



Trends in AI — April 2022
Last Updated on July 26, 2023 by Editorial Team
Author(s): Sergi Castella i Sapé
Originally published on Towards AI.
A monthly selection of ML research papers and news: NVidia’s new H100 GPU, 540 billion parameter PaLM from Google, Pathways, Kubric, Tensor Programs, Bootstrapping Reasoning With Reasoning, the Sparse all-MLP architecture, animating faces with Deep Learning, and much more.
Another month has passed in AI world and it has left a jam-packed tail of newsworthy announcements.
- The new NVidia H100 Tensor Core GPU was announced. Designed with modern neural architectures in mind such as Transformers, it achieves almost an order of magnitude speedups in training and inference.
- Inflection is the latest new big-shot company working on AI for human-computer communication by Reid Hoffmann (Linkedin co-founder), Mustafa Suleyman (Deepmind co-founder), and Karén Simonyan (AI Researcher).
- BigScience is a year-long collaborative research workshop to train a large multilingual language model from scratch from a community-driven approach. The training of the final 175 Billion parameter model is currently ongoing and you track to see its progress live.
- The Stanford AI index was published: an extensive 200+ page report on the current state of AI from the perspectives of research, industry, business, regulation, geopolitics, and more.
U+1F52C Research
We’ve analyzed the most recent research literature and created this editorial selection of 10 papers you shouldn’t miss on topics such as hyperparameter tuning, Reinforcement Learning, Language Modeling for reasoning, High-performance parallel computing, and much more.
1. Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer
By Greg Yang, Edward J. Hu et al.
U+2753 Why → Hyperparameter tuning is a make-it-or-break-it ingredient in the recipe for creating SOTA models. Unfortunately, for large models, this often requires an outrageous amount of computing resources, which further pushes away smaller players with limited resources. This work shows how hyperparameter tuning can be done more efficiently, which could be huge if true.
U+1F4A1 Key insights → In order to successfully train a neural network, one must choose suitable hyperparameters. Not that long ago, hyperparameters were only a handful (e.g. fixed learning rate, convolution kernel sizes, strides, etc.) but nowadays the hyperparameter space has grown to be much more complex: warm-up, scheduling of learning rate, optimizers, variable masking ratios, number of attention heads, hidden dimensionalities… and the list goes on and on.
You can shrink a NN in such a way that optimal hyperparameters will be invariant when you grow the network — or these will change predictably. This method enables finding optimal hyper-parameters in a small model and then growing the model to run the final resource-intensive training run. This method — called μTransfer—is rooted in theoretical analysis and provably works under certain conditions, but the authors also show empirically that this method can be applied in looser by growing using the technique on modern Transformers.

This method still has many limitations as the authors recognize themselves, but it sets an interesting direction to facilitate training of large models, even further optimization of existing models, or even enabling HP tuning of next-generation huger models in the multi trillion-parameter scale.
2. Visual Prompt Tuning
By Menglin Jia, Luming Tang, et al.
U+2753 Why → ML is clearly moving to a place where people won’t build models from scratch, but instead use pre-trained models to bootstrap your implementation. In this environment, techniques that squeeze the most out of large pre-trained models in downstream tasks while being computationally cheap will be key. Prompting is one such technique.
U+1F4A1 Key insights → The authors explore how various “partial tuning” techniques compare in terms of the percentage of tuned parameters/performance ratio. Until recently, large pre-trained models were finetuned by using labeled data and propagating the gradient across the whole architecture. However, in the past year, prompt tuning has emerged as a viable alternative: keep the pre-trained model weights frozen and prepend a set of embeddings into the input that can be learned through gradient descent and some labeled data.
This technique had proven to be effective on NLP tasks and is now being used for image classification, where it shows very competitive performance not only in terms of efficiency but also in absolute accuracy. Perhaps more importantly, prompt tuning shines the most in the few-shot regime, where full finetuning often struggles. An added benefit of prompt tuning is that it lets you conceptualize the pre-trained models as input/output black boxes, potentially enabling training a model that’s only accessible via API (either with gradient-free optimization⁷, or gradient descent whenever gradients are available), which is a direction the industry is moving towards.

