


")
AI/ML Model Build and Explainability (XAI)
Last Updated on July 25, 2023 by Editorial Team
Author(s): Himanshu Swamy
Originally published on Towards AI.
Machine Learning & Artificial Intelligence to Reduce Financial Crimes
Insurance Business Overview
One of the major components of the economy is the insurance industry, it protects against the financial risks that are present at all stages of people’s lives and businesses. Insurers protect against loss — of a car, a house, even a life — and pay the policyholder or designee a benefit in the event of that loss. The number of premiums it collects, the scale of its investment, and Insurance play an essential social and economic role by covering personal and business risks. Despite daunting macroeconomic and structural challenges, fierce competition, and ongoing tech-driven disruptions in the last few years, insurers have shown they can undertake large-scale change at a faster pace than many industry veterans thought possible and can deal with unexpected development. All aspects of life, including exposure to risk, can be Individuals and businesses. Whether we accept the consequences of a possible loss or seek insurance coverage in the event of a loss, reducing the exposure to risk depends on us. People who obtain coverage succeed in “transferring the risk” to another organization, i.e., the insurance company.
Purchasing insurance is the most common risk transfer mechanism for the majority of people and organizations. The money paid from the insured is known as the premium. In return, the insurer agrees to pay a designated benefit in the event of the agreed-upon loss. In 2020 the gross premiums saw a slowdown, but the insurance industry saw a rebound in growth in 2021, especially in the Life sector. If we look at the data, it indicates that insurance companies experienced a rise in gross premiums by 7.3%. Insurance premiums also grew in the non-life sector by 1.7% on average.
Insured individuals may be able to sue other parties for the losses they have suffered, and a potential source of compensation is paid. Such situations are omnipresent: an insured driver whose car is damaged in an accident may be able to sue another driver who caused the accident for repair costs; an insured homeowner whose house burns down due to fire may be able to get compensation from an Insurance company, or a person covered by health insurance who slips and falls in a store may be able to sue the proprietor for medical expenses. Insurance policies not only promise to compensate insureds for their losses, they also usually include what is known as subrogation provisions that give the insurer the right to step into the shoes of an insured and to sue a party who caused the insured’s losses.
In Some countries, subrogation provisions are a common feature of property insurance, liability insurance, health and medical insurance, and disability insurance policies. During past years subrogation was the stepchild of the insurance market, but this image is changing. Today, in an environment of flat investment returns, subrogation is being used as a way for insurers to add to the bottom line. In recent times, the insurance industry is getting more sophisticated in analyzing and exploiting subrogation recoveries. The insurance industry has engaged in benchmark studies to help it obtain stronger statistical analyses for its subrogation program. Initial studies were created in the 1990s, but over the past 20 years, insurance companies have vacillated between the industry trend of centralizing and decentralizing their subrogation efforts. With proper analysis of flies closed with no recovery, the carriers can either become more creative or more aggressive, reducing the percentage of files closed without recovery. For subrogation, the areas of focus include motor, property, workers' compensation, and healthcare. Each of these areas has a special focus and strategy, often dependent on the laws of the different countries. For example, in motor recovery, some countries permit recovery of medical expenses, while other countries permit recovery only of property damage. Further, some cities are enacting anti-subrogation legislation, which will severely limit the ability of insurance companies to recover. The recent research on Personal Auto Collisions — indicated a high performing carrier would collect about 24%, while the average is about 11.5%. More recent studies show the standard recovery for paid collisions is up to 27%, while nonstandard carriers have a recovery rate of 14.5%. These numbers are a significant increase since the original benchmarks.
Most insurers are investing in modern systems, advanced data practice, and cutting-edge Machine learning & AI solutions that are flexible and robust to drive transformation. The implementation of the latest Artificial intelligence & Machine learning solutions enables employees to work more efficiently and bring focus to the customer relationship, thus improving the quality of individual interactions. Such investments have positioned these insurers to pursue new markets and advance their growth strategy.
With advancements made in Artificial intelligence & Machine learning, there is a unique opportunity for insurers to incorporate analytic scores within the decisioning engine to create a smart system. For any Insurance company to become completely data-driven requires significant efforts with more feeds from data and predictive models. The solution needs to be business-friendly and should support fact-based decisions.
To leverage AI & ML successfully, a few aspects should be considered
• Clearly defined Business problem with the proper target outcome
• Integrate predictive scores into the core system with detailed functional design
• Technical detail design that includes data acquisition, model building, and core system integration
Our Current Problem statement
