



Trends in AI — August 2022
Last Updated on July 26, 2023 by Editorial Team
Author(s): Sergi Castella i Sapé
Originally published on Towards AI.
3% of Google’s new code is written by a Language Model, DeepSpeed for making inferences with a Trillion-scale Mixture of Experts, Beating neural scaling laws, prompting in Information Retrieval, Language Model Cascades, and much more.
While blockbuster research has slowed down slightly in the past month, probably because of the summer season, conferences are back at full speed in person: NAACL in Seattle, SIGIR in Madrid, and also ICML, for which we created a special guide with the help of GPT-3. Other news we’d like to highlight, to begin with are:
- Google shares how code generation is being used within the company. TL;DR almost 3% of all new code is generated by accepting suggestions from a Language Model, a suggestion acceptance rate of around 25%, a 6% reduction in coding iteration duration, and an average of 21 characters per accept.
- AI21 Labs raises $64M with ambitions to rival OpenAI. The company, founded and led by Yoav Shoham, Ori Goshen, and Amnon Shashua, will develop more sophisticated Language Models.
- Ian Goodfellow leaves Apple to join DeepMind under Oriol Vinyals, and Andrej Karpathy leaves Tesla after 5 years of leading its autonomous driving research division.
- Yolo-v7 was released… twice! There was a bit of a clash of names here: here’s the new paper and its implementation, and here’s also the YOLO-v7 project which has been under development for a few months longer and will now be renamed to a more generic YOLOvn.
- Nicola Richmond is the new VP of AI in Benevolent AI, a startup applying modern Deep Learning techniques for drug discovery.
- Meta AI releases Sphere, a web-scale corpus for better knowledge-intensive NLP, and here’s its GitHub repo. The dataset is curated as a subset of CCNet and aims to enhance research at the intersection between Natural Language Processing and Information Retrieval.
U+1F52C Research
Every month we analyze the most recent research literature and select a varied set of 10 papers you should know of. This month we’re covering topics such as Reinforcement Learning (RL), Scaling Laws, Information Retrieval, Language Models, and more.
1. Beyond neural scaling laws: beating power law scaling via data pruning
By Ben Sorscher, Robert Geirhos, Shashank Shekhar, Surya Ganguli, Ari S. Morcos.
U+2753 Why → Scaling laws¹ is a pervasive empirical phenomenon in modern Neural Networks, where the error is observed to off as a power of the training set size, model size, or both. While some have embraced this fact to devise a research agenda focused on scaling up, many think there must be ways to build better models without the need for outrageous scale. This paper explores a technique — data pruning — that can improve the learning efficiency of NNs “beating” scaling laws.
