



Trends in AI — June 2022
Last Updated on June 9, 2022 by Editorial Team
Author(s): Sergi Castella i Sapé
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Trends in AI — June 2022
Multi-modal multi-task Reinforcement Learning from Deepmind’s Gato shell-shocked AGI predictions. DALLE·2 has new competition from Imagen by Google. Is reasoning with LLM’s around the corner when we ask them to “Let’s think step by step…”.? Plus Diffusion Models for Reinforcement Learning, a novel approach to apply GNNs for Vision, Understanding Grokking, and much much more…
As we go into June, the AI world doesn’t stop and once again the pace of new stories and research was high. The ACL conference was held in the past month in Dublin, being one of the first major conferences to go back in person, which certainly feels like another step forward into normalcy. Let’s start with some release highlights:
- Neutone is a new audio plugin community focused on connecting research and creativity. It lets researchers easily publish Machine Learning based audio processing plugins and audio creators can access them conveniently.
- RNNs still won’t surrender. BlikDL (an independent researcher) built a highly performant RNN without attention that competes with transformer-based models. Training can be parallelized making it more efficient, and inference still only relies on the previous hidden state
- An interesting discussion on the Machine Learning subreddit about whether you can trust papers out of labs. The core argument is that currently, labs with very skilled engineers will know how to squeeze every percent of performance such that the results in papers end up being a reflection of how good the people behind it are optimizing the process, but not so much a measure of intrinsic value of the proposed method.
🔬 Research
Every month we analyze the most recent research literature and select a varied set of 10 papers you should know of. This month we’re covering topics such as multimodality, Reinforcement Learning (RL), Diffusion Models, Information Retrieval, Prompting, and more.
1. A Generalist Agent | Blog post
By Scott Reed, Konrad Żołna, Emilio Parisotto, et al.
❓Why → We’ve been highlighting multimodality as one of the key pillars for the future of AI, exemplified by the recent generalist visual language model from Deepmind Flamingo⁴. This work, also from Deepmind, takes multimodality to the next level: one single model trained on vision, text,, and control (e.g. RL) data from hundreds of varied datasets.
💡Key insights → El Gato applies the usual recipe of a decoder-only Transformer (1.2B parameters) trained to predict the next token autoregressively. But now instead of language-only tokens, they serialize generic inputs into embeddings which can represent:
- Text, tokenized via SentencePiece with 32000-word vocabulary size.
- Image patches of size 16×16. These are embedded using a single ResNet, instead of using discretized image tokens like DALL·E 1.
- Discrete values such as Atari button presses are tokenized with values between 0 and 1023.
- Continuous values for control (e.g. joystick position in a videogame) are also discretized into tokens with values between 0 and 1023.
Many intricate choices are made to make sure all tasks can be represented in a sequence of embeddings (e.g. observation/action/separators for control policies) but the gist of it is relatively simple. Also, unlike text-only Language Models, Gato is mostly trained in a supervised setting where labeled samples from hundreds of datasets are drawn and fed to the model step by step to predict the next token. This means that for control problems such as Robotics or Atari games, Gato learns through behavior cloning, instead of actively interacting with an environment as it’s commonly done in RL settings.
The results convey that this is a feasible and successful approach, but not yet a SOTA-shattering for now. The resulting model can do things such as captioning images, keeping up with a conversation, and playing Atari games among others. Their analysis on scaling shows that their model is nowhere near maximal performance, so we expect similar approaches scaling up further to come out in the upcoming months!
