



Deploying ML Models in Production: Model Export & System Architecture
Last Updated on September 2, 2020 by Editorial Team
Author(s): Avishek Nag
Machine Learning
Understanding model export mechanisms, lightweight integration, offline & online model hosting techniques
We often see many techniques discussed here & there about solving problems with ML. But when it comes to putting all of them into production, we don’t see that much traction, and people still have to rely on some public cloud providers or open source for that. In this article, we will discuss ML models to be used in production, and the system architectures for supporting it. We will see how can we do that without having any public cloud provider.
Model export
Mostly all ML models are either mathematical expressions, equations or data structures (tree or graph). Mathematical expressions have coefficients, some variables, some constants, some parameters of probability distributions (distribution-specific parameters, standard deviations or mean). Let’s take a simple example of a linear regression model:

How much information does it have? 3 pairs of coefficient value & feature name and one constant. Definitely these seven values can be written in a file.
So, Model export is nothing but writing the meta-data information of the model in a file or data store. It is needed for saving the model for future use.
Platform Independent Model export
ML models are trained using different technology stacks like Python, Java, .NET, etc. Within Python, there are different frameworks like sci-kit-learn, PyTorch, TensorFlow and so many. There is an obvious need for a platform-independent model export mechanism. Most of the time, typical usages of models will be of cross-platform type. A model can be designed in the Python platform, but for high availability reasons, it may be served from a Java platform. We will discuss this in detail in later sections. Before that let us discuss two different Model export formats.
PMML: PMML stands for Predictive Model Markup Language. It is an XML based standard and it has a predefined schema. The model is exported as an XML file.
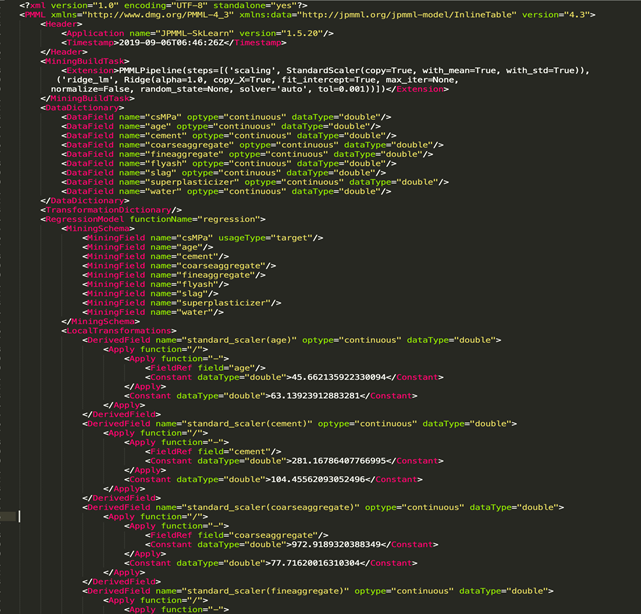
The above PMML content is for a Linear Regression model. We can see that it contains the model type (in the above case regression), pre-processing steps (in the above case StandardScaler), feature names, and much other information.
PMML suffers from sizing problems. Too many features produce quite large XML s especially for NLP models.
It is therefore sometimes convenient to convert PMML content into a JSON.
ONNX: It stands for Open Neural Network Exchange. It is ideal for Deep Learning models. It produces a network graph that is serialized in a binary file. As usual, the graph contains hidden and output layer weights and connections information. Unlike PMML, it does not produce XML.
Both of these formats are portable (especially PMML) across platforms.
Model Consumption & Portability
The exported model using the above-mentioned formats can be consumed for actual usage. Model training involves an iterative process for determining its parameters & hyper-parameters. But, once trained, model consumption is a single-shot process. Let’s say, we trained a Linear Regression model using Stochastic Gradient Descent in a high-performance machine. The produced model is a collection of coefficients, feature names & pre-processing information. It has to be saved somewhere using any format so that we can load and use it later.
To consume the model, we just have to multiply features from an incoming data instance with coefficients, add the intercept and return the result.
So, it does not matter in which platform the model was designed & built. In ML-based production systems, it is quite natural that the component developed may be consumed from a different platforms. With a proper model exporting support, a model designed in Python can be utilized inside an Android app.
In general, ML model consumption logic has to be developed inside the consuming platform. We can call this as Stub.