U+1F4A1 Key insights → In the context of this work, pruning refers to dropping training data samples from the training dataset, not pruning weights of the Neural Network. The intuition behind the method proposed is simple: imagine you could rank samples in a training dataset from “easy to learn” to “hard to learn” for a model. A typical dataset will contain too many of the easy-to-learn samples — that is to say, fewer would suffice to reach good performance on those samples — and too few from the hard-to-learn side — meaning you’d need more examples to train the model in properly.
One way of solving this problem is to scale up the whole training dataset because given enough scaling up — assuming the data distribution is uniform — you’ll get enough of the “hard to learn” samples eventually. But that’s very wasteful. What if we could use a priori to curate a training dataset that contains a better balance of easy-to-learn and hard-to-learn samples? This is what this paper investigates.
This problem can be formalized as trying to find a pruning metric to assign to each training sample (a proxy for its hardness), which is then used to prune the training dataset to the desired size. They propose a new metric in this paper that is comparable to existing work requiring labeled data.
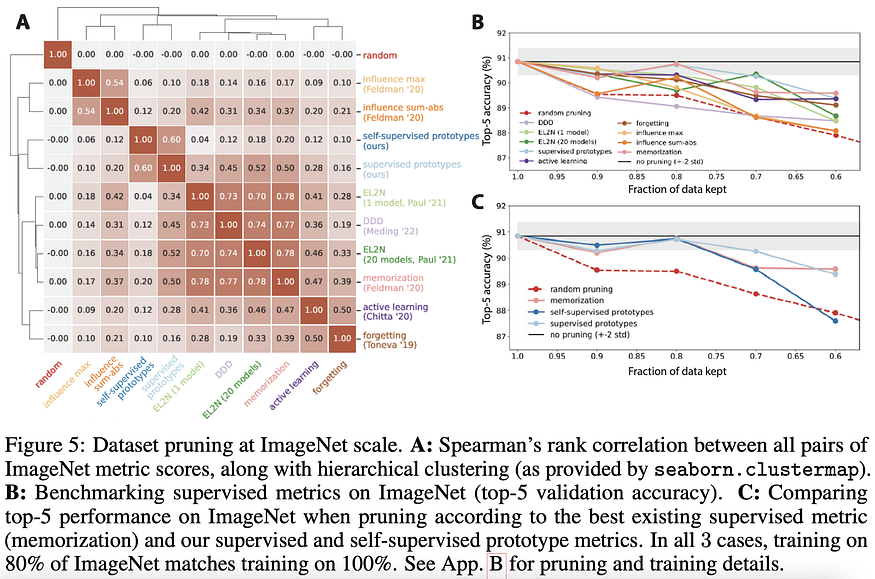
However, the most interesting contribution, in my opinion, is their section on data pruning without labels. They perform k-means clustering on the embeddings of a pre-trained ImageNet model and define the hardness of each sample as its distance to the nearest centroid: the intuition is that prototypical samples that are easy to learn will be closest to a centroid, whereas hard-to-learn samples will fall further away from their cluster centroids. The results show how around 20% of the training samples from ImageNet can be pruned without sacrificing performance.
To be fair, the results in the paper are not jaw-dropping, but the key ideas behind it have the potential to be useful in other tasks such as image segmentation, language modeling, or any other multimodal dataset curation.
2. Denoised MDPs: Learning World Models Better Than the World Itself U+007C Project Page U+007C Code
By Tongzhou Wang, Simon S. Du, Antonio Torralba, Phillip Isola, Amy Zhang, Yuandong Tian.
U+2753 Why → The world contains a lot of information that’s irrelevant for you to be able to navigate it. At the core of many Machine Learning techniques is the ability to discern relevant and useful signals — or patterns — from noise.
U+1F4A1 Key insights → This work formalizes the problem of separating “the good from the irrelevant information” in the context of reinforcement learning by identifying information that’s both controllable by the agent and relevant for the reward, as described in the figure below.
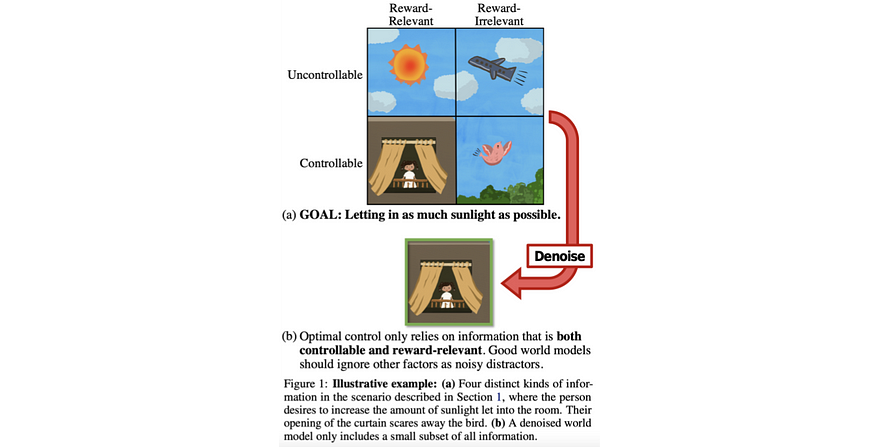
Based on this idea, the authors propose Denoised MDPs (Markov Decision Process), a method for learning a factorization of state representations that disentangles the controllable and reward-relevant bit of the state using information theoretic principles. The gist of it is that different factors of the state should be maximally or minimally predictive of other factors depending on their relationship, which enables the authors to set up a variational objective for the agent to optimize (you’ll need to check out the paper for the real mathy goodies).