Related: Delta Tuning: A Comprehensive Study of Parameter Efficient Methods for Pre-trained Language Models
3. Pathways: Asynchronous Distributed Dataflow for ML and PaLM: Scaling Language Modeling with Pathways
By Paul Barham et al.
U+2753 Why → If —big if— scale is truly all you need, the tooling for scaling things up massively will be an indispensable part of the future of AI, and this is Google’s version of it, along with its latest huge 540 billion parameter Transformer.
U+1F4A1 Key insights → This paper is Google’s blueprint for Pathways, “a large scale orchestration layer for hardware accelerators which enables heterogeneous parallel computations on thousands of accelerators while coordinating data transfers over their dedicated interconnects.”
Existing accelerator frameworks are good at running the same computation across different parts of the data in parallel which are later synchronized (aka Single Program Multiple Data, SPMD). Instead, Pathways is designed to be able to compute more heterogeneous computations in parallel (aka Multiple Programs Multiple Data, MPMD).

This enables training and hosting models like the just-released 540 Billion-parameter (dense) PaLM: Scaling Language Modeling with Pathways⁶, which is trained on 6144 TPU v4 chips across multiple pods. This dense model is the latest flagship by the company which achieves state-of-the-art in many zero, one, and few-shot NLP tasks, beating a lot of human baselines in the process.

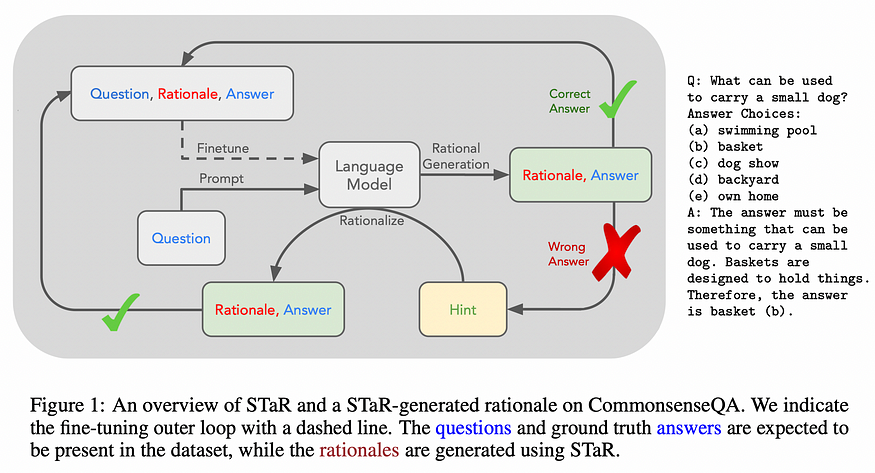
4. STaR: Selt-Taught Reasoner. Bootstrapping Reasoning With Reasoning
By Eric Zelikman, Yuhuai Wu, and Noah D. Goodman.
U+2753 Why → Logical reasoning is often mentioned as a weakness of large Language Models (LMs): while they might sometimes get it right, they often fail at basic common sense reasoning. This paper hints at a promising direction that could unleash the potential of plain language modeling for more advanced human-like reasoning.
U+1F4A1 Key insights → A rationale is an explicit logical explanation of why a belief is held or action is taken. While previous works had shown how explicit rationales can improve LMs performance in several scenarios⁵, this work shows how reasoning ability can be bootstrapped without relying on large-scale human-labeled annotations.
In this work, the authors only use a problem-solution corpus (without human rationales) but make the LM generate rationales for its answer, whenever the answer is correct those rationales are considered valid and trained accordingly. According to the authors, this is a synergistic process in which improvements in rationale generation improve the training data, and improvements in training data improve the rationale generation of the model. To prevent this process from saturating when the model fails to solve any new problems in the training data, the answer is provided to the model which then generates a rationale backward which is then added as training data.
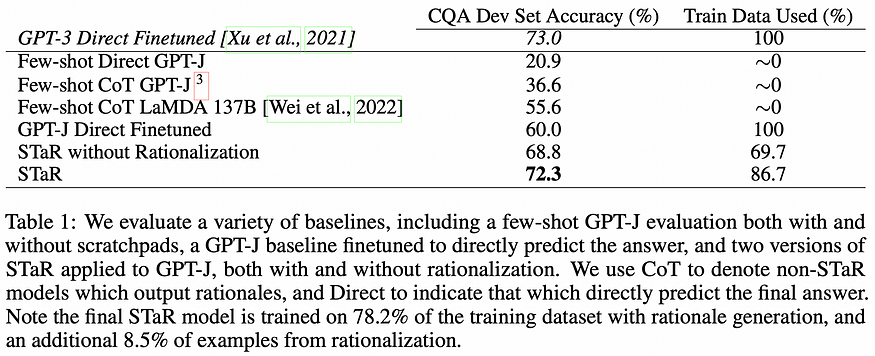
The experimental results are not very extensive but they clearly have signs for optimism: faster learning and on-par reasoning performance with the 30x larger GPT-3 model. Moreover, the STaR system clearly outperforms its vanilla rationale-free counterpart which is trained only on problem-solution pairs.
5. Do As I Can, Not As I Say (SayCan): Grounding Language in Robotic Affordances U+007C Project page
By Michael Ahn et al.
U+2753 Why → Lack of real-world grounding is a common critique of existing language models: how can any model have any meaningful understanding of language if it’s not combined with observation and interaction of other modalities like vision?
U+1F4A1 Key insights → A human user provides an instruction to the robot which can be long, abstract, or even ambiguous. The role of the LM is to disambiguate the instruction into shorter atomic steps. This is quite similar to previous work on using pre-trained Language Models to map high-level instructions into low-level actions¹⁰, but taking it a step further by including real-world robots enacting plans, instead of relying solely on simulations.

