



The NLP Cypher | 03.21.21
Last Updated on July 24, 2023 by Editorial Team
Author(s): Ricky Costa
Originally published on Towards AI.
NATURAL LANGUAGE PROCESSING (NLP) WEEKLY NEWSLETTER
The NLP Cypher U+007C 03.21.21
The Field of Reeds
Hey, welcome back! Let’s kick off the newsletter with a lucid sonic dream from a very crafty GAN U+1F635U+1F344. But wait, what is that exactly? For direct experience check out the video below. TL;DR: a savvy dev trained a GAN to generate acid-trip art that transitions in sync with music. This isn’t NLP related but hey, still cool! Here’s the library, it runs on TF-v1, now go get a wav file and play some Pink Floyd:
mikaelalafriz/lucid-sonic-dreams
Lucid Sonic Dreams syncs GAN-generated visuals to music. By default, it uses NVLabs StyleGAN2, with pre-trained models…
github.com
Surprise Colab:
Google Colaboratory
Edit description
colab.research.google.com
If you enjoy this read, please give it a U+1F44FU+1F44F and share with friends… U+1F60E
TensorFlow Transformers Library U+1F440
pip install tf-transformers
Just when you thought you’ve seen it all, a library comes along that augments the capability of TensorFlow v2 focusing on NLP. The authors make impressive claims, here are the highlights (from their repo):
- Faster Auto Regressive Decoding using Tensorflow2. Faster than PyTorch in most experiments (V100 GPU). 80% faster compared to existing TF based libraries (relative difference) Refer benchmark code.
- Complete TFlite support for BERT, RoBERTA, T5, Albert, mt5 for all down stream tasks except text-generation.
- Faster sentence-piece alignment (no more LCS overhead).
- Variable batch text generation for Encoder only models like GPT2.
- No more hassle of writing long codes for TFRecords. minimal and simple.
- Off the shelf support for auto-batching tf.data.dataset or tf.ragged tensors.
- Pass dictionary outputs directly to loss functions inside
tf.keras.Model.fitusing model.compile2 . Refer examples or blog. - Multiple mask modes like causal, user-defined, prefix by changing one argument . Refer examples or blog.
Model Support: ALBERT, BERT, RoBERTa, GPT-2, MT5, ELECTRA and T5.
They even include code to switch from Hugging Face to their library: MORTAL KOMBAT U+1F976…
legacyai/tf-transformers
State of the art faster Natural Language Processing in Tensorflow 2.0 . – legacyai/tf-transformers
github.com
GitHub
legacyai/tf-transformers
tf-transformers: faster and easier state-of-the-art NLP in TensorFlow 2.0 tf-transformers is designed to harness the…
github.com
C4: 800GB of English Text Released Into the Wild
Google’s C4 dataset has been in a full quarantine. They never offered the option to download it, we could only replicate it. However AllenNLP came along to save the day, and they brought receipts.
They have 3 variants:
en: 800GB in TFDS format, 300GB in JSON formaten.noclean: 6.3TB in TFDS format, 2.3TB in JSON formatrealnewslike: 38GB in TFDS format, 15GB in JSON format
Download the C4 dataset! · Discussion #5056 · allenai/allennlp
You can't perform that action at this time. You signed in with another tab or window. You signed out in another tab or…
github.com
Multi-Lingual CLIP
How about a multi-lingual CLIP?
How about 101 source languages using multi-lingual BERT (distilled or base)?
This library offers this, and includes an intuitive Colab to test inference. U+1F525U+1F525
Feel free to contact the authors if you want add a language that is currently not supported. This is great work.
FreddeFrallan/Multilingual-CLIP
Colab Notebook · Pre-trained Models · Report Bug OpenAI recently released the paper Learning Transferable Visual Models…
github.com
Almond V.2 Stanford’s Open Sourced Voice Assistant
Want to help develop an open-sourced voice assistant? Almond is here:
Features:
- Spotify (music)
- Home Assistant (IoT)
- Weather
- Jokes
- Local restaurants
- FAQs about the assistant itself
Call for testing: Almond 2.0 Alpha
Hello all! I am very pleased to announce the immediate availability of the new alpha release of Almond. This is the…
community.almond.stanford.edu
A100s Bonanza
Google Cloud Platform update, if you want to go nuts with distributed computing you can now get 16 A100s on a single A2 instance. This is serious horsepower, if you want to know what the upper bound of compute looks like on GCP, this is it.