Looking at the above facts and changing economies, Insurance companies have realized subrogation can be a carrier’s leading revenue stream during periods of difficult financial markets. Post-Covid, the economic slowdown in the auto insurance sector and particularly on uninsured claimants, can be observed. In the USA itself, 32+ million uninsured vehicles have a 35x spike in subrogation workload leading to 15% missed opportunities of subrogation (deteriorating) & 32% of recoverable paid claims are lost. If anyone of us gets into a situation when we just know the accident wasn’t our fault, but we couldn’t really do anything, even though it was the opposite party’s fault? This is exactly where we could benefit from something we call Subrogation in Insurance. The opportunity to pursue subrogation occurs in less than 10% of claims. Subrogation remains a manual process for most insurers, resulting in missed clues and costing some claims departments up to two percentage points of loss ratio.
Why do we need Subrogation?
Automated subrogation settlements around the world are drastically increasing, with countries such as the UK and Australia having automated settlement rates as high as 40%. However, the US automated settlement rate is between 10 and 15%, low compared to its global counterparts.
An Intelligent system driven by AI & ML will raise alerts to adjusters for those claims that are most likely to have a subrogation opportunity and provide an estimate of the recoverable amount with integration in the claims processing workflow. This new information would prevent adjusters from closing claims flagged by predictive models and refer them to subrogation professionals. Finding and recovering lost subrogation opportunities may appear to be negligible when compared to all other losses and expenses — yet this can result in a significant increase in underwriting profit. Some insurance companies add the deductible amount, too, in the case of a subrogation. So, in case of such a situation where the damage is done by the third party, people get their claim amount plus the deductible once the third party pays the compensation to the insurance company.
The solution is based on Machine learning and will lead to: –
· Elimination of leakage associated with subrogation identification.
· Reduce false positives up to 36%.
· Enable productivity gains up to 20%.
· Improve cycle time by over 30%.
The overall Benefits to Customers & Insurer will be: –
· Reduced fraud
· Improved customer retention
· Improves customer trust and experience
· Increased customer engagement
· Improves employee productivity
· Reduced costs and response times
A real-life example, a core aspect of this use case
To understand things easily, connect them with a story or an example. Suppose one fine day, your car happens to hurt after a reckless driver bumps into your car. Now, the back of your car is damaged, and this guy doesn’t even seem to accept his fault. You have no time to fight this out or argue further, so you move on with your damaged car and instead get your comprehensive car insurance to pay for the damages. Your insurance company here will hold the third-party responsible for the damage and reimburse both the amount of money you spent from your pocket plus the amount of money your insurance company paid for due to the damages and losses caused.
On the above aspect, how can analytics contribute to the value chain ..?
Our initial approach involves a standard model of insurance for accident risk and is supported by the ability of insured individuals to bring suit for harm that they suffer. We assume that identical risk-averse individuals face a chance of suffering harm from an accident; that they purchase insurance policies that maximize their expected utility, and that if an accident occurs, they will be able to sue a potentially liable party for compensation, where the suit would involve a litigation cost and result in success only with a probability.
Heuristic Model
Notation
y = initial wealth of an individual
U(∙) = utility of an individual from wealth, where U′ > 0 and U″ < 0
p = probability of an accident; p 0 (0, 1)
h = harm if an accident occurs; h > 0
k = cost of bringing a suit; k ≥ 0
q = probability of winning a suit, resulting in an award of h; q 0 [0, 1].
π = insurance premium
c = insurance coverage c ≥ 0
N = instruction whether the insurer sues under a subrogation provision; if N = 0, suit is not brought; if N = 1, suit is brought
s = insured’s share of the award h under a subrogation provision if a suit is successful; s 0 [0, h]
Under a pure insurance policy, the premium constraint is
π = pc
If the insured would bring a suit in that case the expected utility would be
EU = (1 — p)U(y — π) + p[q U(y — π + c — k) + (1 — q)U(y — π — h + c — k)]
Analytical Approach
Our next approach to Machine learning will make use of text data and Algorithms. This will help to lower fraud, detect semantic relation patterns, and automatic categorization. It enables us to prioritize claims by scoring claims files as High, Medium, or Low based on recoverability likelihood. The scored cases will be sent to appropriate investigation and recovery experts. All this ensures that subrogation actions will be better informed and help assist insurers to eliminate instances of false or excessive pay-outs in the event of major claims. The goal is to learn pattern characteristics for claims with high subrogation potential through the analysis of textual notes of historical claims with known outcomes. To perform a joint analysis of patterns extracted from textual notes and structured attributes associated with the claim, a model is developed for predicting the subrogation potential of each claim. The created model enables the automated ranking of claims with respect to their subrogation potential. The ability to focus on claims with the highest subrogation potential enhances the efficiency of the work of human analysts and increases the recovery rate. An automated subrogation prediction system ensures the consistency of the analysis across all claims and across time. It helps minimize the number of missed subrogation opportunities. A good subrogation prediction model can discover a significant number of good subrogation candidate claims, which may be missed in the manual analysis.

