



Searching For Semantic Similarity!
Last Updated on January 6, 2023 by Editorial Team
Author(s): Shambhavi
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
This blog post is all about what we look for while making friends! Jokes apart, in this project, we will learn how to compute the similarity between a search query and a database of texts. We will also rank all the data according to their similarity score and retrieve the most similar text with its index.
Background
Before we jump into how the project works, it is of utmost importance to understand its applications and uses of the same. Practically, all day we run into similarity algorithms, some advanced and some very basic and useful, such as the cosine similarity. Techno-legal domain data, such as patents, work a lot with this task statement to conduct searches for overlapping technologies or inventions.
While search methods can either be corpus-based, the ones that rely on the larger corpora of information to draw semantics between the concepts, or, deep learning based, where neural networks are used to compute the embeddings as well as the distance. [1]
In this blog, we will discuss one example from both these methods as we understand how cosine similarity helps us in leveraging the distance information between these two different embedding approaches.
Dataset & Preprocessing
In our experiments, we look into the Stack Overflow Questions Dataset where we attempt to find similar questions to our query. The dataset contains 60,000 Stack Overflow questions from 2016–2020.
We use the function read_sc to read our search criteria which can be either entered as a string or as a path to the text file containing it, and the function is clean to load the input file into a dataframe.
Preprocessing the text plays a key role for corpus-based embeddings such as Word2Vec and fastText. While domain-specific processing techniques such as introducing contraction of text or expansion of abbreviations improve the algorithms, our data is comparatively clean, and thus we opt for the standard NLP preprocessing techniques.
The function below takes a string as input, removes punctuations and stopwords, and returns a list of tokens.
Now that we have understood how to take the input and preprocess it, let’s now discuss how to protect this data in the feature space, that is, creating the embeddings!
Exploring The Embeddings
Sentence-BERT
The algorithm uses the paraphrase-MiniLM-L6-v2 by HuggingFace for generating the embeddings, which is used for tasks like clustering or semantic search since it maps phrases and paragraphs to a 384-dimensional dense vector space. Instead of using sentence transformers which add to the slug size while deploying the model, we pass our input to the transformer model and then apply the right pooling operation on top of the contextualized word embeddings. This transformer model was also versioned with DVC.
sentence-transformers/paraphrase-MiniLM-L6-v2 · Hugging Face
FastText
But why use fastText when we already have all superior BERT-based embeddings in place, you ask? When it comes to long-form documents, nothing beats the good old fastText!
The sentence-Bert embeddings have a common limitation value of 512-word pieces, and this length can not be increased. But when we use corpus-based embeddings such as Word2Vec or FastText, we do not have any such limitation. FastText operates at a finer level using character n-grams, where words are represented by the sum of the character n-gram vectors, in contrast to Word2Vec, which internally utilizes words to predict words. And thus, we never run into the classic ‘out of vocabulary’ error with FastText, and it works well for several languages for which the words are not present in its vocabulary.
Calculating The Similarity With Cosine Similarity
As depicted in the illustration above, in the case of cosine similarity, we measure the angle between two vectors (or embeddings).
There are numerous other similarity measures, such as the Euclidean distance and Jaccard similarity. However, cosine distance performs better than these as it is not just a measure of common words or magnitude of overlap of the concepts but considers the orientation of vectors in the embedding space and thus even if the documents are of incomparable sizes, it can accurately calculate their similarity.
Above is the basic function to compute the cosine similarity between two vectors a and b for your reference. We explore Pytorch and Scipy-based cosine similarity functions in our code.
We compute the embeddings of the search text as well as the sentences in our dataset, and for sentence-bert, we utilize the util.pytorch_cos_sim function and for fastText, we use scipy.spatial.distance.cosine to calculate similarity between them.
Structuring the Code
We have a main.py file that takes the arguments such as model name, search criteria, a file containing all the data, name of the column from which you want to search the similar text. The main function calls one of the two classes defined for the BERT-based embedding and fastText embedding according to the argument you choose.
We can also understand the structure from the data pipeline below, where the data and model are being tracked by DVC. The similarity calculation files take input from the data directory and use helper functions from the src directory.