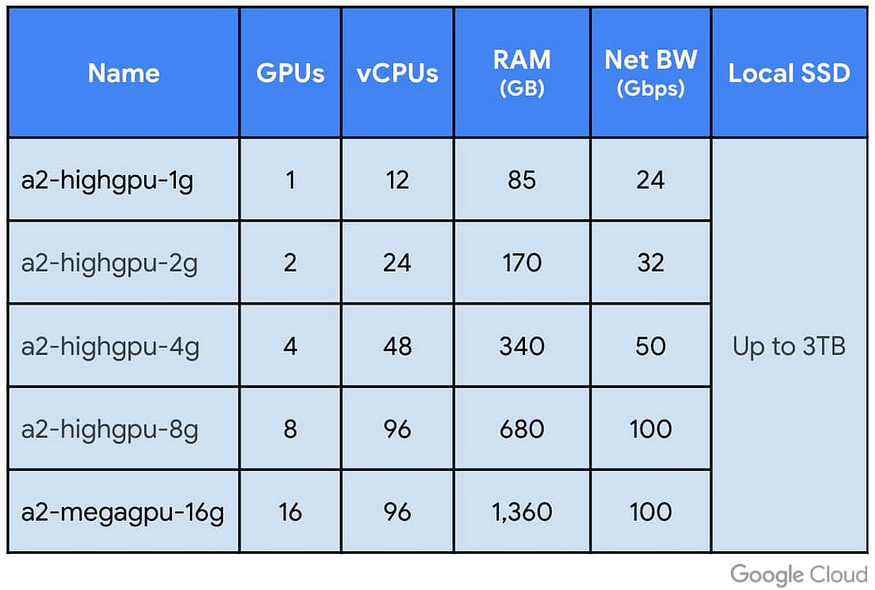
A2 VMs with NVIDIA A100 GPUs are GA U+007C Google Cloud Blog
A2 VMs with NVIDIA A100 GPUs are now generally available for your most demanding workloads including machine learning…
cloud.google.com
Getting Started with Rust
It’s like Python but fast U+1F601. If you want to know the current state of Rust, check out the Stack Overflow blog U+1F447 . It highlights how the small but devoted Rust community continues to show strength and includes links to tutorials.
Getting started with … Rust – Stack Overflow Blog
In this series, we look at the most loved languages according to the Stack Overflow developer survey, the spread and…
stackoverflow.blog
TensorFlow and Quantum: 1 Year Through the Looking Glass
An overview of the Quantum TF library found here:
tensorflow/quantum
TensorFlow Quantum (TFQ) is a Python framework for hybrid quantum-classical machine learning that is primarily focused…
github.com
Blog
TensorFlow Quantum turns one year old
March 18, 2021 — Posted by Michael Broughton, Alan Ho, Masoud Mohseni Last year we announced TensorFlow Quantum (TFQ)…
blog.tensorflow.org
Software Updates U+1F4BB
Sentence Transformers Update
Transformers 4.4.2
Releases · huggingface/transformers
Two new models are released as part of the S2T implementation: Speech2TextModel and…
github.com
AresDB — GPU Powered Real-Time Storage and Query Engine (in GoLang)
From Uber’s engineering group, this is the source code for AresDB. You get to hook up GPUs for super low latency database querying.
uber/aresdb
AresDB is a GPU-powered real-time analytics storage and query engine. It features low query latency, high data…
github.com
Original release blog:
Introducing AresDB: Uber's GPU-Powered Open Source, Real-time Analytics Engine
At Uber, real-time analytics allow us to attain business insights and operational efficiency, enabling us to make…
eng.uber.com
SpeechBrain
An awesome new speech library with several pretrained models on the HF repo. Tasks it supports: speaker recognition, speech identification and speech diarization. It runs on PyTorch.
