



Grouping Classes Using K-Nearest Neighbors Algorithm — Python
Last Updated on July 20, 2023 by Editorial Team
Author(s): Jayashree domala
Originally published on Towards AI.
Machine Learning
A guide to knowing and implementing the KNN algorithm.
What is the KNN algorithm?
It is an algorithm used for classification tasks and works on a very simple principle.
How does it work?
The KNN algorithm is very basic. The training algorithm stores all the data. And the predicting algorithm calculates the distance of a data point to all points in the data, sorts the points in the increasing order of distance from the data point and then predicts the majority label of the ‘k’ closest points.
What are the advantages of this algorithm?
- It is very simple and easy to understand and implement.
- It used only 2 parameters: k and distance metric.
- It can classify any number of classes.
- The training step is very easy to implement and more data can be added at any stage.
What are the disadvantages of this algorithm?
- It works well only with numerical data. With categorical data, it might not perform well.
- The cost of prediction is very high.
- It does not do well with high-dimensional data.
How to implement KNN using Python?
An artificial dataset is used to perform the classification. There are two classes 0 and 1. The goal is to classify the data into two different classes.
→ Import packages
The libraries to help deal with data — pandas and numpy along with data visualization packages — matplotlib and seaborn are imported.
>>> import pandas as pd
>>> import numpy as np
>>> import matplotlib.pyplot as plt
>>> import seaborn as sns
>>> %matplotlib inline
→ Read data
The data has a target class that takes the value 0 or 1. The other columns are numeric but there is no meaning to it since the data is artificial.
>>> df = pd.read_csv('datasets/dataset.csv')
>>> df.head()

→ Standardize data
In KNN, it is important to standardize the variables. The reason being that KNN classifies a test observation by identifying the observations that are nearest to it and if there are any variables with a large scale then it will have a higher effect on the distance between observations. It is done using the sci-kit learn package. The standard scalar function is imported and an instance of it is created.
>>> from sklearn.preprocessing import StandardScaler
>>> scaler = StandardScaler()
Next, fit the scaler object to the features (data without target class) and using the transform() method the features are transformed to a scaled version.
>>> scaler.fit(df.drop('TARGET CLASS',axis=1))
>>> scaled_features = scaler.transform(df.drop('TARGET CLASS',axis=1))
The scaled features can be viewed in the form of a dataframe which will be used for model building.
>>> df_final = pd.DataFrame(scaled_features,columns=df.columns[:-1])
>>> df_final.head()
→ Splitting the data into training and testing data
The train test split function will be used from the scikit learn package.
>>> from sklearn.model_selection import train_test_split
>>> X_train, X_test, y_train, y_test = train_test_split(scaled_features,df['TARGET CLASS'],test_size=0.30)
Choosing the K value
Using the elbow method, the value of K will be chosen. So K values will be looped and for each value, the error rate will be calculated.
>>> from sklearn.neighbors import KNeighborsClassifier>>> error_rate = []>>> for i in range(1,40):
knn = KNeighborsClassifier(n_neighbors=i)
knn.fit(X_train,y_train)
pred_i = knn.predict(X_test)
error_rate.append(np.mean(pred_i != y_test))>>> plt.figure(figsize=(10,6))
>>> plt.plot(range(1,40),error_rate,marker='o',
markerfacecolor='red')
>>> plt.title('Error Rate v/s K Value')
>>> plt.xlabel('K')
>>> plt.ylabel('Error Rate')
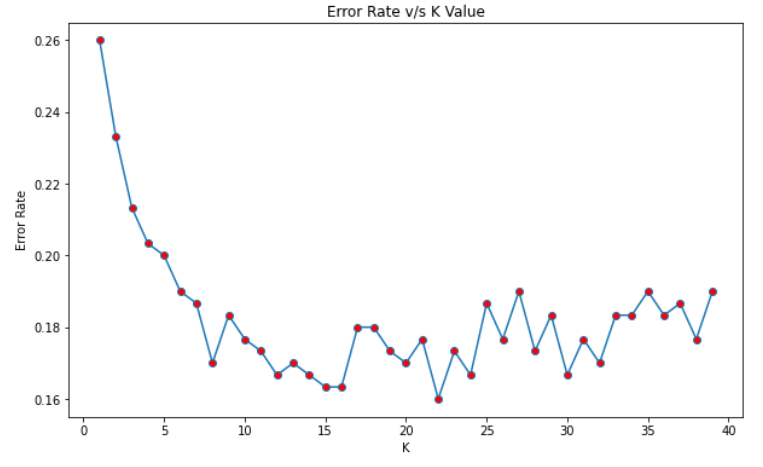
Using the above graph, the K value can be considered as 30.
→ Model building
The model is built by using the KNeighborsClassifier method imported from sci-kit learn. An object of the KNN function will be created and the number of neighbors which is equal to the K value obtained above will be mentioned. Then the object is fit on the training data.
>>> knn = KNeighborsClassifier(n_neighbors=30)
>>> knn.fit(X_train,y_train)KNeighborsClassifier(n_neighbors=30)
→ Prediction
>>> pred = knn.predict(X_test)
→ Evaluations
>>> from sklearn.metrics import classification_report,confusion_matrix
>>> print(confusion_matrix(y_test,pred))[[133 34]
[ 16 117]]>>> print(classification_report(y_test,pred))
precision recall f1-score support 0 0.89 0.80 0.84 167
1 0.77 0.88 0.82 133 accuracy 0.83 300
macro avg 0.83 0.84 0.83 300
weighted avg 0.84 0.83 0.83 300
Refer to the dataset and notebook here.
Beginner-level machine learning books to refer to:
Python Machine Learning: A Beginner’s Guide to Python Programming for Machine Learning and Deep…
The Hundred-Page Machine Learning Book
Advance-level machine learning books to refer to:
Hands-On Machine Learning with Scikit-Learn, Keras and Tensor Flow: Concepts, Tools and Techniques…
Pattern Recognition and Machine Learning (Information Science and Statistics)
Reach out to me: LinkedIn
Check out my other work: GitHub
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

