


Machine Learning Project in Python Step-By-Step — Loan Defaulters Prediction
Last Updated on July 17, 2023 by Editorial Team
Author(s): Fares Sayah
Originally published on Towards AI.
Develop a basic understanding of risk analytics and understand how data is used to minimize the risk of losing money
Introduction
LendingClub is a US peer-to-peer lending company headquartered in San Francisco, California? It was the first peer-to-peer lender to register its offerings as securities with the Securities and Exchange Commission (SEC) and to offer loan trading on a secondary market. LendingClub is the world's largest peer-to-peer lending platform.
Solving this case study will give us an idea of how real business problems are solved using EDA and Machine Learning. In this case study, we will also develop a basic understanding of risk analytics in banking and financial services and understand how data is used to minimize the risk of losing money while lending to customers.
Business Understanding
You work for the LendingClub a company that specializes in lending various types of loans to urban customers. When the company receives a loan application, the company has to make a decision for loan approval based on the applicant’s profile. Two types of risks are associated with the bank’s decision:
- If the applicant is likely to repay the loan, then not approving the loan results in a loss of business for the company
- If the applicant is not likely to repay the loan, i.e., he/she is likely to default, then approving the loan may lead to a financial loss for the company.
The data given contains information about past loan applicants and whether they ‘defaulted’ or not. The aim is to identify patterns that indicate if a person is likely to default, which may be used for taking actions such as denying the loan, reducing the amount of the loan, lending (to risky applicants) at a higher interest rate, etc.
When a person applies for a loan, there are two types of decisions that could be taken by the company:
Loan accepted: If the company approves the loan, there are 3 possible scenarios described below: –Fully paid: Applicant has fully paid the loan (the principal and the interest rate) –Current: Applicant is in the process of paying the installments, i.e., the tenure of the loan is not yet completed. These candidates are not labeled as 'defaulted'. –Charged-off: Applicant has not paid the installments in due time for a long period of time, i.e., he/she has defaulted on the loanLoan rejected: The company had rejected the loan (because the candidate does not meet their requirements etc.). Since the loan was rejected, there is no transactional history of those applicants with the company, and so this data is not available with the company (and thus in this dataset)
Business Objectives
LendingClubis the largest online loan marketplace, facilitating personal loans, business loans, and financing of medical procedures. Borrowers can easily access lower-interest-rate loans through a fast online interface.- Like most other lending companies, lending loans to ‘
