



Conditional Story Generation — Part 1
Last Updated on December 27, 2020 by Editorial Team
Author(s): Francesco Fumagalli
Natural Language Processing
Conditional Story Generation — Part 1
Helping story writers with text generation
Natural Language Processing (NLP) is a wonderfully complex field, composed of two main branches: Natural Language Understanding (NLU) and Natural Language Generation (NLG). If we were talking about a kid learning English, we’d simply call them reading and writing. It’s an exciting time to work in NLP: the introduction of Transformer models in 2017 drastically improved performances, and the release of the seemingly all-powerful GPT-3 earlier this year has brought along a wave of excitement. We’ll talk more about those later.
First, a simple but powerful realization: writing is not easy. Authors often get stuck trying to find that perfect combination of words that slips their mind, reading, again and again, the same sentence until the words themselves stop making sense; or just run out of ideas, writing like a machine gun until something gets stuck and leaves us staring at the blank paper, as if we had suddenly forgotten what we wanted to say, wondering how could words flow so effortlessly just a minute ago.
Software like Grammarly takes care of the grammatical aspect; we want to help the creative endeavor, offer inspiration from the countless stories that have already been written, give that hint that helps the writer’s idea bloom into a beautiful tale.
“We owe it to each other to tell stories” ~Neil Gaiman
To develop something truly useful, we first had to research, study, and understand what writing a story means and what it entails. I’m writing this article to share with you what we’ve learned so far, to help others interested in following our footsteps, and in giving a starting point for those interested in navigating the vast oceans of Natural Language Generation and Story Writing without getting lost at sea.
To see the work we’ve done on a related topic, helping children's books become more immersive by personalizing illustrations, check out our previous article.
A brief history of Natural Language Generation: from n-grams to Transformers
(despite my best efforts to make it reader-friendly, this part is a bit technical — if you don’t care about how it works or want to see the results first, feel free to jump straight to the “Magic in Action” section at the end)
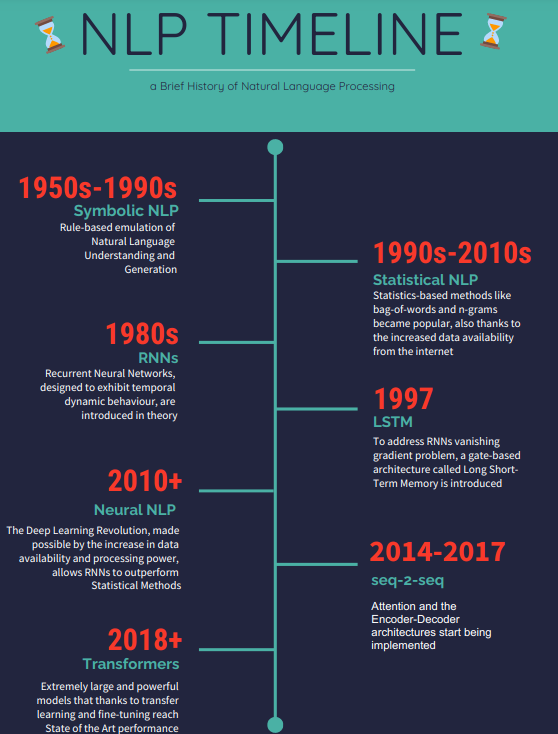
How does a model even generate text? A model must be trained first, and to be trained, it needs a vast amount of examples (corpus) to learn from. Commonly used corpora for models that support unsupervised training are BookCorpus (a dataset consisting of 11,038 unpublished books from 16 different genres), articles from Wikipedia, and web crawls from the web such as CommonCrawl. It takes days or sometimes even weeks, even with vast amounts of computational power, to learn the dependencies among words, the statistical distribution of probabilities that link words together and gives them sense as a whole. On top of that, the “reasoning” of the resulting algorithm will be based on the text it was given, so it’s very important to choose it carefully, as the same model trained on two different corpora of text will end up giving very different results. But let’s not get ahead of ourselves and see how we got there.
Statistical Models
One of the simplest approaches to NLP, known as bag-of-words, leverages the number of occurrences of each word as features for text classification and other tasks. However, the number of words’ occurrences doesn’t retain other relevant information such as the position of each word in a sentence and its relation to other words. Thus it isn’t suitable for text generation.
N-gram models address this problem: instead of counting the occurrences of words, we count the occurrences of N sequential words. Once N-grams have been counted, generating text is just a simple statistical problem: given the latest N-1 words in a text, what’s the most likely next one? This can be applied iteratively until a full sentence, paragraph, or book is complete. Choosing a high number for N results in a more precise model, but also in a higher likelihood of just copying something someone else had written among the texts in the corpus.
n-grams example
Sentence: “Hello Medium readers”
1-grams: (Hello), (Medium), (readers)
2-grams: (Hello, Medium), (Medium, readers)
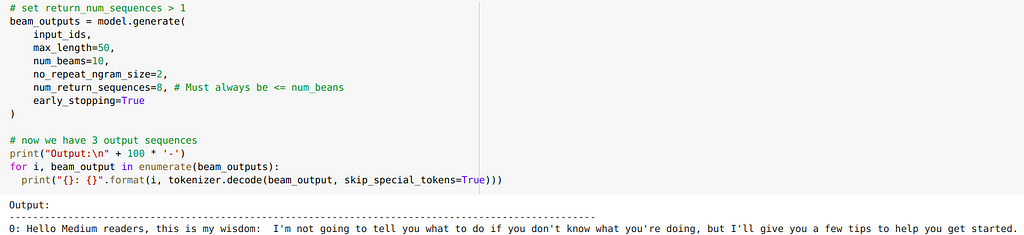
Choosing the following word can be done in a Greedy way (always take the most likely one) or via Sampling (the choice is made among the most likely ones according to the probability distribution). To generate a sentence, we can use one of those methods iteratively, but it often gives suboptimal results as the best sentence may not be just a sequence of best words. Ideally, we’d try every possible combination of words and find the best one, but it wouldn’t be time-efficient. A good in-between solution is Beam Search: multiple paths (the user can choose the number) among the most promising ones are explored simultaneously, and only at the end of the sentence the one with the highest score gets chosen, avoiding local minima.
This last approach seems particularly useful to present different possibilities to a human writer: either proposing new ideas he hadn’t considered before or suggesting alternative ways to express what he’s already written.
Deep Learning models: RNNs
The Deep Learning revolution over the last decade has made it possible to use Neural Network-based models, able to learn more complex dependencies among words than n-grams.
Back in the 1980s, “simple” Recurrent Neural Networks (programmers may think of them as “for” loops neural networks) were invented to take on the text and “remember” dependencies among words. However, it would take another 30 years before there were enough data and computational power available for them to outperform statistical methods. They present several limitations: gradients (fundamental for backpropagation, at the core of Deep Learning) vanish or explode on long sentences and documents, making the training very unstable.