The result is a world model that explicitly models what information should be discarded as noise and what information should be used for modeling the agent’s decisions. The authors prove how this approach is competitive in the DeepMind Control Suite, and fascinatingly, they showcase qualitatively how the Denoised MDP representations work by training a decoder on reconstructing the input so you can understand what the signal representation of the state learns to capture. You can watch those on their project page.

3. Parameter-Efficient Prompt Tuning Makes Generalized and Calibrated Neural Text Retrievers U+007C Code
By Weng Lam Tam, Xiao Liu, Kaixuan Ji, Lilong Xue, Xingjian Zhang, Yuxiao Dong, Jiahua Liu, Maodi Hu, Jie Tang.
U+2753 Why → Prompting has been making strides in NLP for the past couple of years, and now it also seems promising for Information Retrieval.
U+1F4A1 Key insights → Prompt tuning is a technique for adapting a pre-trained frozen model to a given task by adding trainable prompt tokens to the input of the sequence model. One of the main advantages of this approach with respect to the more common full model finetuning is that it only requires retraining a small subset of parameters which is much more efficient and also enables higher reusability of the original pre-trained model.
Now they train both a Dense Passage Retriever (retrieval by nearest neighbor search of query and doc embeddings) and a ColBERT⁴ type model with late interaction (includes joint modeling of query and document). The difference here is that instead of finetuning the whole model, they only finetune a prompt while keeping the pre-trained LM frozen. They base their implementation on the P-Tuning v² method, which is a more advanced form of prompt tuning where the trainable prompt is not only appended to the input but also at each layer of the Transformer.

The most interesting part of the results is that of generalization. While prompt tuning performs comparably to full fine-tuning on in-domain benchmarks, it outperforms substantially in various cross-domain datasets from the BEIR³ benchmark.

Yet again, this work strengthens the hypothesis that prompting and all its advantages are a viable alternative to fine-tuning and will probably keep increasing in popularity.
4. DeepSpeed Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale U+007C Code
By Reza Yazdani Aminabadi, Samyam Rajbhandari, Minjia Zhang, Ammar Ahmad Awan, Cheng Li, Du Li, Elton Zheng, Jeff Rasley, Shaden Smith, Olatunji Ruwase, Yuxiong He.
U+2753 Why → DeepSpeed — the framework for large-scale distributed training of large NNs developed and used by Microsoft — now also for inference besides training.
U+1F4A1 Key insights → The landscape of large Transformer architectures has diversified in the past year since the success of a sparse Mixture of Expert models in scaling up models in the Trillion parameter regime. The key advantage of these architectures is that they have increased expressive power from their larger sizes, but at inference time, only an input-dependent subset of the weights is used, which makes them more efficient (if the implementation is also optimized!). The downside is that training and running these models efficiently is more involved because most existing Deep Learning libraries and hardware were not designed with this type of computation.
While DeepSpeed was previously designed to enable training large Transformers, the latest update focuses on making inference faster both in latency and throughput on all kinds of Transmodels, including sparsely activated architectures.
We’re talking about a system that enables parallelism in heterogeneous hardware at a scale of hundreds of GPUs, CPU, and NVMe memory that enables high-speed inference even when large models can’t fit in aggregate GPU memory.

Let’s be honest, though, most people reading this article won’t ever have the need to use such a framework for training Trillion-scale models themselves, but it’s still a fascinating read if you’re interested in the engineering that goes behind training and running massive Neural Networks.
5. Language Models (Mostly) Know What They Know
By Saurav Kadavath et al.
U+2753 Why → Performance is far from the only desirable property of ML models. Accurately knowing how confident they’re in their outputs can be more important, especially in safety-focused applications.
U+1F4A1 Key insights → Calibration is the concept used in Machine Learning to indicate how well-tuned a model’s prediction confidence is (e.g. a perfectly calibrated model with an output with 90% certainty should be right 9/10 times, no less, no more).
This work first investigates the calibration of LMs answering questions by formulating the prompt in a multiple choice fashion where the output of the model is a single token with the answer. Given that a single token is an answer, the probability can be calculated directly from the model’s likelihood of that token, normalized over valid token answers (e.g. A, B or C).
While LMs are highly sensitive to prompt design and formatting, given an appropriate question formulation, large LMs are very well calibrated. Interestingly, this capacity breaks down at smaller scales (see figure below), and also at the tail of very low or very high confidence.

The paper dives into more modes of calibration comparisons and analysis than you’ll find in the paper, but the takeaway remains: LMs know what they know (are well calibrated), but results are still very vulnerable to prompt variations, and models need to be large enough.