risky’ applicants is the largest source of financial loss (calledcredit loss). Credit loss is the amount of money lost by the lender when the borrower refuses to pay or runs away with the money owed. In other words, borrowers who default cause the largest amount of loss to the lenders. In this case, the customers labeled as 'charged-off' are the 'defaulters'. - If one is able to identify these risky loan applicants, then such loans can be reduced, thereby cutting down the amount of credit loss. Identification of such applicants using EDA and machine learning is the aim of this case study.
- In other words, the company wants to understand the driving factors (or driver variables) behind loan default, i.e., the variables which are strong indicators of default. The company can utilize this knowledge for its portfolio and risk assessment.
- To develop your understanding of the domain, you are advised to independently research a little about risk analytics (understanding the types of variables and their significance should be enough).
Exploratory Data Analysis
OVERALL GOAL:
Get an understanding of which variables are important, view summary statistics, and visualize the data
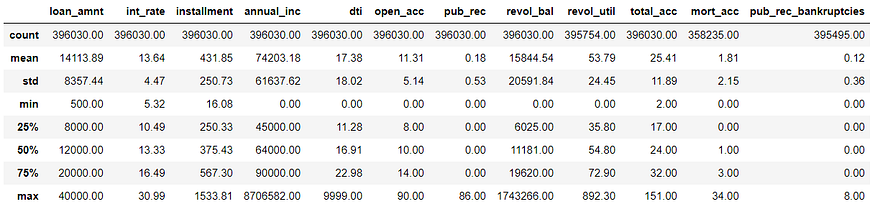
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 396030 entries, 0 to 396029
Data columns (total 27 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 loan_amnt 396030 non-null float64
1 term 396030 non-null object
2 int_rate 396030 non-null float64
3 installment 396030 non-null float64
4 grade 396030 non-null object
5 sub_grade 396030 non-null object
6 emp_title 373103 non-null object
7 emp_length 377729 non-null object
8 home_ownership 396030 non-null object
9 annual_inc 396030 non-null float64
10 verification_status 396030 non-null object
11 issue_d 396030 non-null object
12 loan_status 396030 non-null object
13 purpose 396030 non-null object
14 title 394275 non-null object
15 dti 396030 non-null float64
16 earliest_cr_line 396030 non-null object
17 open_acc 396030 non-null float64
18 pub_rec 396030 non-null float64
19 revol_bal 396030 non-null float64
20 revol_util 395754 non-null float64
21 total_acc 396030 non-null float64
22 initial_list_status 396030 non-null object
23 application_type 396030 non-null object
24 mort_acc 358235 non-null float64
25 pub_rec_bankruptcies 395495 non-null float64
26 address 396030 non-null object
dtypes: float64(12), object(15)
memory usage: 81.6+ MB
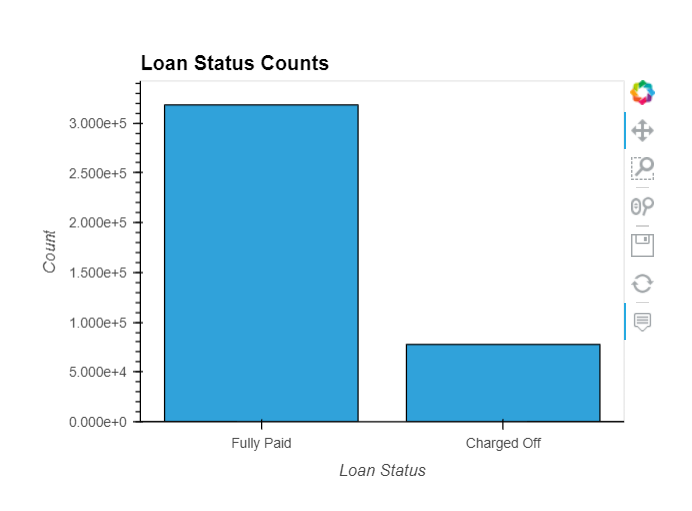
loan_status
Current status of the loan
Notice
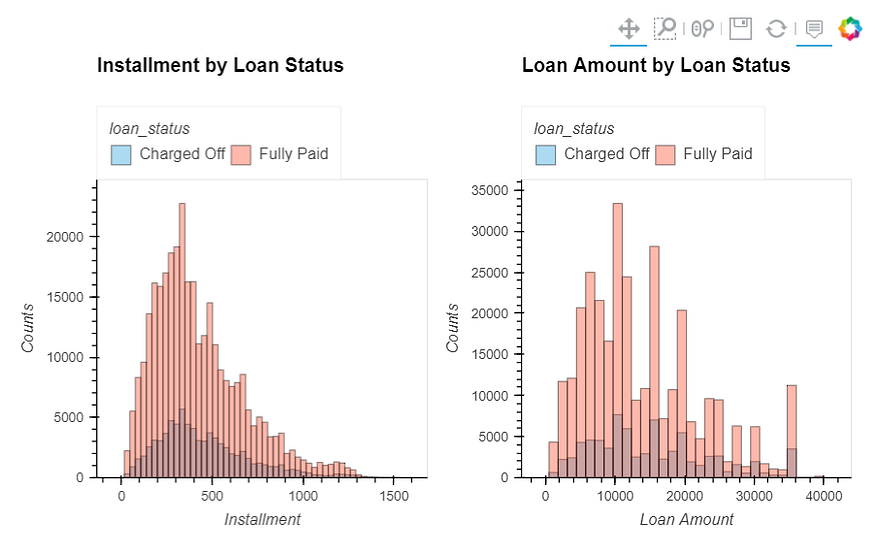
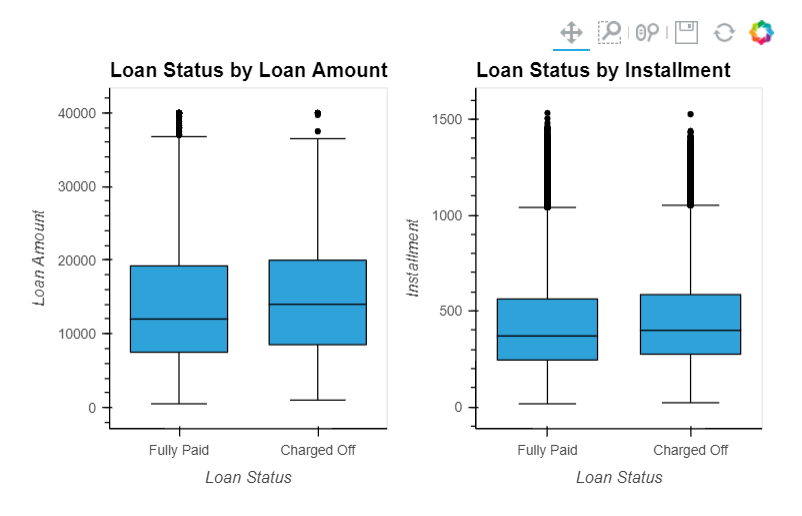
We noticed an almost perfect correlation between “loan_amnt" the "installment" feature. We'll explore these features further. Print out their descriptions and perform a scatterplot between them.
- Does this relationship make sense to you?
- Do we think there is duplicate information here?
loan_amnt & installment
installment: The monthly payment owed by the borrower if the loan originates.loan_amnt: The listed amount of the loan applied for by the borrower. If at some point in time, the credit department reduces the loan amount, then it will be reflected in this value.

grade & sub_grade
grade: LC assigned loan gradesub_grade: LC assigned loan subgrade
Let’s explore the Grade and SubGrade columns that LendingClub attributes to the loans.
What are the unique possible grade & sub_grade?

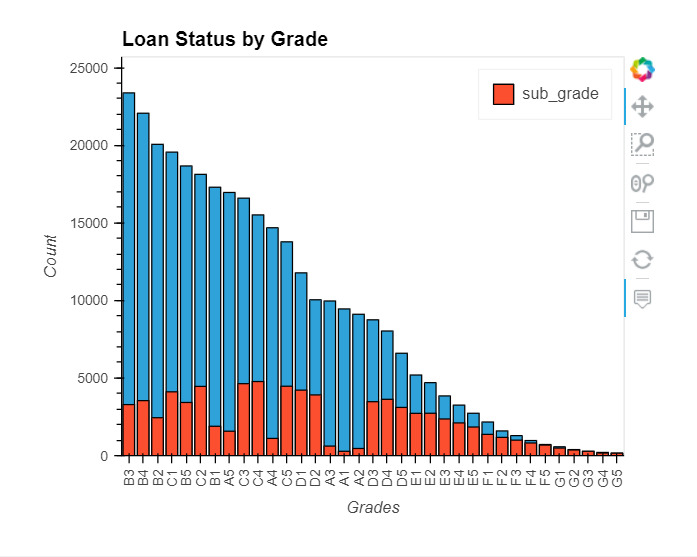
It looks like F and G subgrades don't get paid back that often. Isolate those and recreate the countplot just for those subgrades.