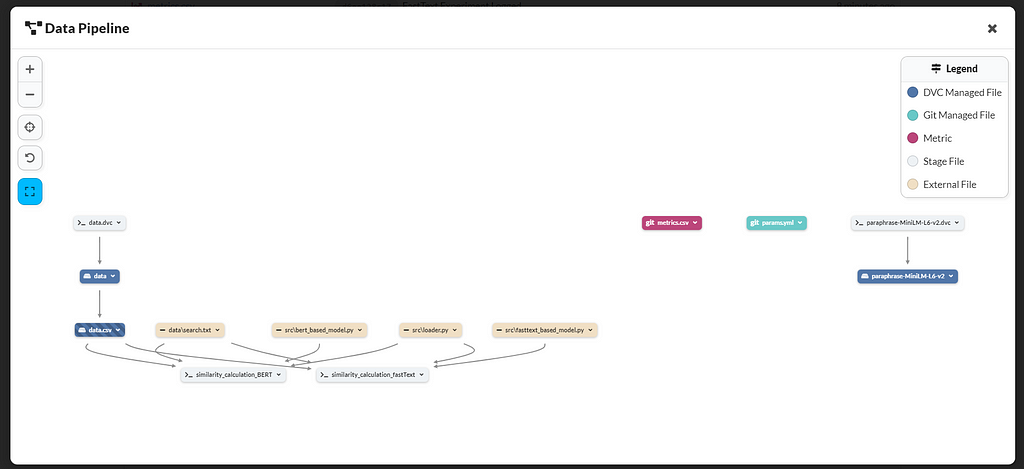
Analyzing The Algorithms
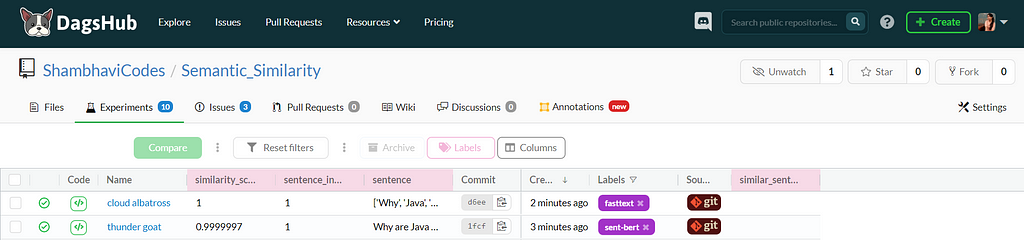
As we are not dealing with the traditional supervised learning problem where we train our model to log the accuracy and hyperparameters, a challenge was to decide how to log and evaluate the performance. While the models return a ranked output file in the order of their similarity to the search text, I also decided to log the most similar sentence scored by both models individually and its index to understand if the models capture the semantics in a similar fashion. An interesting comparison parameter could be computation time as well.
Let’s take a phrase and check the results!
Phrase: Why is Java Optionals immutable?
Both the algorithms return the same value where the selected match has nearly the same scores.
Now the Streamlit App!
To try out the project on your own, clone the repository and launch the app :
pip install -r requirements.txt
streamlit run app.py
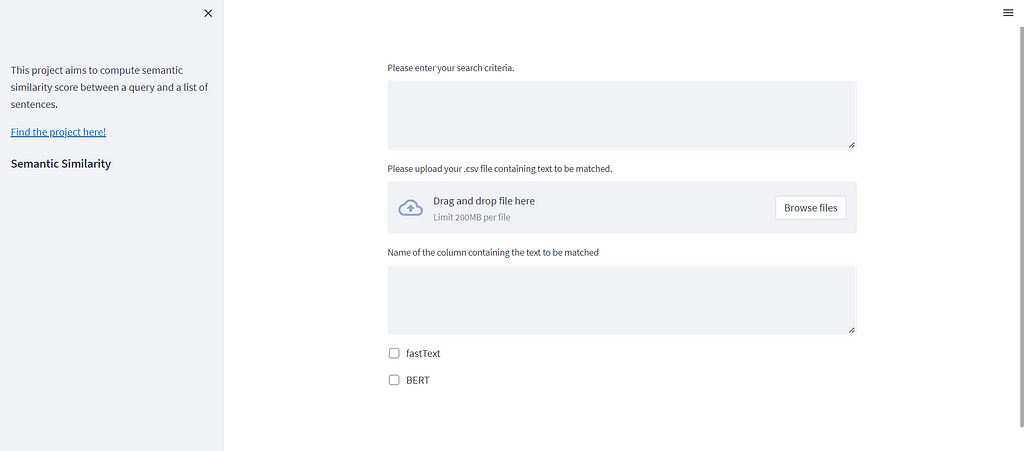
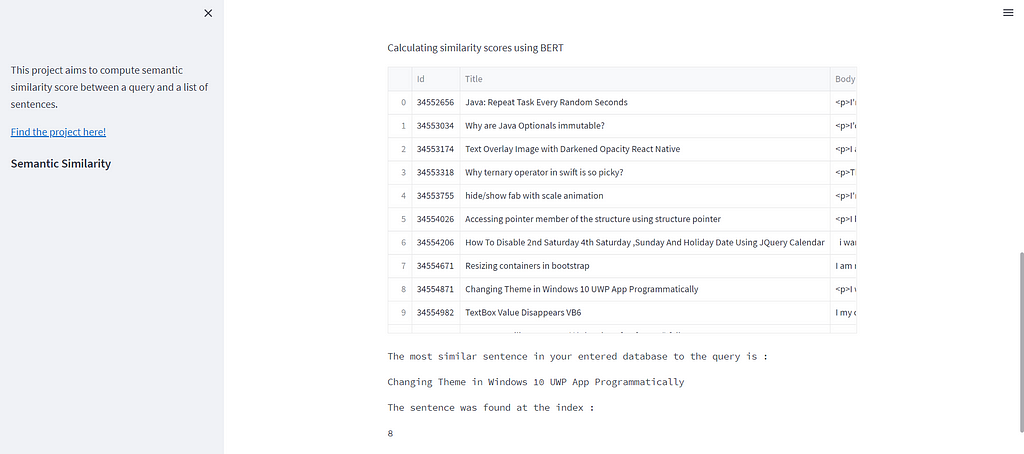