6. Towards Grand Unification of Object Tracking (UnicornU+1F984) U+007C Code
By Bin Yan, Yi Jiang, Peize Sun, Dong Wang, Zehuan Yuan, Ping Luo, Huchuan Lu.
U+2753 Why → Decluttering and unifying Machine Learning model architectures have proven to be fruitful in NLP in the past few years, now time for video Computer Vision tasks.
U+1F4A1 Key insights → When it comes to video-related tasks, existing top-performing models still tend to rely on task-specific designs and overspecialize for their specific application as a result.
The authors propose a single model architecture that performs competitively in 4 modes for Object Tracking: Single Object Tracking (SOT), Multiple Object Tracking (MOT), Video Object Segmentation (VOS), and Multi-Object Tracking and Segmentation (MOTS).
This architecture is quite complex and is best understood through the figure below. In broad strokes, it starts with a unified backbone for embedding images, then a unified embedding is computed for the reference and current frame. A Transformer is used for the feature interaction between the unified embedding and the current frame to output class, box, and masks corresponding to all object tracking flavors.
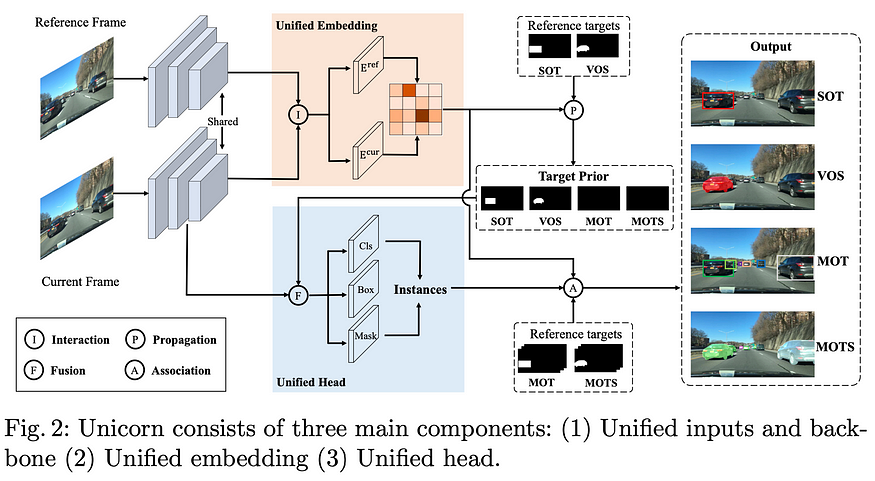
The system is benchmarked on several object tracking benchmarks such as LaSOT, TrackingNet, MOT17, BDD100K (and others) and sets new state-of-the-art performances in most of them.

7. Scaling Laws vs Model Architectures: How does Inductive Bias Influence Scaling?
By Yi Tay, Mostafa Dehghani, Samira Abnar, Hyung Won Chung, William Fedus, Jinfeng Rao, Sharan Narang, Vinh Q. Tran, Dani Yogatama, Donald Metzler.
U+2753 Why → Are we missing phenomena by benchmarking models at a particular compute/data scale? Yes.
U+1F4A1 Key insights → The authors perform hundreds of experiments across scales for a wide range of architectures: vanilla, efficient and advanced Transformers, MLP mixer, and Convolution-based models. The experiments consist of pretraining with autoregressive language modeling, which results in an upstream performance (language perplexity), followed by supervised fine-tuning on GLUE, SuperGLUE, and SQuAD (downstream performance).
The TL;DR is straightforward. While not the best option in all scale regimes, the vanilla Transformer shows the most robust and consistent performance scaling results across scales. Other useful tidbits of wisdom are:
- Convolution and MLP-based architectures do well on pretraining (upstream performance) but fail to transfer properly when finetuned. This points toward the importance of architectural inductive biases when it comes to transferring learning.
- Efficient Transformers only perform competitively with their full-attention counterparts in a certain scale regime and lag behind if scaled up sufficiently.

8. Discrete Key-Value Bottleneck
By Frederik Träuble, Anirudh Goyal, Nasim Rahaman, Michael Mozer, Kenji Kawaguchi, Yoshua Bengio, Bernhard Schölkopf.
U+2753 Why → As the benchmarking culture in ML slowly but surely shifts focus to out-of-domain generalization, inductive biases tailored for it will become more relevant.
U+1F4A1 Key insights → This method is part of a longer research agenda that we've highlighted before from Bengio's group (e.g. Coordination Among Neural Modules Through a Shared Global Workspace) focused on how introducing bottlenecks of information flow in architectures leads to representations that are robust and generalize better in an out of distribution sets. In this case, the proposed method consists of 3 steps:
- Encoding a high dimensional input (e.g. image) into an embedding with an encoder pre-trained on a large dataset.
- Splitting the embedding into C lower dimensional heads and finding the nearest neighbor from a set of predefined vectors which are frozen during training. Then use that nearest neighbor’s representation across heads to reconstruct the embedding. The discretized value codes are frozen during the training of the decoder.
- The decoder gets the reconstructed embedding as input and produces the task-specific output.
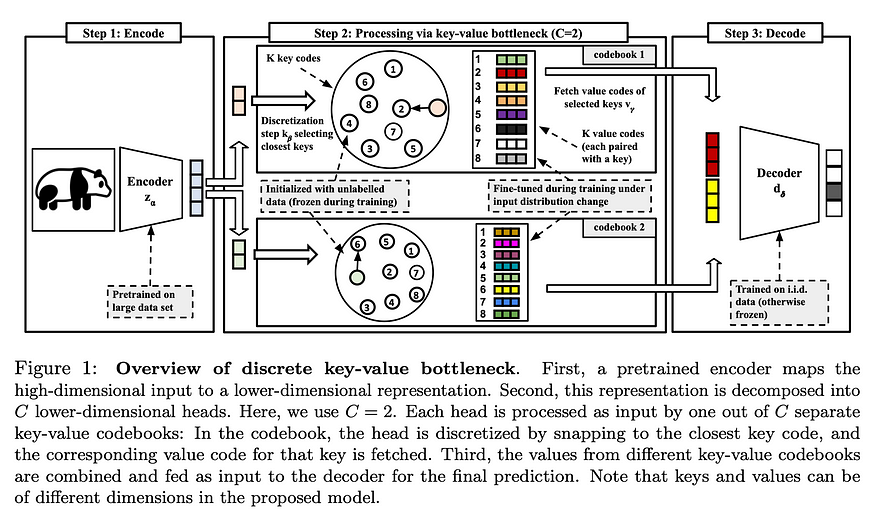
The experiments focus on the setting where a model is trained for one distribution and then adapted to a new one, as you can see in the figure below. The model is initialized by training on i.i.d. data, updating the decoder weights, and keeping the codebooks. When adapting the model to a distribution shift, the decoder is frozen, and only the codebook values are updated.