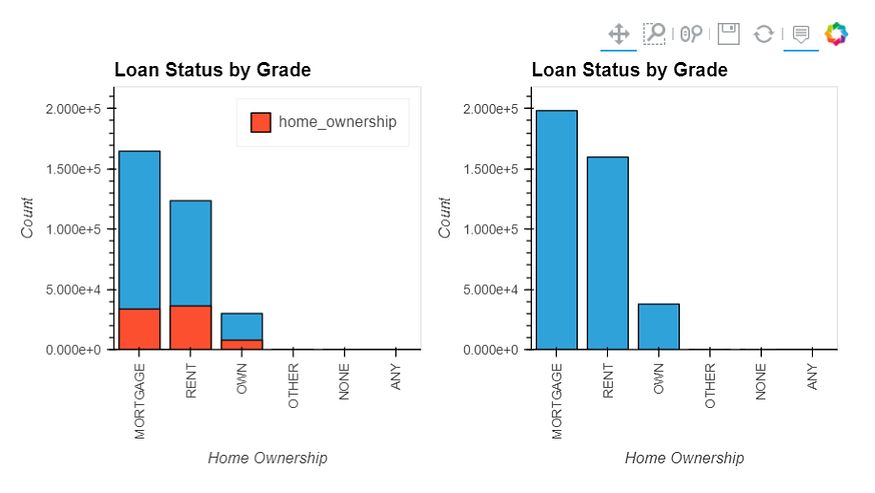
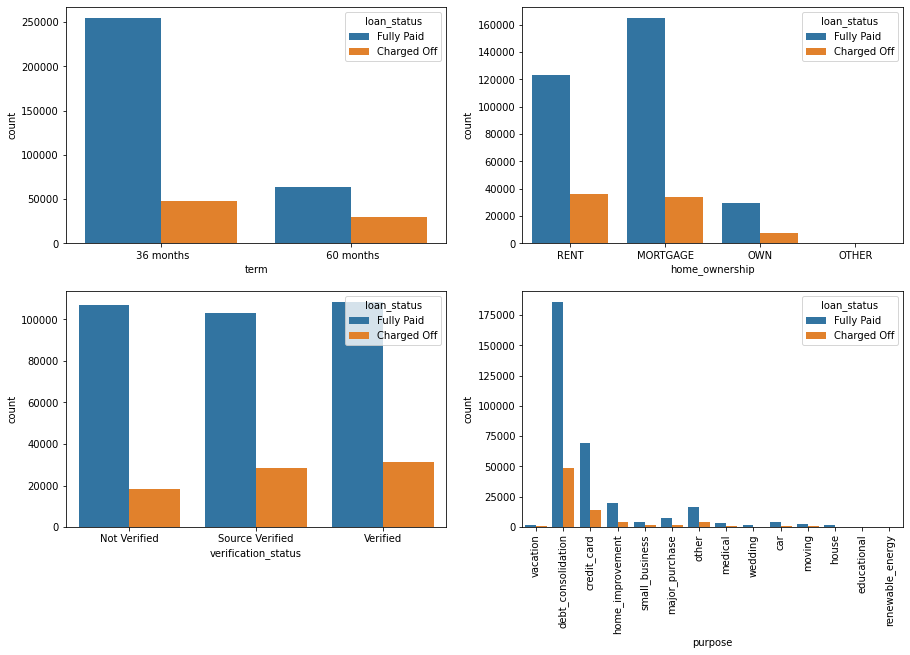
term, home_ownership, verification_status & purpose
term: The number of payments on the loan. Values are in months and can be either 36 or 60.home_ownership: The homeownership status provided by the borrower during registration or obtained from the credit report. Our values are: RENT, OWN, MORTGAGE, OTHERverification_status: Indicates if income was verified by LC, not verified, or if the income source was verifiedpurpose: A category provided by the borrower for the loan request.
Fully Paid 123
Charged Off 23
Name: loan_status, dtype: int64
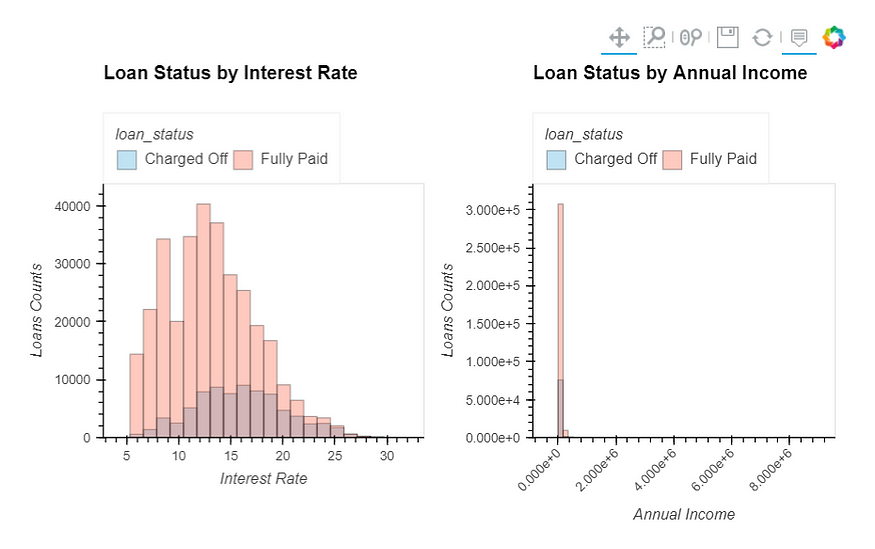
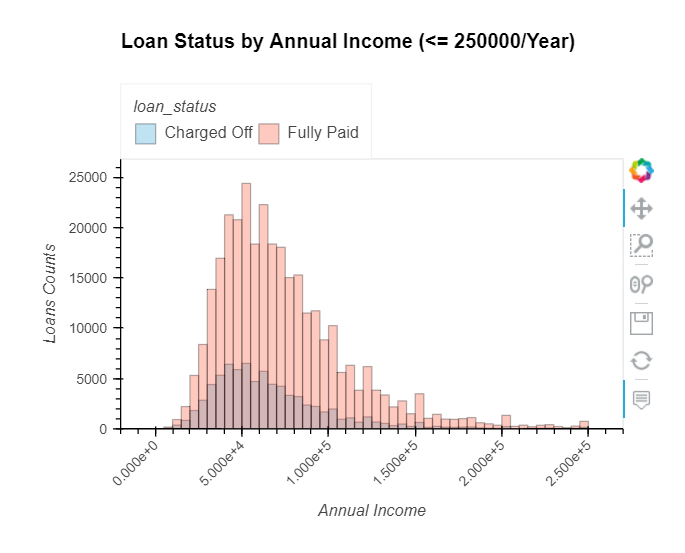
int_rate & annual_inc
int_rate: Interest Rate on the loanannual_inc: The self-reported annual income provided by the borrower during registration
1.0294674645860162
0.018937959245511705
Fully Paid 65
Charged Off 10
Name: loan_status, dtype: int64
Fully Paid 3509
Charged Off 568
Name: loan_status, dtype: int64
- It seems that loans with a high-interest rate are more likely to be unpaid.