SpeechBrain: A PyTorch Speech Toolkit
SpeechBrain is an open-source and all-in-one speech toolkit. It is designed to be simple, extremely flexible, and…
speechbrain.github.io
MongoDB for Storing and Retrieving ML Models
Tutorial w/ code:
How to Use MongoDB to Store and Retrieve ML Models — Python Simplified
If you are looking for a database for storing your machine learning models then this article is for you. You … How to…
pythonsimplified.com
The Mega (Incredible) PyTorch Repo
“This is a curated list of tutorials, projects, libraries, videos, papers, books and anything related to the incredible PyTorch.”
This is a HUGE index.
ritchieng/the-incredible-pytorch
This is a curated list of tutorials, projects, libraries, videos, papers, books and anything related to the incredible…
github.com
Repo Cypher U+1F468U+1F4BB
A collection of recently released repos that caught our U+1F441
CARTON Transformer
aka: Context Transformer with Stacked Pointer Networks for Conversational Question Answering over Knowledge Graphs…
Performs multi-task semantic parsing for handling the problem of conversational question answering over a large-scale knowledge graph.
endrikacupaj/CARTON
Neural semantic parsing approaches have been widely used for Question Answering (QA) systems over knowledge graphs…
github.com
Connected Papers U+1F4C8
Multilingual Code-Switching for Zero-Shot Cross-Lingual Intent Prediction and Slot Filling
Train a joint intent prediction and slot filling model in English and generalize to other languages.
jitinkrishnan/Multilingual-ZeroShot-SlotFilling
Goal: Train a joint intent prediction and slot fillinf model using English and generalize to other languages…
github.com
Connected Papers U+1F4C8
BERTRL: Inductive Relation Prediction by BERT
Using BERT to do knowledge base completion.
zhw12/BERTRL
Code and Data for Paper [Inductive Relation Prediction by BERT], this paper proposes an algorithm to do knowledge base…
github.com
Connected Papers U+1F4C8
Multimodal End-to-End Sparse Model for Emotion Recognition
wenliangdai/Multimodal-End2end-Sparse
Paper accepted at the NAACL 2021: Multimodal End-to-End Sparse Model for Emotion Recognition, by Wenliang Dai * …
github.com
Connected Papers U+1F4C8
VitaminC
Using Transformers to fine-tune the VitaminC dataset for fact verification.
TalSchuster/VitaminC
This repository contains the dataset and model for the NAACL 2021 paper: Get Your Vitamin C! Robust Fact Verification…
github.com
Connected Papers U+1F4C8
Enconter
ENtity-CONstrained insertion TransformER, a language model to help improve fine control of content generation i.e. a method for dealing with entity constraints.
LARC-CMU-SMU/Enconter
Implementation of 2021 EACL paper Enconter. Contribute to LARC-CMU-SMU/Enconter development by creating an account on…
github.com
Connected Papers U+1F4C8
Dataset of the Week: ParaQA
What is it?
A question answering dataset with paraphrase responses for single-turn conversation.
Dataset contains 5,000 question-answer pairs with a minimum of two and a maximum of eight unique paraphrased responses for each question.
Sample
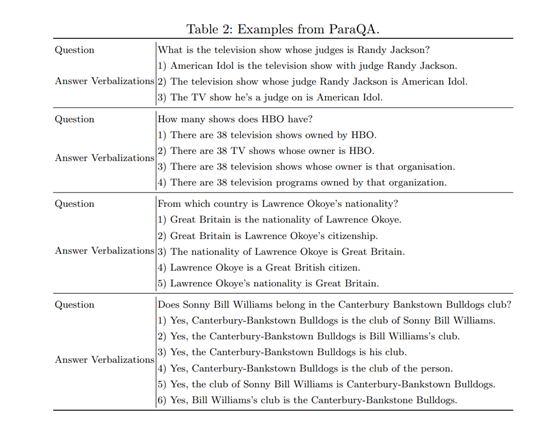
Where is it?
barshana-banerjee/ParaQA
The dataset was created using a semi-automated framework for generating diverse paraphrasing of the answers using…
github.com
Every Sunday we do a weekly round-up of NLP news and code drops from researchers around the world.
For complete coverage, follow our Twitter: @Quantum_Stat
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