Another interesting recent work that uses pre-trained Language Models to guide learning representations for images is Integrating Language Guidance into Vision-based Deep Metric Learning.
6. Latent Image Animator: Learning to Animate Images via Latent Space Navigation
By Yaohui Wang, Di Yang, Francois Bremond, and Antitza Dantcheva.
U+2753 Why → Photorealistic animation with deep learning is pretty damn cool, and if it progresses it can become an enabling technology for applications such as gaming and VR.
U+1F4A1 Key insights → Existing Deep Learning based image animation frameworks often rely on structured representations of images: human key points, optical flows, 3D meshes, and so on. This work proposes a Latent Image Animator (LIA), which only relies on a self-supervised image autoencoder without any explicitly structured representations. Instead, they define a Linear Motion Decomposition which aims to describe movement in a video as a latent path via a linear combination of a set of learned motion directions and magnitudes.
The method consists of 2 models, an encoder and a generator. For training, 2 frames of the video are used as a self-supervised source of data that lets the model encode different views of a subject into its identity and decomposable motion parts, which the generator takes to output an image from which a reconstruction loss is derived. For inference, the source and driving image are replaced with different people, for which the model generates an output image with the identity of the source but the pose of the driving image.

7. Efficient Language Modeling with Sparse all-MLP
By Ping Yu et al.
U+2753 Why → Is the role of architectures in ML shrinking even further? I’d argue yes.
U+1F4A1 Key insights → Pay attention to MLPs¹ already showed us that “attention-free architectures” were competitive in language modeling, where information across tokens was propagated with a more rudimentary combination of MLPs. Now this work expands this idea to work in a sparse Mixture-of-Experts setting which has even stronger scaling behavior.
In this work, we analyze the limitations of MLPs in expressiveness and propose sparsely activated MLPs with mixture-of-experts (MoEs) in both feature and input (token) dimensions. Similar to previous “all MLP architectures” for vision², information across and within tokens is mixed is by applying Fully Connected (FC) layers tokenwise, then transpose/mix, and then applying the FC feature-wise (see figure below).