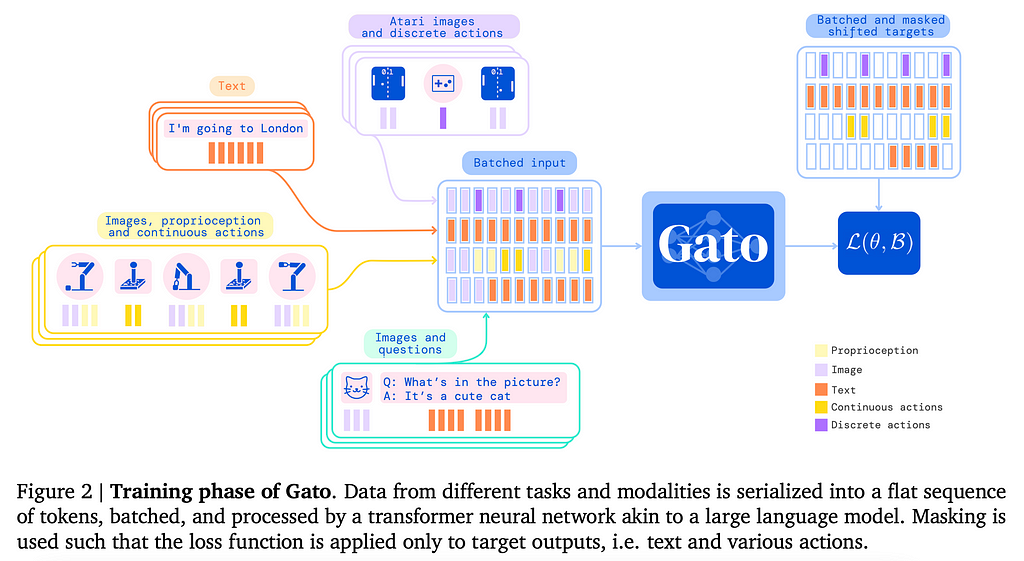
2. Planning with Diffusion for Flexible Behavior Synthesis | Project page | Code | Colab Notebook
By Michael Janner, Yilun Du, Joshua B. Tenenbaum, and Sergey Levine.
❓Why → Diffusion models, which have proven to be incredibly useful for image synthesis, are finding new avenues to shine, such as model-based RL.
💡Key insights → Existing model-based RL approaches often learn environment dynamics and then use a classical gradient-free trajectory optimizer for decision-making. Given that the learned environment dynamics are only an approximation, the trajectory optimizer might exploit the approximate dynamic weaknesses and come up with adversarial-esque trajectories which don’t translate well to the original environment, hurting performance.
This work leverages diffusion models to include the trajectory optimization as part of the learning process, mitigating the pitfalls of current trajectory optimizers, and aiming to achieve:
- Long-horizon scalability: training based on the overall trajectory accuracy instead of a single-step error, avoiding myopic failure modes.
- Task compositionality: a simple way to add auxiliary loss functions to condition the sampling of plans in the diffusion process.
- Temporal compositionality: achieving global trajectory consistency by imposing local consistency at each diffusion step.
- Effective non-greedy planning: model and planner being jointly optimized aims at a synergic interaction between the components instead of an adversarial one.
In broad strokes, consider a trajectory which is a causal sequence of {state, action} pairs. A diffusion process is applied to this sequence that gradually adds noise to each {state, action} pair, and then the model learns to reverse this process: starting from a trajectory that’s only noise, gradually refine it until it’s a good trajectory.
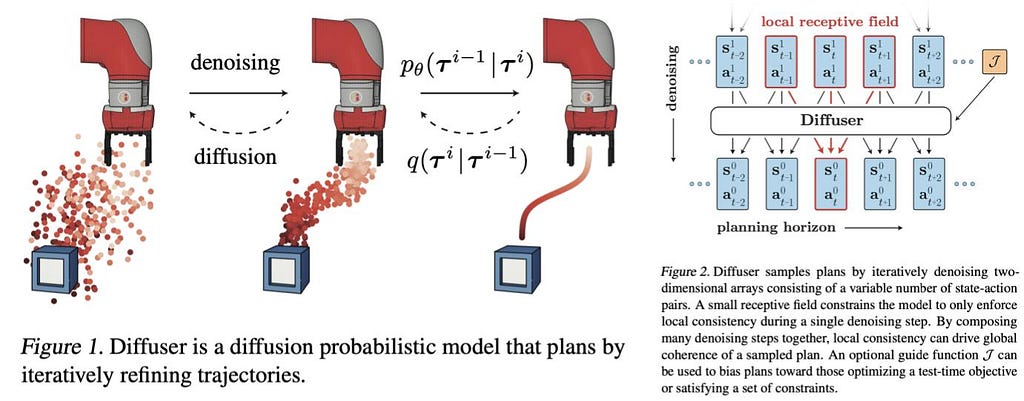
In their experiments, the proposed diffuser performs competitively with existing methods; but perhaps more interestingly, the trajectories that the model comes up with seem to satisfy the 4 goals mentioned above: long-term horizon planning, task, and temporal compositionality and non-greedy planning. You can check some video examples on their project page, check their code, or even play with a colab notebook.
This method represents an important conceptual departure from existing planners and has the potential to become a fertile ground for new research.
3. Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
By Chitwan Saharia, William Chan et al.
❓Why → DALL·E 2 from OpenAI² was arguably the biggest highlight from April, as it pushed the boundaries of how complex and realistic image generation can be, sparking an intense debate around the capabilities and limitations of such models. Now Google has published a model that rivals DALL·E 2: Imagen. While nobody rivals the OpenAI marketing genius, this is also a work with paying attention to.
💡Key insights → This approach called Imagen is similar to DALL·E 2 in that it uses a Diffusion Model for image generation, but it’s different from it in how it represents prompts and how it achieves high-resolution images.
The text representation comes from a text-only frozen language model (T5), and the image generation is performed by a diffusion model (as usual at this point) with two super-resolution upsampling steps, up to 1024×2014. It uses training techniques such as classifier-free guidance which lets it learn both conditional and unconditional generation. Another technique introduced is dynamic thresholding, which prevents the diffusion process from saturating in certain regions of the image, which is a phenomenon that hurts image fidelity especially when the weight on the text conditional generation is high.
In terms of results, they achieve state-of-the-art on the COCO dataset with a zero-shot FID score of 7.27, even better than DALL·E 2. Still, objectively evaluating image generation is challenging so take these numbers with a grain of salt. Generally speaking, the generation seems on par with that of DALL·E 2, but we would need to interact at length with both systems to get a better sense of how they compare, which is not currently possible.
One of the key findings from this paper is the fact that such representations are surprisingly effective despite not being trained in a multimodal way like CLIP [10]. Moreover, they find that increasing the size of the pre-trained language model improves image generation more than increasing the size of the diffusion model that generates images.
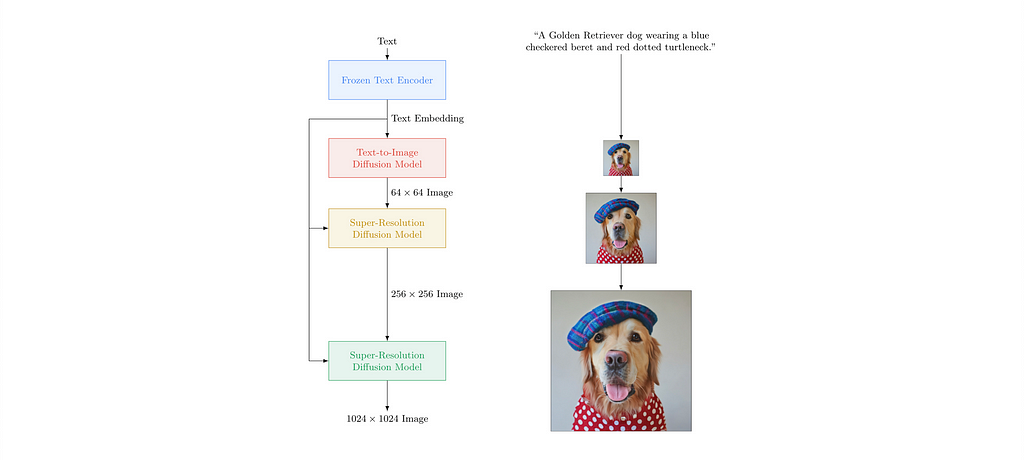

4. Large Language Models are Zero-Shot Reasoners
By Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, Yusuke Iwasawa.
❓Why → An unbelievably effective and simple hack for prompting language models.
💡Key insights → This paper basically discovers that adding the simple phrase “Let’s think step by step” to the prompt of GPT-3 and other similar models dramatically improves reasoning performance. This is a finding that goes in line with Chain of Thought prompting (CoT)⁹, which showed how reasoning and factual accuracy can be improved in one-shot learning by explicitly unpacking the reasoning as part of the natural language prompt. The figure below succinctly illustrates how all these techniques relate to each other.

Upon such discovery, the authors propose a zero-shot-CoT which is a template to elicit a type of chain of thought reasoning in a zero-shot setting, without requiring a handcrafter chain-of-thought prompt as it was done previously. For instance, the template can be adding first the “Let’s think step by step” prompt suffix, use the output of the model as a chain of thought and then perform answer extraction by adding another prompt suffix such as “therefore the answer in Arabic numerals is”, running the model for one final inference step.
The results show how big of a difference simple choices of templates and prompts make. It’s still fascinating how after 2 years of the release of GPT-3, so much low-hanging fruit is still waiting to be collected in the space of prompting.
