frequency Count
Step 1: Take a text corpus
Step 2: Count the number of times 'today the sky is so clear that' appears
Step 3: Count the number of times it is followed by 'the'
P(the|today the sky is so clear that) =
Count(today the sky is so clear that the)/
Count(today the sky is so clear that)
# In essence, we seek to answer the question, Out of the N times we saw the history h, how many times did the word w follow it?
Disadvantages of the approach:
- When the size of the text corpus is large, then this approach has to traverse the entire corpus.
- Not scalable and is clearly suboptimal in performance.
Approach 2: Bigram Model
Bigram model approximates the probability of a word given all the previous words by using only the conditional probability of the preceding word. In the above example that we considered, w_(n-1)=that
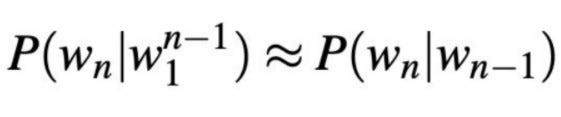
This assumption that the probability of occurrence of a word depends only on the preceding word (Markov Assumption) is quite strong; In general, an N-grams model assumes dependence on the preceding (N-1) words. In practice, this N is a hyperparameter that we can play around with to check which N optimizes model performance on the specific task, say sentiment analysis, text classification, etc.😊
Putting it all together, we’ve covered the differences between syntactic and semantic analysis, importance of POS tagging, Named Entity Recognition(NER) and chunking in text analysis and briefly looked at the concept of N-grams for language modeling.
References
Below is the link to the Google Colab notebook that explains the implementation of POS Tagging, Parsing, and Named Entity Recognition(NER) on the ‘All the News’ dataset from kaggle that contains 143,000 articles from 15 publications.
- WomenWhoCode/WWCodeDataScience
- All the news
- Understanding Word N-grams and N-gram Probability in Natural Language Processing
- An introduction to part-of-speech tagging and the Hidden Markov Model
Feature Engineering for NLP was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts



Recent Posts






")