- Only 75 (less than) borrowers have an annual income of more than 1 million, and 4077
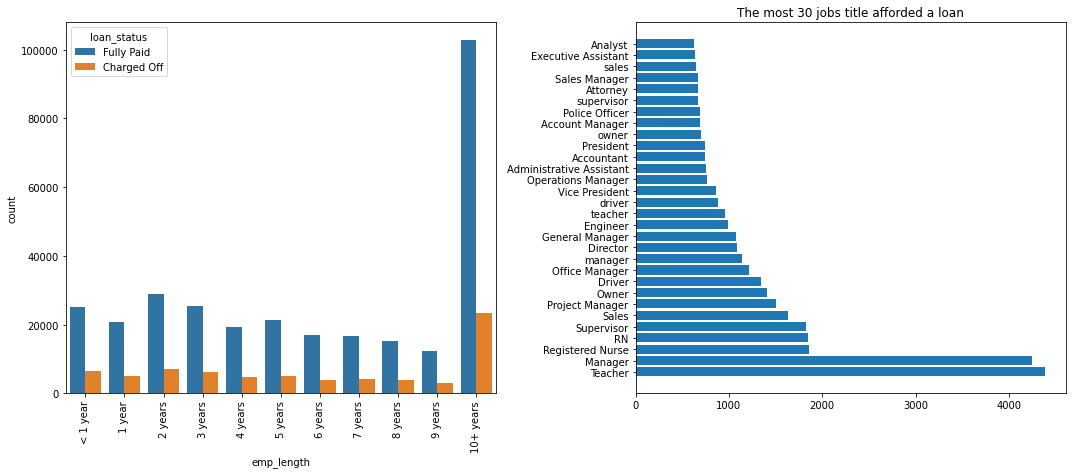
emp_title & emp_length
emp_title: The job title supplied by the Borrower when applying for the loan.emp_length: Employment length in years. Possible values are between 0 and 10 where 0 means less than one year and 10 means ten or more years.
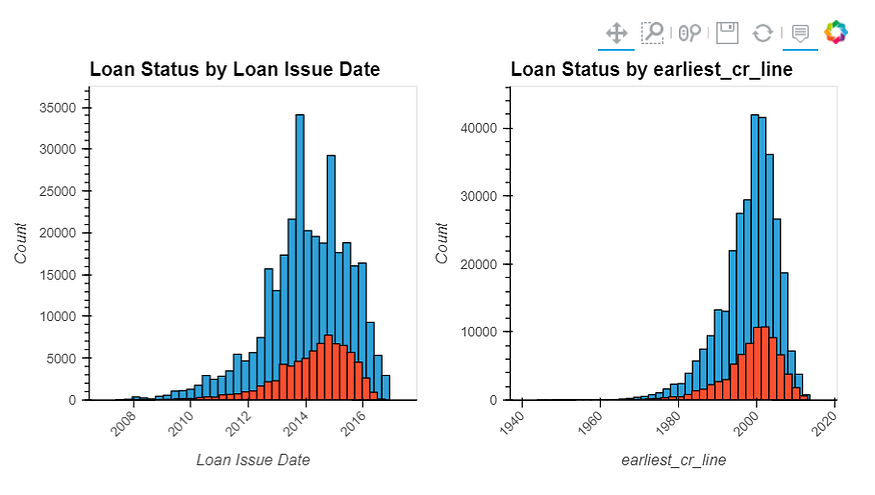
issue_d, earliest_cr_line
issue_d: The month in which the loan was fundedearliest_cr_line: The month the borrower's earliest reported credit line was opened
Oct-2000 3017
Aug-2000 2935
Oct-2001 2896
Aug-2001 2884
Nov-2000 2736
...
Nov-1953 1
Jun-1959 1
Sep-1960 1
Feb-1961 1
Aug-1958 1
Name: earliest_cr_line, Length: 684, dtype: int64
We need to convert earliest_cr_line to pandas DateTime object
title
title: The loan title provided by the borrower
debt consolidation 168108
credit card refinancing 51781
home improvement 17117
other 12993
consolidation 5583
major purchase 4998
debt consolidation loan 3513
business 3017
medical expenses 2820
credit card consolidation 2638