Their experiments prove how this approach reduces catastrophic forgetting and results in more robust predictions. This work will not have a big short-term impact — results are not groundbreaking — but some of these ideas could be key catalyst for the next leap in true generalization.
9. Language Model Cascades
By David Dohan, Winnie Xu, Aitor Lewkowycz, Jacob Austin, David Bieber, Raphael Gontijo Lopes, Yuhuai Wu, Henryk Michalewski, Rif A. Saurous, Jascha Sohl-dickstein, Kevin Murphy, Charles Sutton.
U+2753 Why → Large Language Models have become so powerful that they’re increasingly used as a black-box building block for other applications such as Reinforcement Learning or data augmentation.
U+1F4A1 Key insights → This work formalizes the interaction of Language Models from the lens of probabilistic programming: directed graphical models of random variables, which map to natural language strings. This turns out to be a powerful language to analyze existing advanced prompting techniques such as Scratchpad⁶ or chain-of-thought⁷. Moreover, it can be used to design new forms of interaction between LMs or advanced promoting techniques.
The practical value of this method is still a bit of a question, but it has the potential to be a powerful conceptual tool for building complex ML systems by abstracting away the classic Deep Learning toolbox (weights, embeddings, gradient descent, objective functions), creating the space for new higher-level mechanisms for reasoning.

ZeroC: A Neuro-Symbolic Model for Zero-shot Concept Recognition and Acquisition at Inference Time
By Tailin Wu, Megan Tjandrasuwita, Zhengxuan Wu, Xuelin Yang, Kevin Liu, Rok Sosič, Jure Leskovec.
U+2753 Why → Neurosymbolics delivering on its promise..?
U+1F4A1 Key insights → ZeroC is a method to represent concepts as graphs of constituent concept models (i.e. primary shapes like lines). The main objective of this paper is to build a system that can recognize unseen concepts at inference time. For instance, in the figure below, the letter F was not seen by the model, but it’s able to disentangle its components (lines) and their relationships (angle and positions), representing them as an explicit graph with 3 nodes and 3 edges.

The recipe for training such a system relies on Energy-Based Models (EBMs): feed positive and negative image/graph representation pairs and minimize the energy of positive pairs while accounting for the graph invariances of the representation. The experiments show success in modest gridworld environments where the primary shapes and relationships are quite simple, but this represents a first step toward learning structure-rich representations that could become useful in the context of few-shot learning and generalization.
References:
[1] “Scaling Laws for Neural Language Models” by Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, Dario Amodei; 2020.
[2] “P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks” by Xiao Liu, Kaixuan Ji, Yicheng Fu, Weng Lam Tam, Zhengxiao Du, Zhilin Yang, Jie Tang, 2022.
[3] “BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models” by
Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, Iryna Gurevych; 2021.
[4] “ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT” by Omar Khattab, Matei Zaharia; 2020.
[6] “Show Your Work: Scratchpads for Intermediate Computation with Language Models” by Maxwell Nye et al. 2021.
[7] “Chain of Thought Prompting Elicits Reasoning in Large Language Models” by Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, Denny Zhou; 2022.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts

")