To address this issue, Long Short Term Memory (and Gated Recurrent Units) were introduced in 1997, special kinds of RNNs that thanks to memory gates prevent the vanishing gradient problem, but still don’t really work for transfer learning (copying part of a model someone else has trained on another task, saving countless hours and resources in training), needing a labeled and specifically designed dataset for every task.
LSTMs were at the base of the Encoder-Decoder architecture used by Seq-2-Seq models, originally developed for Machine Translation, that took in a whole sentence and “encoded” all of it before “decoding” and choosing the output, resulting in more coherent and appreciable results.
Attention mechanisms were also invented, giving models a way to recognize which parts of the input sentence are most relevant and dependent upon each other.
Deep Learning models: Transformers
Building on both the Encoder-Decoder architecture and attention (often multi-head attention, running through attention several times in parallel), Transformers came out in 2017: a model that didn’t use RNNs’ recurrent sequential processing but a Positional Encoding instead to “reason” about the position of each word and calculating relevance scores (how connected words are to each other) with Attention, lending itself very naturally to parallelization (which meant models with tens of billions of parameters could be trained, such as T-NLG, GPT-3 and MegatronLM. A more in-depth explanation of Transformers can be found here).
Transformers’ key advantages are being easier to train and very compatible with Transfer Learning, whereas LSTMs are still superior when dealing with very long or infinite sequences of text or when for some reason, you can’t pre-train on a large corpus.
Alternative Approaches: GANs and VAEs
Generative Adversarial Networks (GANs) and Variational AutoEncoders (VAEs) have had tremendous success in the automatic generation of images, so why aren’t they also commonly used in Natural Language Generation? Creating GANs from RNNs posed a technical problem that had to do with the non-differentiability of the choice of the generated word and the consequent impossibility of backpropagating the gradients through the network, making it difficult to train them. Different solutions to this problem have been found, such as utilizing the Gumbel-Softmax approximation or SeqGAN, utilizing a stochastic policy-based Reinforcement Learning model as the Generator, with varying degrees of success.
Although worth mentioning, GANs are rarely used for Text Generation since they give worse results than Transformers (here a more in-depth explanation as to why written by their inventor, Ian Goodfellow), so we won’t dwell on them any longer.
The many challenges in Writing a Story
Countless classes are taught to teach aspiring artists how to write an effective plot for a book, movie, or show: both expertise and imagination are required to produce a decent result, making it the ultimate challenge in the domain of Natural Language Generation.
A story has a plot, characters, a setting, a tone, a genre, conflict, and resolution. It should feel familiar to the reader while also being new and innovative; teach and move; inspire and entertain while also being engaging. Most of the people we as a society celebrate are great storytellers: from JK Rowling to Steven Spielberg, from Shakespeare to Walt Disney, movie theatres and libraries are, of course, full of such paragons. But examples can also be found in less obvious contexts: marketing is all about storytelling, and even tech entrepreneurs like Steve Jobs and Elon Musk possess the rare ability to share their vision, inspiring us by telling a story about technology and our future.
“Marketing is no longer about the stuff you make, but the stories you tell” ~Seth Godin
So far, NLG algorithms have had a hard time even just managing writing short stories on their own: they struggle with the understanding of temporal and causal relations (not coincidentally, those are evaluated when testing a new NLP model) and with long-term coherence (although the attention-based architecture of transformers helps with this).
To solve those challenges, many solutions have been proposed with varying degrees of success, among which: an RL-generated skeleton to build the story upon; a hierarchical generation framework that first plans a storyline and then generates a story based on that; crowdsourced plot graphs and a character-centric approach.
Despite the models’ many current limitations, we believe their suggestions, if properly harnessed, with the learned knowledge of a thousand books and different genres, can be of great help to a human writer. Let’s focus on helping someone struggling with writer’s block, either for lack of ideas or because he can’t think of a way to express them the way he wants to and deepen this domain of NLG.
Conditional Text Generation
Conditional Text Generation refers to the task of generating new text starting from a context and adapting to it: its tone, writer, goal, sentiment, common sense, and other similar external factors. This means leaving most of the more high-level, creative tasks to a human (we’ll see some examples in the next section) but also adding the complexity of having to generate more personalized and logically connected content in order to reach a harmonious human-machine interaction.
The importance of fine-tuning
We’ve mentioned before that a model needs a huge amount of examples, the text corpus, to learn from, so how can we teach it a particular style without a plethora of examples at our disposal?
That’s where fine-tuning comes into play: quickly re-training an already pre-trained model on a new, cherry-picked corpus to specialize in a specific task. The model has already learned how to write from the bigger corpus and now tweaks its own statistical representation just enough to produce results that are more in line with the desired output.
The choice of text is essential, as different material can result in very different styles, and we wouldn’t want a modern-era story to sound like it was written by Shakespeare (see the examples below, based on this Huggingface article and this blog post by Max Woolf).