Name: title, dtype: int64
title will be removed because we have the purpose a column that is generated from it.
dti, open_acc, revol_bal, revol_util, & total_acc
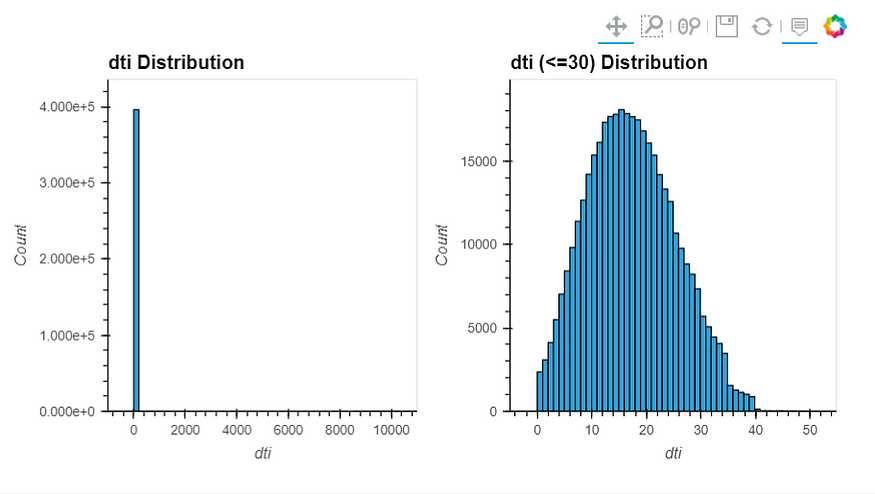
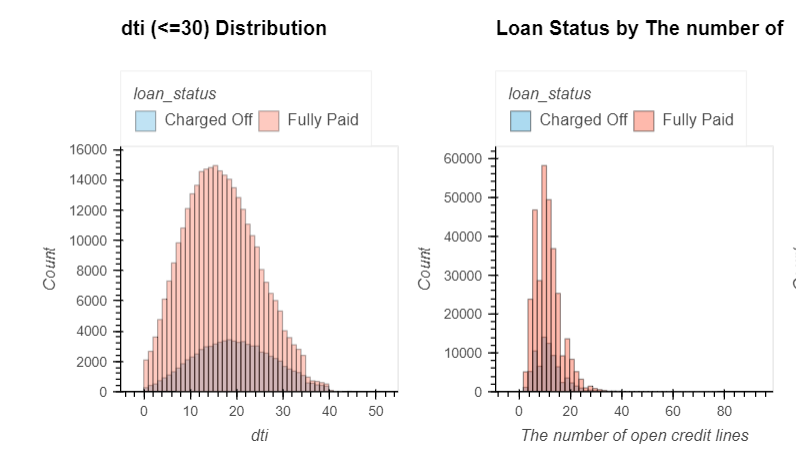
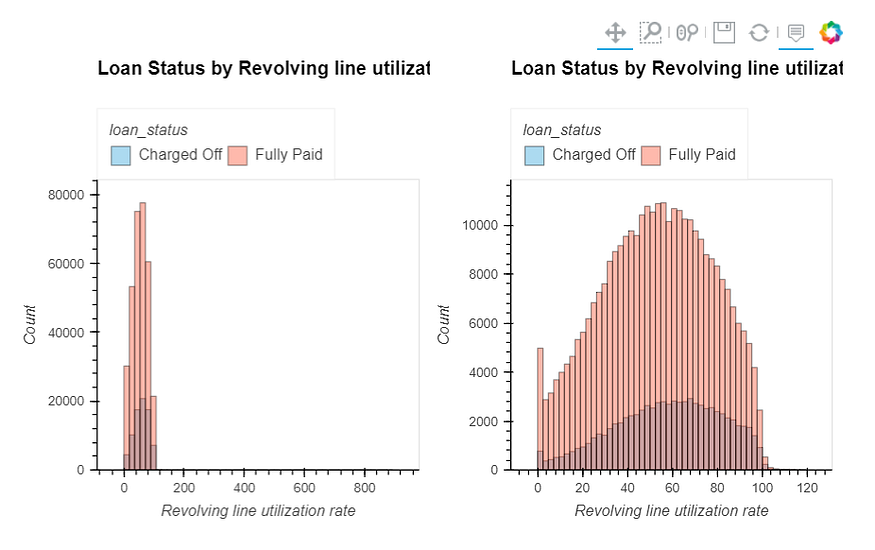
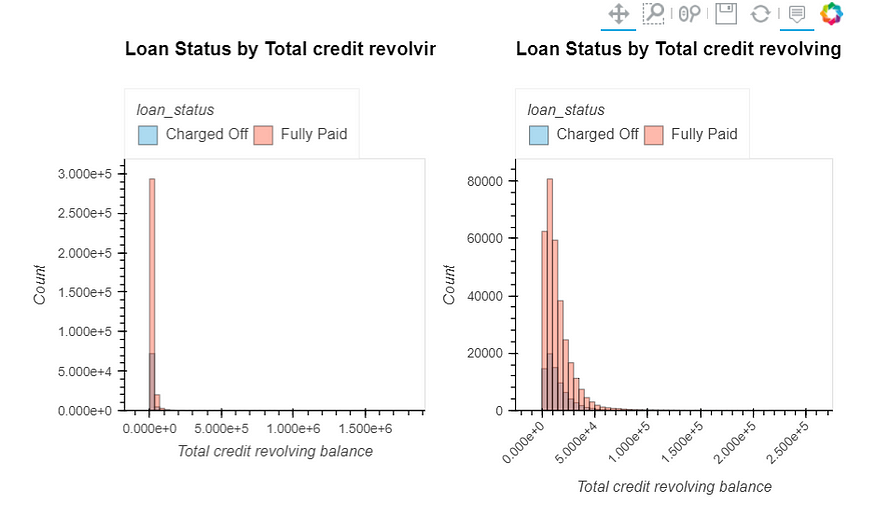
dti: A ratio calculated using the borrower’s total monthly debt payments on the total debt obligations, excluding mortgage and the requested LC loan, divided by the borrower’s self-reported monthly income.open_acc: The number of open credit lines in the borrower's credit file.revol_bal: Total credit revolving balancerevol_util: Revolving line utilization rate or the amount of credit the borrower is using relative to all available revolving credit.total_acc: The total number of credit lines currently in the borrower's credit file
Fully Paid 351
Charged Off 46
Name: loan_status, dtype: int64
- It seems that the smaller the
dtimore likely it is that the loan will not be paid. - Only
217borrowers have more than40open credit lines. - Only