8. Kubric: A scalable dataset generator U+007C U+1F47E Code
By Klaus Greff et al.
U+2753 Why → When natural labeled data is hard or expensive to come by synthetic data can come to the rescue. Here’s the latest collaborative effort to build a library that enables the end-to-end creation of computer vision data.
U+1F4A1 Key insights → Data generation software is less mature than its modeling counterpart, which is why the authors argue that more efforts are required on the side of tooling for data generation. Kubric is an open-source Python framework that interfaces with PyBullet (physics simulation engine) and Blender (rendering engine) to generate photo-realistic scenes with fine-grain control and dense annotations.
A typical data generating pipeline (see figure below) combines fetching assets from an asset source, composing a scene with these assets as well as camera positioning, running physics simulation over the environment, and rendering it as different layers with the desired annotations and metadata.
The library is also designed to scale across distributed computing to generate large amounts of data in HPC environments. The authors showcase the library by creating 13 datasets with new vision challenge problems ranging from 3D NeRF models to optical flow estimation with benchmark results.

9. Training Compute-Optimal Large Language Models
By Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, et al.
U+2753 Why → BERT³ was a smashing success despite being massively underoptimized⁴, and new models being far from their true potential seems to be the rule not the exception when it comes to novel large Language Models. Are there optimization rules that can generalize and be applicable to a wide range of large-scale models to minimize this? It seems so.
U+1F4A1 Key insights → The axis of study here is model size and the number of tokens seen in pretraining: given a fixed computation budget, should you pre-train a bigger language model on not-so-many tokens, or pret-rain a smaller model on more tokens?
Interestingly, they find that compute-optimal scaling is pretty much scaling the model just as much as scaling the data. Largely speaking, existing works err on the side of training on two few tokens and having models that are too big. For instance, the authors show how a model 10x smaller than GPT-3 achieves performance parity when trained on a large enough corpus.
The resulting family of models is named Chinchilla.

10. Make-A-Scene: Scene-Based Text-to-Image Generation with Human Priors
By Oran Gafni et al.
U+2753 Why → Yet another step forward in the domain of controlled image generation.
U+1F4A1 Key insights → We’ve gotten used to text-guided image generation, especially since OpenAI’s DALLE⁸ rise to fame in early 2021. This work belongs to the same family of likelihood-based image generation on discrete tokens: learn discrete representations for image patches (using VQ-VAE⁹ or similar methods), and then do training and inference with an autoregressive prediction of next token with text-image pairs a la Language Modeling. There are 3 key novel components of this system that set it apart:
- Ability to add a scene (image segmentation) as part of the prompt.
- The use of a modified VQ-GAN⁹ model to learn high fidelity discrete patch representations which incorporate a perceptual loss.
- The addition of classifier-free guidance eliminates the need for post-generation filtering.
Check out their story showcase!
Other recent Computer Vision papers you might like about image segmentation are Unsupervised Semantic Segmentation by Distilling Feature Correspondences or Object discovery and representation networks.
References
[1] “Pay Attention to MLPs” by Hanxiao Liu et al. 2021.
[3] “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding” by Jacob Devlin et al. 2018.
[4] “RoBERTa: A Robustly Optimized BERT Pretraining Approach” by Yinhan Liu et al. 2019
[5] “Chain of Thought Prompting Elicits Reasoning in Large Language Models” by Jason Wei et al. 2022
[6] “PaLM: Scaling Language Modeling with Pathways” by Aakanksha Chowdhery et al. 2022.
[7] “Black-Box Tuning for Language-Model-as-a-Service” by Tianxiang Sun et al. 2022
[8] “Zero-Shot Text-to-Image Generation” by Aditya Ramesh et al.
[9] “Taming Transformers for High-Resolution Image Synthesis” by Patrick Esser, Robin Rombach, and Björn Ommer; 2020.
[10] “Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents” by Wenlong Huang, Pieter Abbeel, Deepak Pathak, and Igor Mordatch; 2022.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