If the writer has enough material for his own production, perhaps the model can be fine-tuned on his very own style, making the suggestions more in tune with the rest of what’s being written (Personalised Text Generation). Alternative approaches can be: fine-tuning a model on the context of the story (for example, the epoch it’s set in), on its topic (Topic-Aware Text Generation), or on the mood the writer wants to convey (Emotional Story Generation).
Magic in Action
Legend has it that Stephen King was only 22 when he wrote a short but powerful sentence:
“The man in black fled across the desert, and the gunslinger followed.”
It was the beginning of an epic adventure, one that spans 3’000 pages, eight volumes, and more than three decades of effort on the part of its author, a saga known as The Dark Tower.
But what if King hadn’t been able to write anything following that first sentence for a while, thus deciding to just move on and write something else? How many great story ideas get hastily sketched on a piece of paper but never get the chance to develop into something more because the writer has no idea how to continue, how to nurture them into a complete story?
That’s where our project comes in: enough chit-chat, let’s see what we’ve been able to achieve with some recent algorithms, and what better sentence to start from than the famous Dark Tower incipit?
(Full disclosure: all examples presented are slightly cherry-picked, but I assure you more than half of the generated ones were valid)



As we can see, the model utilizes modern-world settings because that’s where most of the books it was trained on taking place. Let’s fine-tune it on Shakespeare’s work and see if a Shakespearean style suits more the kind of story we had in mind:



Of course, you can choose which ideas you want to keep and which don’t fit the narrative you had in mind. Let’s see another example, how even with a fairly simple incipit many different directions can be taken: I have decided to write about the downfall of a king named Henry (“Henry was once a great king, until…“) and looked for some inspiration:




It only takes a minute to generate countless possibilities to draw inspiration from, and we hope our work will help provide the spark that rekindles the fire of your creativity!
End of part one
The introduction of Transformers and new models more powerful than ever make the perfect breeding ground for the development of new tools to help writers. In this article, we’ve presented a brief recap of the history of NLP models, our goal, how the domain of conditional text generation is relevant to achieve it, and a few examples. We hope you’ve enjoyed the journey so far. More to follow soon!
Thank you for reading!

About Digitiamo
Digitiamo is a start-up from Italy focused on using AI to help companies manage and leverage their knowledge. To find out more, visit us.
About the Authors
Fabio Chiusano is the Head of Data Science at Digitiamo; Francesco Fumagalli is an aspiring data scientist doing an internship.
Conditional Story Generation — Part 1 was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts



Recent Posts






")