266borrowers have more than80credit line in the borrower credit file.
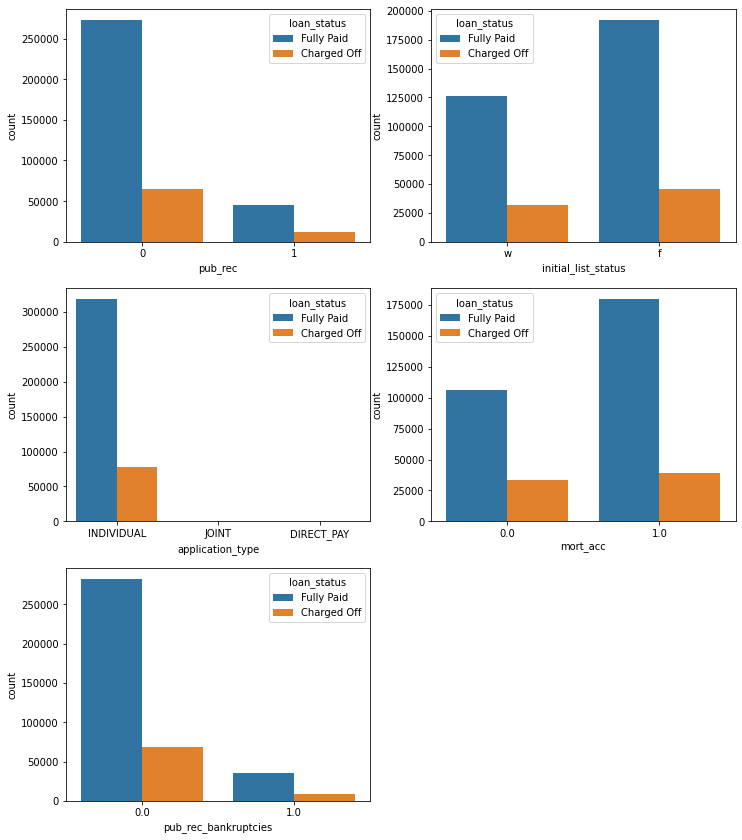
pub_rec, initial_list_status, application_type, mort_acc, & pub_rec_bankruptcies
pub_rec: Number of derogatory public recordsinitial_list_status: The initial listing status of the loan. Possible values are – W, Fapplication_type: Indicates whether the loan is an individual application or a joint application with two co-borrowersmort_acc: Number of mortgage accountspub_rec_bankruptcies: Number of public record bankruptcies
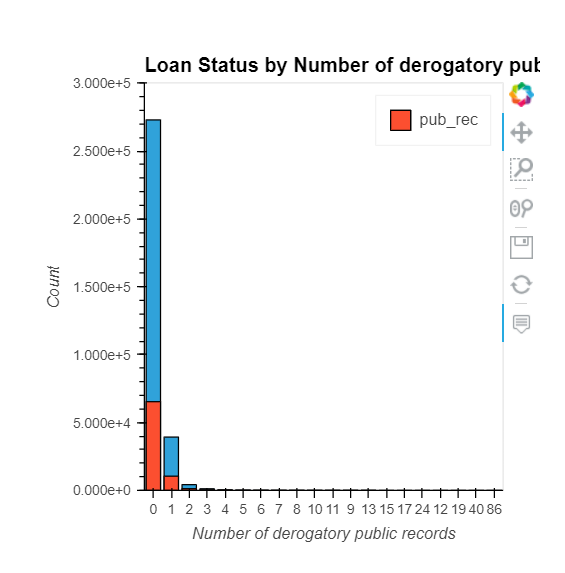
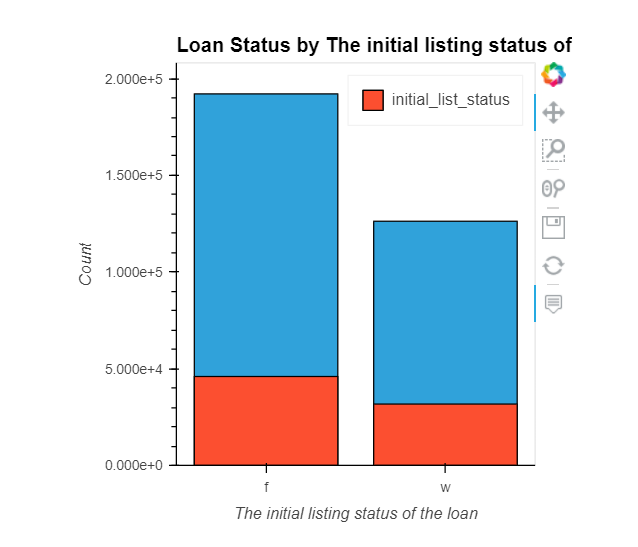
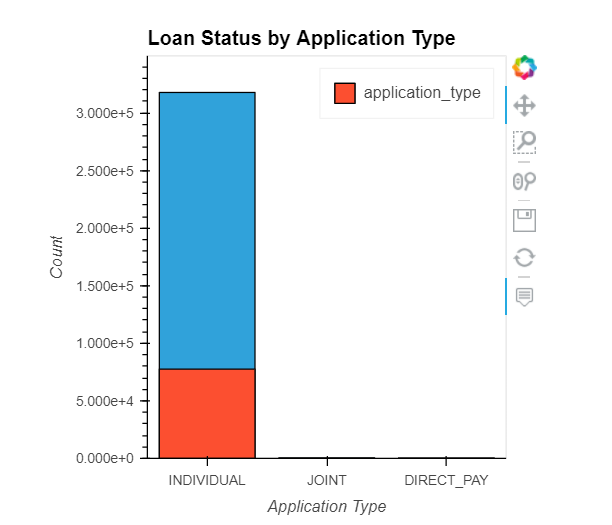
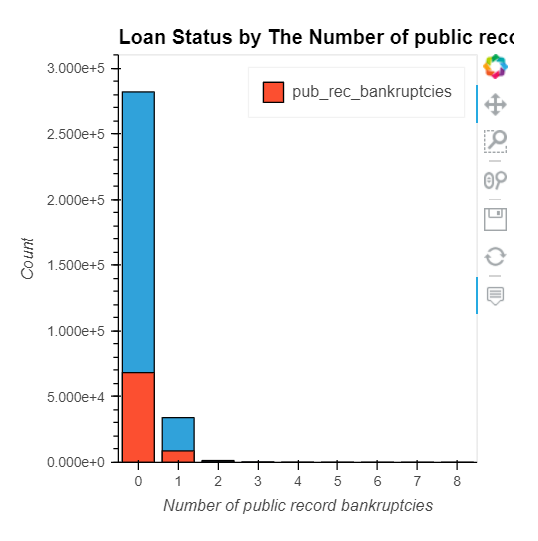
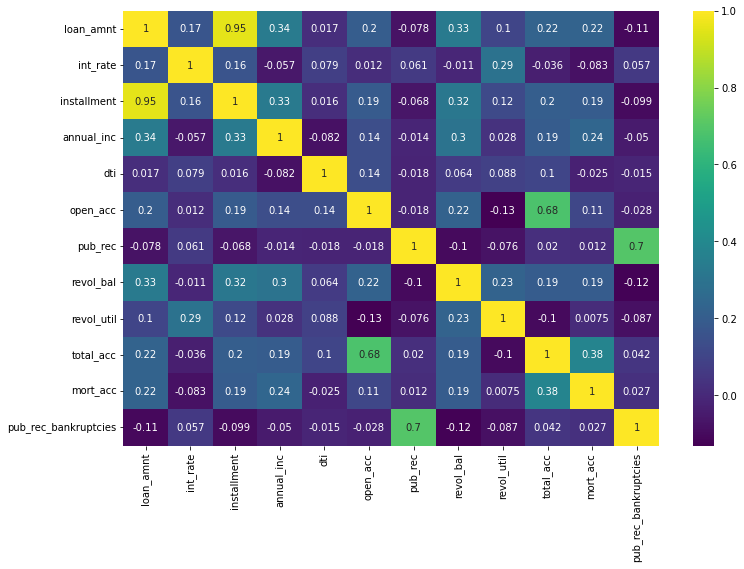
How do numeric features correlate with the target variable?
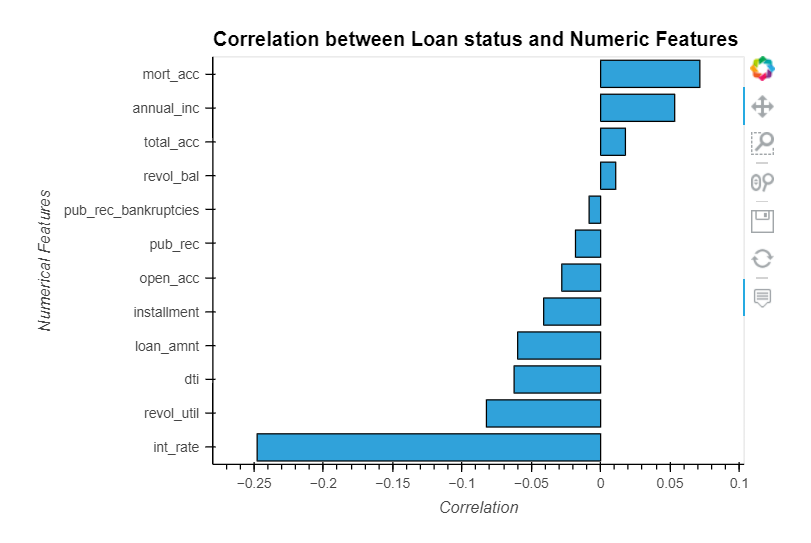
Conclusion:
We notice that there are broadly three types of features:
- Features related to the applicant (demographic variables such as occupation, employment details, etc.),
- Features related to loan characteristics (amount of loan, interest rate, the purpose of the loan, etc.)