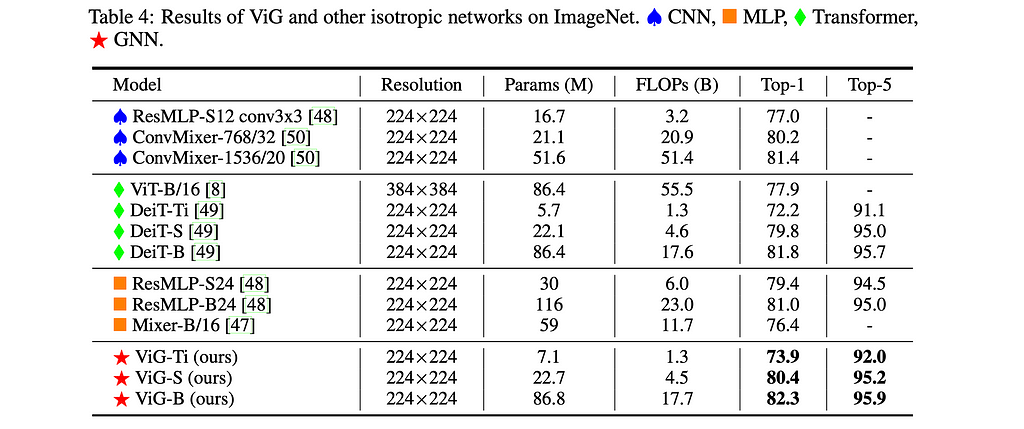
5. Vision GNN: An Image is Worth Graph of Nodes
By Kai Han, Yunhe Wang, Jianyuan Guo, Yehui Tang & Enhua Wu.
❓Why → We often assume images should be canonically represented as a grid of pixels. What if we represented them as graphs?
💡Key insights → This paper proposes Vision GNN (ViG), an architecture to extract graph-level features for visual tasks. The graph representation of an image is simply obtained by dividing an image into patches, embedding those patches, and constructing a graph where edges represent nearest neighbors in the embedding space. This graph is then fed into a GNN consisting of a clever combination of Graph Convolutions (GCNN), linear transformations, and activation functions that avoid the common pitfalls of GCNNs such as over-smoothing.
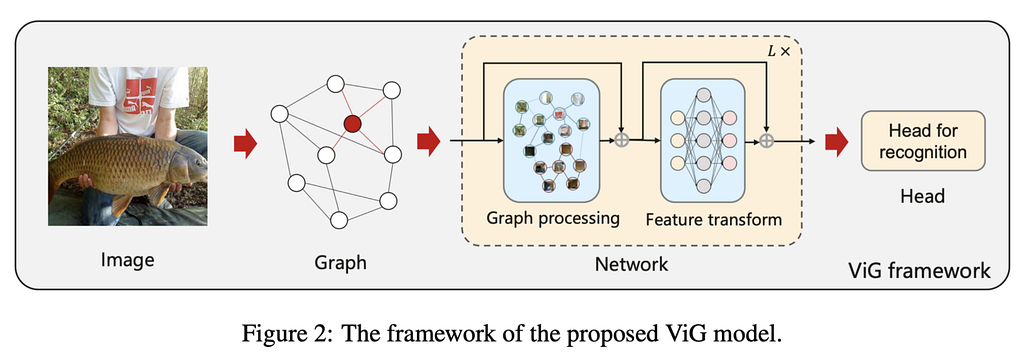
Similar to classical ResNets, the authors find that the GNN benefits from a “pyramid structure”, where spatial features are iteratively aggregated into deeper features that combine information from an increasingly large neighborhood of the image/graph.
The results on Imagenet are either SOTA or comparable to existing ResNets⁵, ViTs⁶, or MLP-based⁶ architectures. Once again, this reinforces the growing suspicion that specific architectures in Deep Learning matter less than we used to believe, and scale and data are instead of the main drivers of performance.
6. Unifying Language Learning Paradigms
By Yi Tai, Mostafa Dehghani et al.
❓Why → Self Supervised Language Modeling based pretraining is now the bread and butter of NLP. Still, different flavors of this technique exist, empirically showing complementary strengths and weaknesses. Wouldn’t it be nice to get the best of all of them?
💡Key insights → Consider the following taxonomy for existing LM pretraining methods:
- Vanilla or causal Language Modeling. “Predict the next token” where each token can only attend to preceding tokens.