Following diagram explains the situation
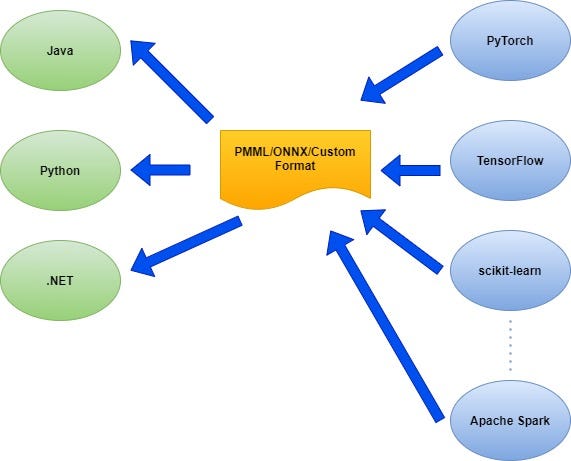
Model designed in different Python frameworks (scikit-learn, PyTorch, TensorFlow) or in Big data stack like Apache Spark/Flink can be exported in any defined format (PMML/ONNX) and the same can be consumed by different client applications (Java, Python or .NET). So, it is a many-to-many situation.
Client applications parse the model file and extract out the necessary parameters to build an in-memory version of the model.
Instead of relying on PMML/ONNX or any standard format, a user-defined custom format can also be defined for some very specific requirements (as shown in the diagram). In any case, the objective is “to make a model portable across platforms”
Model deployment & System Architecture
Most of the time, Data Science activities are done in Python using standard libraries discussed above. But, it is not a very scalable option. We need a strong Data Engineering and deployment platform for Production Grade Systems. Big data plays a big role here. Models can be trained with petabytes of data in Big data platforms like Spark, Hadoop, Flink, etc. In fact, these are always preferred in production systems.
There are two challenges in designing architecture. One challenge is already mentioned above about Python. The other one is with Big data platform itself.
Apache Spark/Flink is not suitable for synchronous integration and these run in offline/batch/asynchronous mode.
So, directly exposing the Spark/Hadoop layer prediction API via REST can be very dangerous for client-facing systems having high/moderate throughput expectations. Even with low throughput requirements, synchronous integration is not recommended at all. Model export mechanism using PMML/ONNX or other format solves the problem here.
The model should be trained using Big data stack and then exported & stored in a Model registry. It should support versioning and history mechanisms for incremental/iterative training process. The flow is cyclic in nature and shown below:
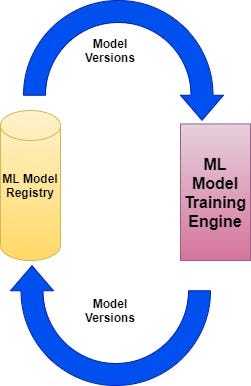
One prediction engine then should consume the model and returns back the result. This engine should be well versed with model export formats. This way prediction & training process becomes completely disconnected and loosely coupled.
Even in some hypothetical situations, if the model is trained with Python frameworks for small datasets instead of Big data stack, prediction engine need not to be updated. It is a big advantage of this design.
Now, we will discuss three different system architectures of model deployment using the concept described above.
On-demand Cloud (Model as Service) Deployment
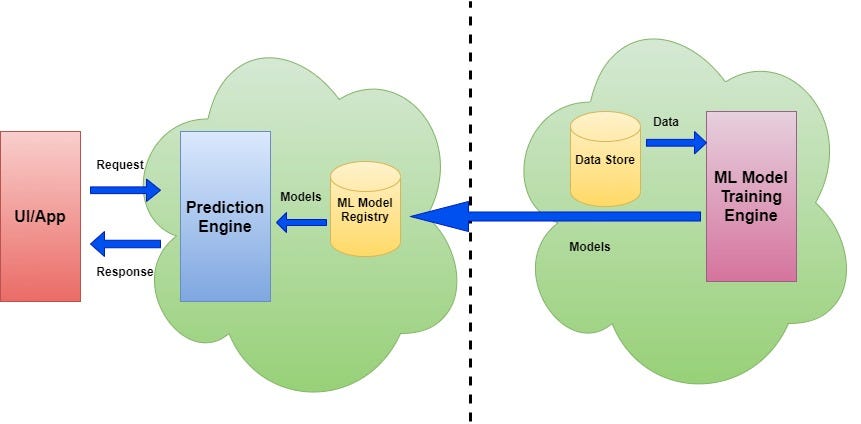
From the diagram above, we can see the models are trained and pushed into the model registry in an offline manner (dashed line indicates offline process). This training is a periodic & asynchronous process. The prediction engine takes requests from client-facing UI/App and executes the model to get results. This is an on-demand synchronous process and has no connection with the model training engine.