Superior Data Integration
Pulling out data from different sources and transforming it to identify claims with the highest potential for subrogation recovery.
Variables we can create or use for the model:

Displaying the columns and data from the sample dataset. The data is at the claim id level from 2019 to 2022 with 48 features. (This is just a mock-up dataset created from open sources)

Let’s have a look at a sample of our unstructured data

We will augment our claims text data to uncover important aspects of the uninsured or underinsured claimant and thus use variables to build a machine learning model to understand the likelihood of paying the subrogation. Looking at the data, we can easily identify some of the keywords directed toward a potential accident.

We will move ahead with only unstructured data at the moment
We are now ready to begin modeling. The approach we like to take is to build a simple model as a baseline right away, then use that Model to compare more complicated methods. If we can’t achieve significant improvement over the baseline, it isn’t fruitful to use more complex models.
Here, we will start with the Logistic Regression model & some hyperparameters to see the performance. From that result, we’ll move to BERT and check if we have a superior model to play around with.
Our models work by collecting a plethora of different data inputs ranging. These inputs are then run through the models to detect anomalies within the claim, and also, we can apply the ran business rule to detect if high subrogation instances occurred automatically.
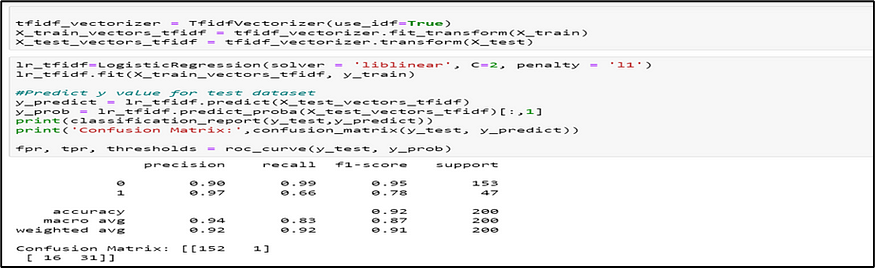
a. Logistic Regression
The Algorithm commonly deals with the issue of how likely an observation is to belong to each group. This model is commonly used to predict the likelihood of an event occurring with the logit function. This is a useful model to take advantage of for this problem because we are interested in predicting whether a claim is for subrogation (1) or not (0). Logistic regression predicts the outcome of the response variable (turnover) through a set of other explanatory variables, also called predictors.


b. BERT (Bidirectional Encoder Representations)
This deep learning model has given state-of-the-art results on a wide variety of natural language processing tasks. It stands for Bidirectional Encoder Representations for Transformers. It has been pre-trained on Wikipedia and BooksCorpus and requires (only) task-specific fine-tuning. It is basically a bunch of Transformer encoders stacked together (not the whole Transformer architecture but just the encoder). The concept of bidirectionality is the key differentiator between BERT and its predecessor.


Each line of the dataset is composed of the Claims report text and its label. Data preprocessing consists of transforming text to BERT input features: input_word_ids, input_mask, segment_ids/input_type_ids
· Input Word Ids: Output of our tokenizer, converting each sentence into a set of token ids.
· Input Masks: Since we are padding all the sequences, it is important that we create some sort of mask to make sure those paddings do not interfere with the actual text tokens. Therefore we need a generate input mask blocking the paddings. The mask has 1 for real tokens and 0 for padding tokens. Only real tokens are attended to.
· Segment Ids: For our task of text classification, since there is only one sequence, the segment_ids is essentially just a vector of 0s.
Explainability Of BERT
If we assume that our model can understand the context of the text very well with respect to what we are trying to predict, it will be wonderful. So, when we use models like BERT to understand the context of our text columns and investigate what aspect of language BERT is learning. It helps in verifying the robustness of our model. We will know what words are deemed important by our model in our text with models like BERT.
Let's look at a simple method of attribution approach, It scores the input data based on the predictions our model makes, i.e., it attributes the predictions to its input signals or features, using scores for each feature.
Integrated Gradients use the approach of feature * gradient. The gradient is the signal that tells the neural network how much to increase or decrease a certain weight/coefficient in the network during backpropagation. It relies heavily on the input features to do so. Therefore, the gradient associated with each input feature with respect to the output can help us get a clue about how important a feature is. Integrated Gradients allow us to attribute the selected output feature from the BERT model to its inputs.
We can generate word importance for each of the output features as below:-


How do we move forward from here .?
We would like to integrate various data sources and research possible ways to improve the model performance and get results closer to real-life scenarios. By using Google Street View (based on Collison date time & location) & Digital Identity Mapping for the Claimant. The model performance will be compared w.r.t holdout data and gauged the performance against one another to determine the most trustworthy predictors of claim subrogation.
At an enterprise level, we need to work with leaders & Experts from the claims department to introduce our model output into the claims process. It is usually for insurers to assign alerts to adjusters and to the subrogation specialists when the probability of subrogation exceeds a predetermined limit. Claims with slightly lower probabilities (5–20%) will usually be assigned a “watch” status, while claims with even lower probabilities (most claims) will get no message because a message on these claims is often seen as a distraction.
An API will be created to score claims, claims center will use the HTTPClient to call the REST Service. Also, configuration needs to be done for triggering events that initiate these calls.
Please feel free to share your opinions and thoughts.
Happy learning!
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