- Prefix Language Modeling: “Predict the next token” but now all input tokens can attend to each other.
- Span corruption, Masked Language Modeling (MLM), or bidirectional language modeling. “Fill in the gaps”, where all tokens can attend to all tokens.
While autoregressive LMs excel at text generation and prompting, MLM is better at extracting powerful general-purpose representations of language. The unification of pre-training tasks can be understood through the perspective of denoising an “input-to-target” task: a model learns to reconstruct a corrupted input and predict a target. By defining different qualitative types of denoising combining long and short spans in the input and target domain, the resulting objective function combines the qualities of the different objectives we described initially.
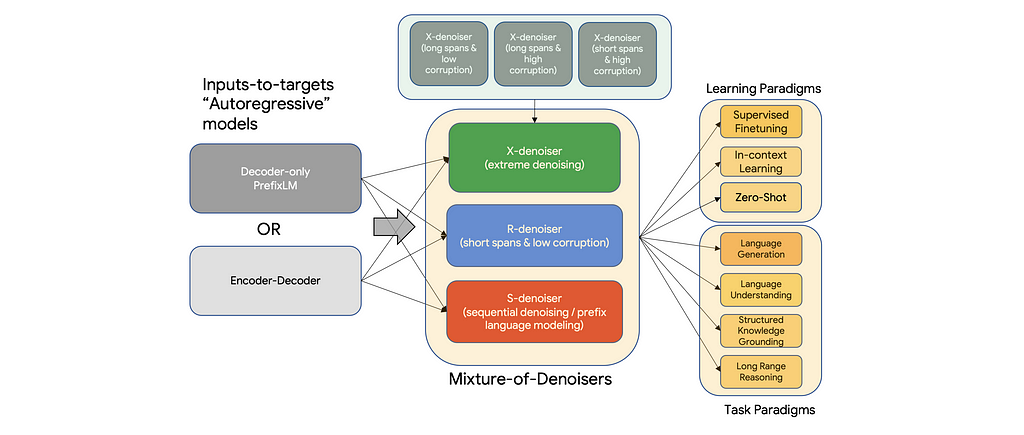

In grossly oversimplified terms, R-denoiser mimics the T⁵⁸ learning objective, S-denoiser is GPT-like and X-denoiser is a combination of both.
The result is a model that can successfully operate both in the supervised finetuning and one-shot prompting paradigms. When compared to previous learning objectives in isolation, UL2 often outperforms them, although not universally across the board. This is a promising direction for future foundation models as a service that can simultaneously be used to (1) generate powerful general-purpose embeddings of text and (2) solve zero-shot tasks via prompting and text generation a la GPT.
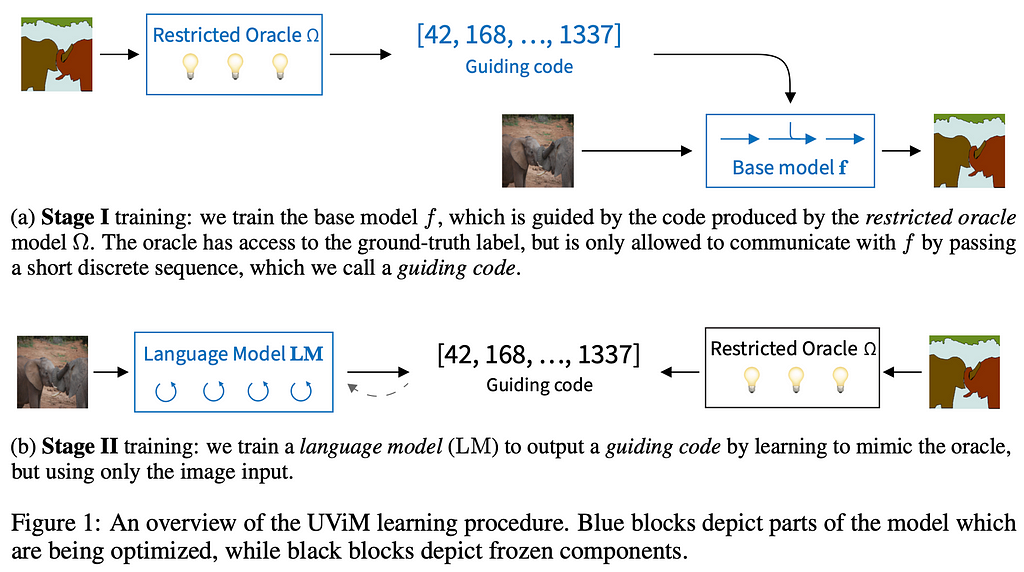
7. UViM: A Unified Modeling Approach for Vision with Learned Guiding Codes
By Alexander Kolesnikov, André Susano Pinto, Lucas Beyer, Xiaohua Zhai, Jeremiah Harmsen, and Neil Houlsby.