Models are hosted here as Service (via REST API) and give real time predictions. Most of the public cloud ML providers follow this architecture.
Offline Cloud Deployment
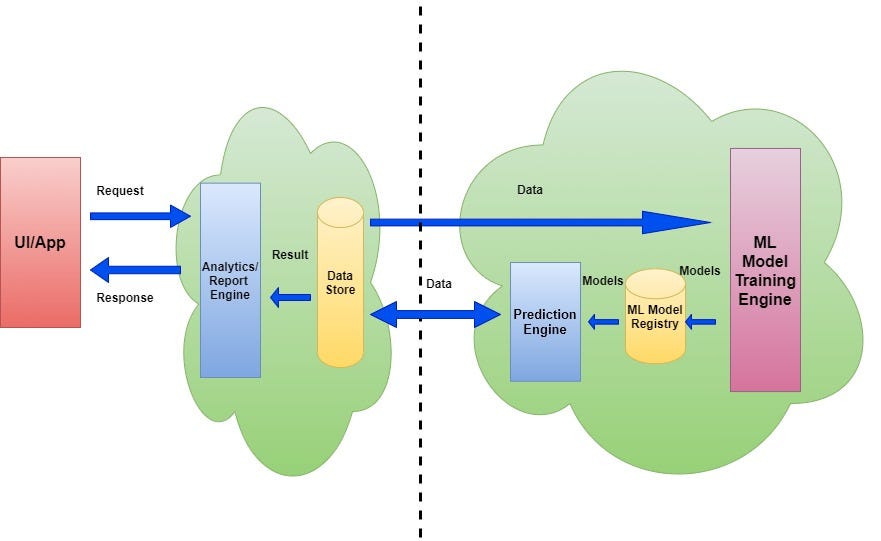
Here prediction engine works within the range of the model training engine and the prediction process also work in an offline manner along with training. Predictions are stored in a data store. One analytics engine handles the synchronous requests from UI/App and returns back the pre-stored predictions. Here Model registry need not necessarily support all relevant model export formats as the predictions are done within the scope of the big data engine.
This architecture is useful in situations where models are utilized for generating analytics report or a set of recommendations in offline manner.
Packaged Deployment
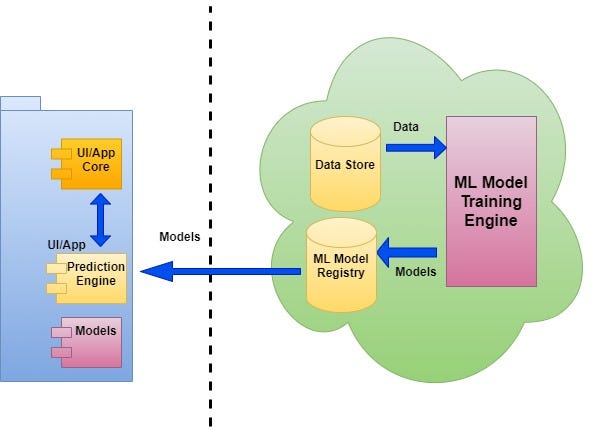
This is for typical mobile apps or situations where public/private cloud connectivity is not there. The prediction engine is packaged within the client-facing UI/App/devices. It has to be very lightweight as memory limitations may be there on many devices. Model training and registry should work as an offline process. This architecture should work even there is no internet connectivity as predictions are happening within the app/devices.
It is also ideal for running in a disconnected server box or robotics based applications.
The above architectures may be an in-house alternative to the costly public cloud ML service providers. All that we need are good knowledge of system design & machine learning.
Note: Recently I authored a book on ML (https://twitter.com/bpbonline/status/1256146448346988546)
Deploying ML Models in Production: Model Export & System Architecture was originally published in Towards AI — Multidisciplinary Science Journal on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