Simply enter the string of text which you want to look for and the ‘.csv’ file in which you want to look into. You will need to enter the name of the column and make a choice between the two models! Here’s how the output looks :
Streamlit is easy to use, for example, to input the data and run the calculation function, we use :
You can search through the components for the data type you need as input and output.
Deploying The WebApp On AWS EC2 Instance
We decide to deploy our app in an AWS EC2 instance, and this blog is the holy grail for it. There are 5 steps to launch your EC2 instance :
- Select an AMI (Amazon Machine Image), we go for the free tier eligible one!
2. Next, you need to choose an instance type.
3. Create and download an RSA type keypair.
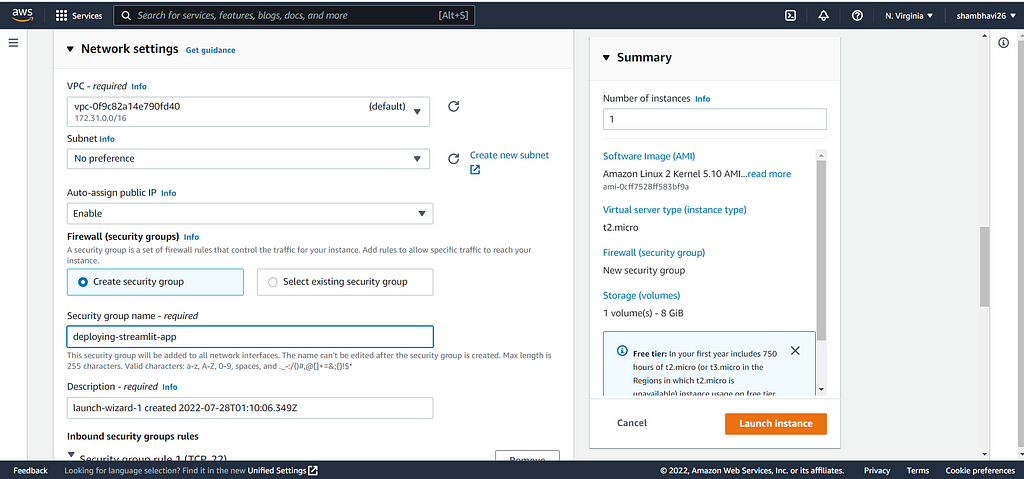
4. Now, we need to modify Network Settings and create a new security group. You need to name your security group and then add two new rules with the ‘Custom TCP’ type and set the port range as 8501 for one rule and 8502 for another.