❓Why → While NLP has seen a unification of techniques across tasks with pretraining based on language modeling and Transformers, Computer Vision (CV) still remains more fragmented in terms of architectures and methods for different tasks such as object segmentation, coloring, inpainting or depth mapping.
💡Key insights → A base model learns a pixel-level output given an input image. Traditionally, pixel-level dependencies are hard to model so task-specific inductive biases are often introduced in the learning process.
This work proposes to instead introduce an auxiliary restricted oracle model whose objective is to guide the training of the base model across a wide range of pixel-level CV tasks. This restricted oracle takes the ground truth output (e.g. a per-pixel segmentation map) and generates a short sequence of discrete tokens which contain useful information about the task at hand. The intuition is that by jointly optimizing the base model and the restricted oracle, the oracle will find ways to aid the predictions of the base model, enabling it to learn more efficiently complex tasks without requiring task-specific design choices. Note that during training, the model doesn’t purely perform prediction because the information from the ground truth label is purposefully leaked into the model via the guiding code.
While the results are not challenging the state of the art, it proves that the restricted oracle guidance improves the performance of the base model and is a viable research direction for more generic vision methods.
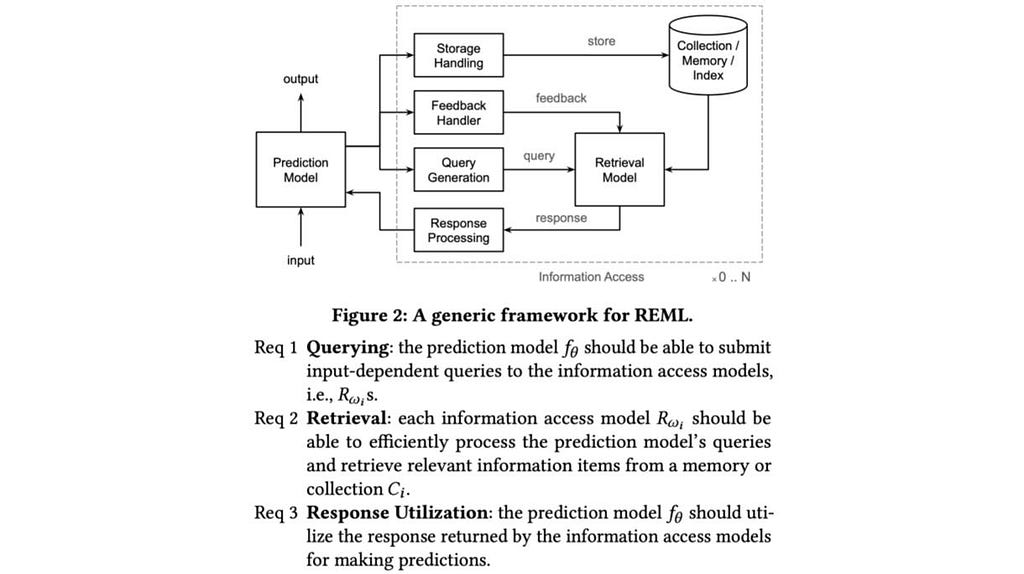
8. Retrieval-Enhanced Machine Learning
By Hamed Zamani, Fernando Diaz, Mostafa Dehghani, Donald Metzler, and Michael Bendersky.
❓Why → Relying on growing the parameter count to improve the performance of the ML model seems successful but is also brittle, unsustainable, and opaque. Recent works combining IR and Language Models display a much more promising parameter efficiency while being more generalizable, scalable, interpretable, and robust.
💡Key insights → Previous works this year such as Web-GPT (OpenAI), RETRO (Deepmind) or LaMDA (Google), already showcased how language models that interacted with a retrieval model displayed better parameter utilization and robustness; with the added benefit of being able to add information to the system without the need to retrain the whole model.