Data PreProcessing
Section Goals:
- Remove or fill in any missing data.
- Remove unnecessary or repetitive features.
- Convert categorical string features to dummy variables.
'emp_title': number of missing values '22927' ==> '5.789%'
'emp_length': number of missing values '18301' ==> '4.621%'
'title': number of missing values '1755' ==> '0.443%'
'revol_util': number of missing values '276' ==> '0.070%'
'mort_acc': number of missing values '37795' ==> '9.543%'
'pub_rec_bankruptcies': number of missing values '535' ==> '0.135%'
emp_title
173105
Realistically there are too many unique job titles to try to convert this to a dummy variable feature. Let’s remove that emp_title column.
emp_length
array(['10+ years', '4 years', '< 1 year', '6 years', '9 years',
'2 years', '3 years', '8 years', '7 years', '5 years', '1 year',
nan], dtype=object)
Charge-off rates are extremely similar across all employment lengths. So we are going to drop the emp_length column.
title
debt consolidation 168108
credit card refinancing 51781
home improvement 17117
other 12993
consolidation 5583
Name: title, dtype: int64
debt_consolidation 234507
credit_card 83019
home_improvement 24030
other 21185
major_purchase 8790
Name: purpose, dtype: int64
The title column is simply a string subcategory/description of the purpose column. So we are going to drop the title column.
mort_acc
There are many ways we could deal with this missing data. We could attempt to build a simple model to fill it in, such as a linear model, we could just fill it in based on the mean of the other columns, or you could even bin the columns into categories and then set NaN as its own category. There is no 100% correct approach!
Let’s review the other columns to see which most highly correlates to mort_acc
1.00 218458
0.00 139777
Name: mort_acc, dtype: int64
37795
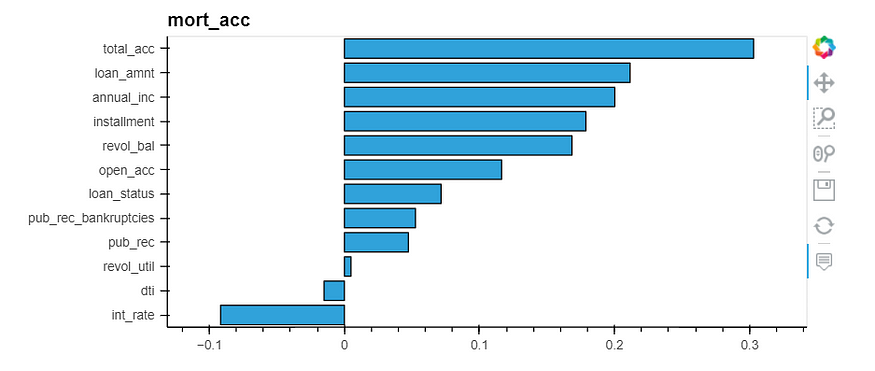
Looks like the total_acc feature correlates with the mort_acc , this makes sense! Let’s try this fillna() approach. We will group the DataFrame by the total_acc and calculate the mean value for the mort_acc per total_acc entry. To get the result below:
revol_util & pub_rec_bankruptcies
These two features have missing data points, but they account for less than 0.5% of the total data. So we are going to remove the rows that are missing those values in those columns with dropna().
'revol_util': number of missing values '276' ==> '0.070%'
'pub_rec_bankruptcies': number of missing values '535' ==> '0.135%'
(395219, 24)
Categorical Variables and Dummy Variables
['term', 'grade', 'sub_grade', 'home_ownership', 'verification_status', 'purpose', 'initial_list_status', 'application_type', 'address']
term
array([' 36 months', ' 60 months'], dtype=object)
array([36, 60])
grade & sub_grade
We know that grade is just a sub-feature of sub_grade, So we are going to drop it.
address
We are going to feature engineer a zipcode column from the address in the data set. Create a column called ‘zip_code’ that extracts the zip code from the address column.
0 0174 Michelle Gateway\r\nMendozaberg, OK 22690
1 1076 Carney Fort Apt. 347\r\nLoganmouth, SD 05113
2 87025 Mark Dale Apt. 269\r\nNew Sabrina, WV 05113
3 823 Reid Ford\r\nDelacruzside, MA 00813
4 679 Luna Roads\r\nGreggshire, VA 11650
Name: address, dtype: object
70466 56880
22690 56413
30723 56402
48052 55811
00813 45725
29597 45393
05113 45300
11650 11210
93700 11126
86630 10959
Name: zip_code, dtype: int64
issue_d
This would be data leakage, we wouldn’t know beforehand whether or not a loan would be issued when using our model, so in theory, we wouldn’t have an issue_date, drop this feature.
earliest_cr_line
This appears to be a historical time stamp feature. Extract the year from this feature using a .apply() function, then convert it to a numeric feature.
65
2000 29302
2001 29031
1999 26444
2002 25849
2003 23623
...
1951 3
1950 3
1953 2
1948 1
1944 1
Name: earliest_cr_line, Length: 65, dtype: int64
Train Test Split
Weight of positive values 0.19615200686201828
Weight of negative values 0.8038479931379817
(264796, 79)
(130423, 79)
Removing Outliers
(264776, 79)
(264796, 79)
(264796, 79)
(262143, 79)
Normalizing the data
loan_amnt float64
term int64
int_rate float64
installment float64
annual_inc float64
...