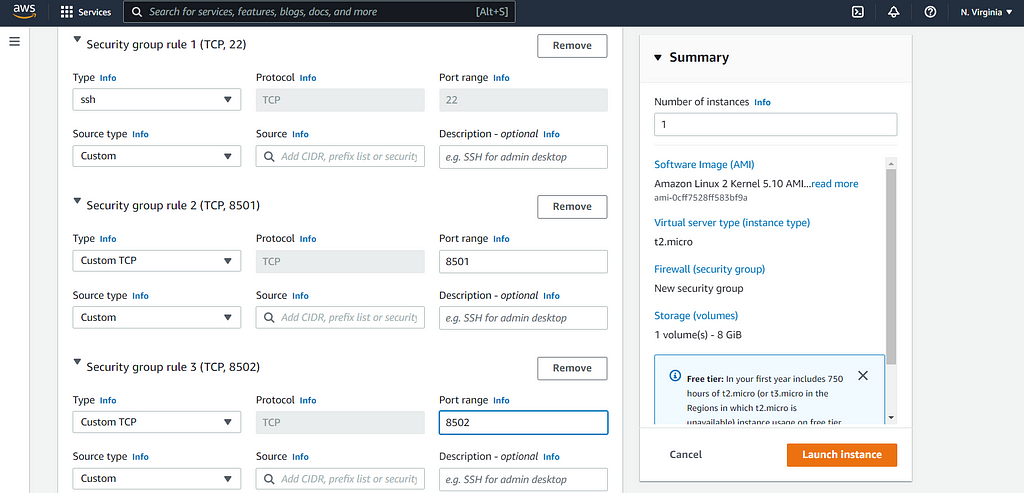
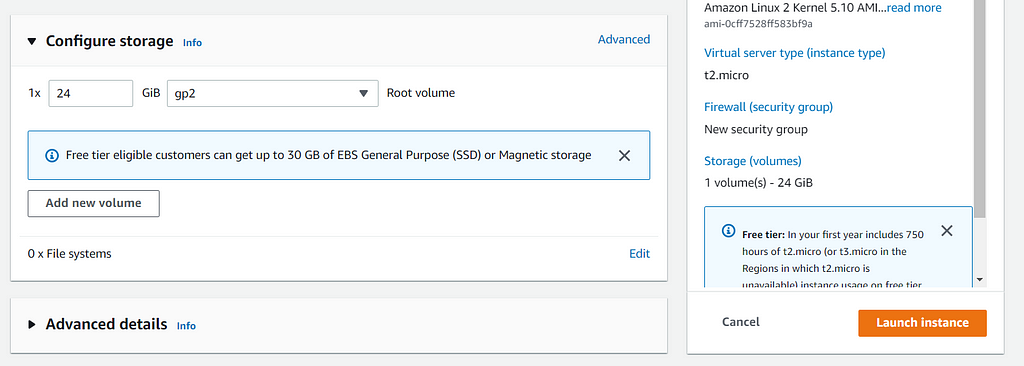
5. Now select the storage you require and launch the instance!
Now your instance is running!

I follow the easiest way to connect to this instance, and you can follow along. 🙂
Simply select the instance above and click to connect, and there you have the terminal right in front of you!
If you have followed so far, you already have your model and data pushed to DVC (and the dagshub repository), and all we need to do now is to pull the model using a simple script that prepares the EC2 instance and launches our app. The script I followed is the same as the blog referred to above :
You will also need a .yaml file with all these details :
You have everything ready, and these two commands will launch your app :
python prepare_ec2.py
streamlit run app.py
And voila! You have your end-to-end project running. Don’t forget to play around with the app.
For the complete code, check out this project :
ShambhaviCodes/Semantic_Similarity
Don’t forget to check out the issues and contribute, feel free to reach out to me for any questions and suggestions on LinkedIn or Twitter.
References :
- https://arxiv.org/pdf/2004.13820.pdf
- https://towardsdatascience.com/nlp-mlops-project-with-dagshub-deploy-your-streamlit-app-on-aws-ec2-instance-part-2-eb7dcb17b8ba
Searching For Semantic Similarity! was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