This is a very useful position paper that lays out the conceptual foundations of ML models that interact with retrieval systems. A retrieval-enhanced ML model is simply a machine learning predictive model which interacts explicitly with a memory module that can be queried for information through a retrieval model (see figure below).
The authors also provide examples of case studies as potential avenues where retrieval enhanced ML is being investigated and shows a promising future. These include knowledge grounding, memory augmented ML, retrieval enhanced input representation, and generalization through memorization.
9. A Modern Self-Referential Weight Matrix That Learns to Modify Itself
By Kazuki Irie, Imanol Schlag, Róbert Csordás, Jürgen Schmidhuber.
❓Why → Meta-learning (aka learning to learn, and learning to learn, and so on) has long been one of those ideas in AI whose importance appears self-evident in the abstract, yet has proven hard to popularize. While this work first appeared earlier this year in February, it has recently been accepted at the ICML conference and generated more discussion.
💡Key insights → This is a work that applies modern techniques to dust off a meta-learning idea dating back to 1991 from Schmidhuber’s group. The motivation for this line of work can be best understood through Schmidhuber’s blog post covering the historical context on meta-learning.
The idea is to reconceptualize many of the multi-head attention used in Transformers as a combination of fast and slow NNs (or weight matrices), where the purpose of the slow NN is to modify a fast NN, which becomes a more general formalism to build NNs that can meta-learn (i.e. that can “improve themselves” in a virtuous cycle).
They test the approach in supervised learning (especially few-shot) and multitask reinforcement, showing that this is a viable technique, though not achieving jaw-dropping performance.
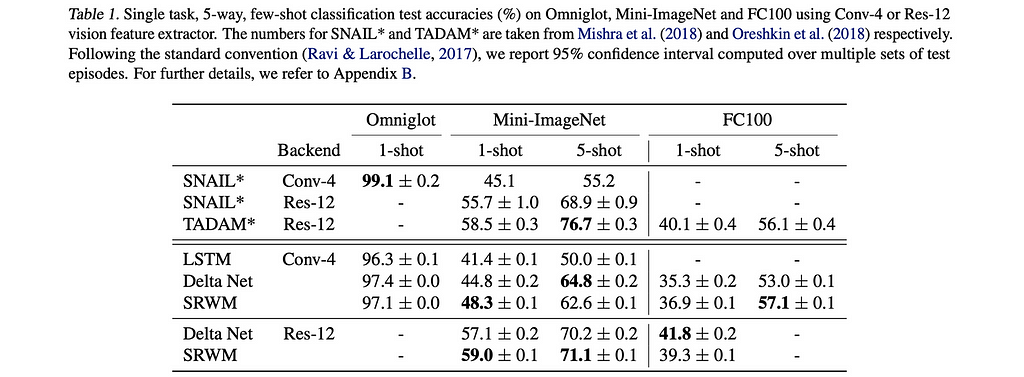
To be honest, I’m somewhat skeptical about how useful it is to revisit existing methods under alternative terminologies and abstractions that relate to older methods: at the end of the day this is arguably not all that different from multi-head attention. It can feel like an unnecessary obfuscation of the contributions of the paper. Still, seeing the same thing in a new light can reveal valuable novel insights, so this is after all a challenging but worthwhile read!
10. Towards Understanding Grokking: An Effective Theory of Representation Learning
By Ziming Liu, Ouail Kitouni, Niklas Nolte, Eric J. Michaud, Max Tegmark, and Mike Williams.
❓Why → Using the physics toolbox with effective theories and phase diagrams to understand a puzzling phenomenon that Neural Networks exhibit: grokking.
💡Key insights → Grokking is a puzzling phenomenon that NNs can exhibit where they drastically generalize to the test set way after overfitting the training set³. This has been shown on algorithmic datasets — e.g. learning binary operations between integers — which hold out certain combinations from the training set and use them on the test set to determine generalization.
Often used in physics, an effective theory is a descriptive model of a certain phenomenon that doesn’t claim to reflect any true underlying causal structure of said phenomena.
To construct an effective theory of representation learning, this paper lays out a definition of structure based on the geometry of the embedding space. Based on this, it analyzes how big of a training set is needed to recover the underlying structure of an algorithmic dataset such that the model generalizes to the test set.
The representation learning phases are defined as 4 regimes of learned representations in NNs:
- Comprehension: both training and test performance improve simultaneously.