zip_code_30723 uint8
zip_code_48052 uint8
zip_code_70466 uint8
zip_code_86630 uint8
zip_code_93700 uint8
Length: 78, dtype: object
Models Building
Artificial Neural Networks (ANNs)
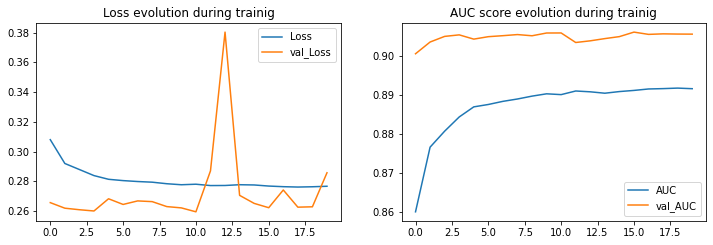
Train Result:
================================================
Accuracy Score: 88.85%
_______________________________________________
CLASSIFICATION REPORT:
0.0 1.0 accuracy macro avg weighted avg
precision 0.91 0.89 0.89 0.90 0.89
recall 0.48 0.99 0.89 0.73 0.89
f1-score 0.63 0.93 0.89 0.78 0.87
support 51665.00 210478.00 0.89 262143.00 262143.00
_______________________________________________
Confusion Matrix:
[[ 24810 26855]
[ 2362 208116]]
Test Result:
================================================
Accuracy Score: 88.86%
_______________________________________________
CLASSIFICATION REPORT:
0.0 1.0 accuracy macro avg weighted avg
precision 0.91 0.89 0.89 0.90 0.89
recall 0.48 0.99 0.89 0.73 0.89
f1-score 0.63 0.93 0.89 0.78 0.87
support 25480.00 104943.00 0.89 130423.00 130423.00
_______________________________________________
Confusion Matrix:
[[ 12195 13285]
[ 1239 103704]]
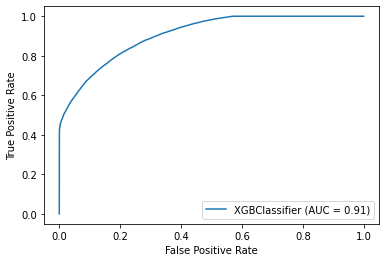
XGBoost Classifier
Train Result:
================================================
Accuracy Score: 89.60%
_______________________________________________
CLASSIFICATION REPORT:
0.0 1.0 accuracy macro avg weighted avg
precision 0.95 0.89 0.90 0.92 0.90
recall 0.50 0.99 0.90 0.75 0.90
f1-score 0.65 0.94 0.90 0.80 0.88
support 51665.00 210478.00 0.90 262143.00 262143.00
_______________________________________________
Confusion Matrix:
[[ 25828 25837]
[ 1423 209055]]
Test Result:
================================================
Accuracy Score: 88.94%
_______________________________________________
CLASSIFICATION REPORT:
0.0 1.0 accuracy macro avg weighted avg
precision 0.91 0.89 0.89 0.90 0.89
recall 0.48 0.99 0.89 0.73 0.89
f1-score 0.63 0.94 0.89 0.78 0.88
support 25480.00 104943.00 0.89 130423.00 130423.00
_______________________________________________
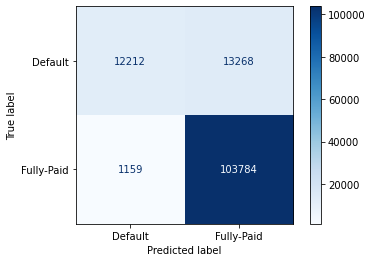
Confusion Matrix:
[[ 12212 13268]
[ 1159 103784]]
Random Forest Classifier
Train Result:
================================================
Accuracy Score: 100.00%
_______________________________________________
CLASSIFICATION REPORT:
0.0 1.0 accuracy macro avg weighted avg
precision 1.00 1.00 1.00 1.00 1.00
recall 1.00 1.00 1.00 1.00 1.00
f1-score 1.00 1.00 1.00 1.00 1.00
support 51665.00 210478.00 1.00 262143.00 262143.00
_______________________________________________
Confusion Matrix:
[[ 51661 4]
[ 0 210478]]
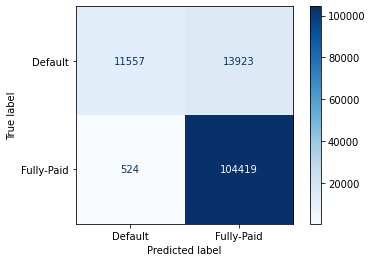
Test Result:
================================================
Accuracy Score: 88.92%
_______________________________________________
CLASSIFICATION REPORT:
0.0 1.0 accuracy macro avg weighted avg
precision 0.96 0.88 0.89 0.92 0.90
recall 0.45 1.00 0.89 0.72 0.89
f1-score 0.62 0.94 0.89 0.78 0.87
support 25480.00 104943.00 0.89 130423.00 130423.00
_______________________________________________
Confusion Matrix:
[[ 11557 13923]
[ 524 104419]]
Comparing Models Performance
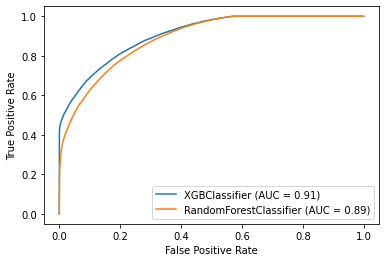
RANDOM FOREST roc_auc_score: 0.724
XGBOOST roc_auc_score: 0.734
ANNS roc_auc_score: 0.906
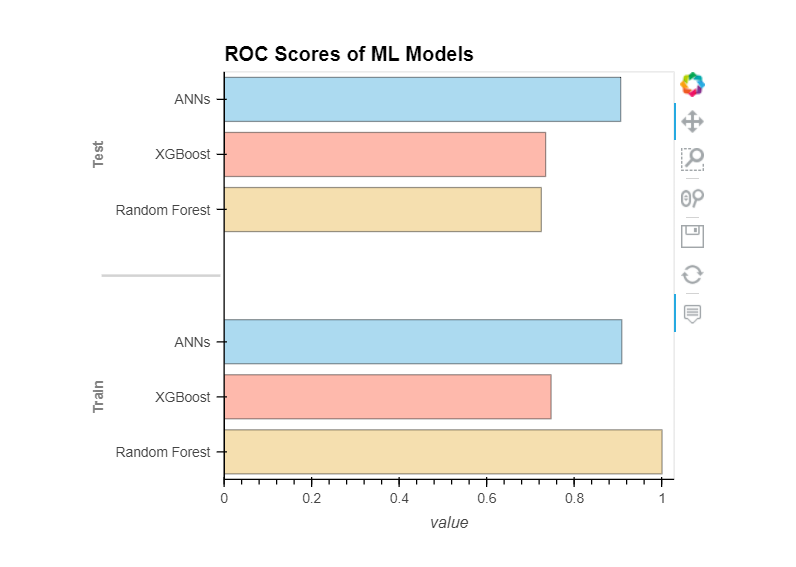
Conclusions:
We learned how to develop our loan defaulter model using machine learning. We used a variety of ML algorithms, including ANNs and Tree-based models. In the end, Artificial Neural Networks performed better than other models.
Links & Resources:
- Link to data used in this tutorial: Lending Club Dataset
- Link to Full Notebook
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Related posts


Popular posts

 for 2021")



Updates

Recent Posts