- Grokking: training and test performance are high, but generalization happened after training performance plateaued.
- Memorization: training performance is high but test performance is low.
- Confusion: both training and test performance are poor.
Then, phase diagrams can be drawn for various hyperparameters of choice such as representation encoder/decoder learning rates, or train/test split ratio among others. Interestingly, their effective theory correctly predicts the boundary conditions for phase transitions for parameters such as train/test data split.
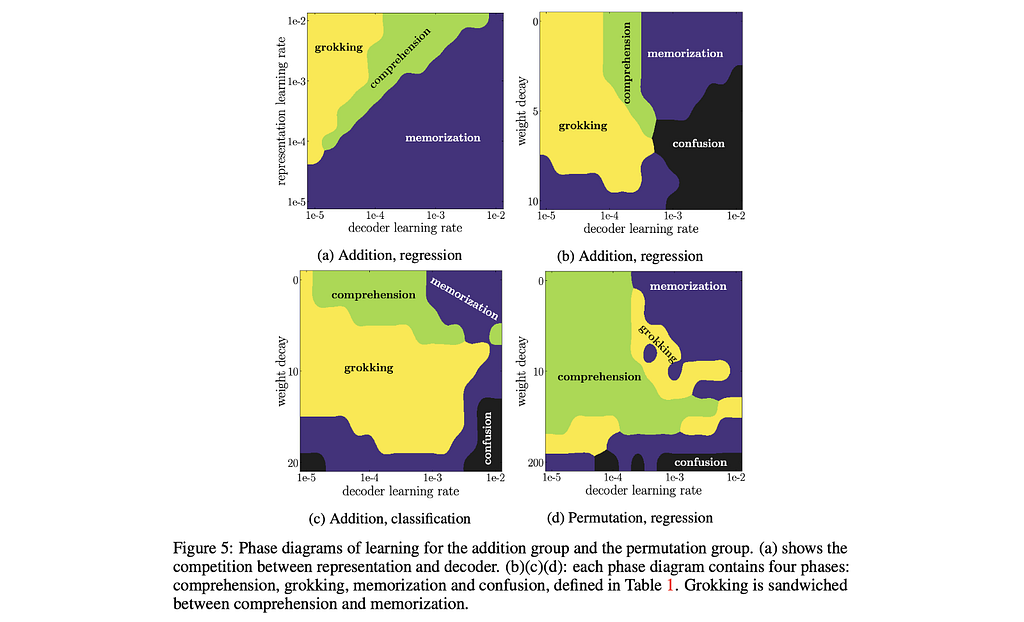
Most of the results in the paper come from algorithmic datasets in toy settings, but the authors conjecture that the analysis in the training dynamics will hold for more general cases and provide a simple example with a Transformer. Even if that’s a hopeful assumption, it’s useful to learn new grounded abstractions that help to intuitively conceptualize complex phenomena, which is something physicists excel at.
Moreover, understanding complex emergent phenomena from NNs is very helpful in efficiently developing increasingly large models, where sweeps across design choices and hyperparameters are unfeasible computationally.
References
[1] “Perceiver: General Perception with Iterative Attention” by Andrew Jaegle, Felix Gimeno, Andrew Brock, Andrew Zisserman, Oriol Vinyals, Joao Carreira, 2021.
[2] “Hierarchical Text-Conditional Image Generation with CLIP Latents” by Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, Mark Chen, 2022.
[3] “Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets” by Alethea Power, Yuri Burda, Harri Edwards, Igor Babuschkin, Vedant Misra, 2022.
[4] “Flamingo: a Visual Language Model for Few-Shot Learning” by Jean-Baptiste Alayrac et al. 2022.
[5] “Deep Residual Learning for Image Recognition” by Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, 2015.
[6] “An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale” by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby, 2020.
[7] “MLP-Mixer: An all-MLP Architecture for Vision” by Ilya Tolstikhin, Neil Houlsby, Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Thomas Unterthiner, Jessica Yung, Andreas Steiner, Daniel Keysers, Jakob Uszkoreit, Mario Lucic, Alexey Dosovitskiy, 2021
[8] “Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer” by Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu, 2019.
[9] “Chain of Thought Prompting Elicits Reasoning in Large Language Models” by Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, Denny Zhou, 2022.
[10] “Learning Transferable Visual Models From Natural Language Supervision” by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever, 2021.
Trends in AI — June 2022 was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






