



Decrypting QAnon
Last Updated on July 20, 2023 by Editorial Team
Author(s): Luca Giovannini
Originally published on Towards AI.
Natural Language Processing, Opinion
A NLP-oriented look at the movement’s core texts.
One of the most interesting effects of the transition between the Trump and the Biden administration has been the decline of public interest in QAnon—the infamous online conspiracy theory strongly associated with the former US president and his false claims of electoral fraud. As the graph below shows, the buzz about the QAnon movement had peaked in early January, in correspondence with the storming of Capitol Hill — a pivotal event which QAnon-related online contents have been instrumental in fuelling.

In the following weeks, however, QAnon has dramatically lost relevance in public discourse; the drop was mostly caused by the massive removal of its contents from major social media like Facebook, Twitter and Youtube, which resulted in QAnonists migrating to rightwing echo chambers like Parler or Gab.
Nonetheless, the QAnon movement still plays a revelevant in the political arena, and it may be interesting to take a closer look at its distinctive features. In this post, I’ll employ some basic data science techniques to walk you through the language of QAnon’s ‘holy texts’, i.e. the wealth of online posts which have shaped the movement’s worldview. Let’s go!
Do you speak QAnon-ish?
I’m not going to recap here the movement’s features and goals (see Wikipedia), but before we dig in its texts you’ll like perhaps a bit of background on their alleged author, the mysterious ‘Q’. According to QAnon lore, he/she is an high-profile US intelligence official, who acts as a sort of mole within the government and shares pieces of intel about Trump’s heroic war against the Deep State on message boards like 8chan or 8kun. These cryptic posts are then investigated and researched by the community, which is invited to ‘follow the crumbs’ and read between the lines coded evidence of shadowy operations.
Speculations about the true identity of Q have often pointed to 8chan administrators Ron and Jim Watkins, while a stylometric analysis by a Swiss company demonstrated that the posts were written by at least two people over different periods. Since Q’s ‘tripcode’ — a sort of online signature used to verify identities on 8chan — has been compromised more than once, however, it is likely that several individuals have posted under that name. But what can basic NLP techniques tell us about the content of these posts?
My experiment began searching online for “Q drops”, and I soon landed in one of the many mirror websites which collect these alleged pieces of intel. Drops are released quite irregularly (the last one available is dated Dec 8, 2020), but a banner admonishes not to “mistake silence for inaction”, since at times Q “strategically goes dark” while “major MIL/MILINT ops are occurring behind the scenes”. Impressive.
Anyway, I downloaded the bunch of drops available (tracing back to Oct 29, 2017, and conveniently packed in a 1255 pages long PDF) and I converted it to TXT format. Then, it was time for some Python coding: here’s the link to my Colab notebook if you want to follow along.
First, I did some text preprocessing, removing non-alphabetic characters (although I suspect some iconic numbers, such as ‘45’ for Trump, would have featured prominently), stopwords (like ‘status’, referring to Twiter posts) and words with less than two characters — mainly byproducts of the previous steps. Before you ask, I did take note of the occurrences of the iconic ‘Q’: they were almost 12,000, since the letter is used to sign most posts.
Once cleaned the corpus, I built a word-frequency dictionary, from which I selected the 500 keys with the highest frequency. To improve dataset quality I ran a check on whether the keys belonged to the English vocabulary, while manually adding individual names and significant words which were not recognised (e.g. ‘potus’).
The resulting dictionary had 486 entries. But how to visualise them in a meaningful way?
Exploring QAnon’s trending topics
In a previous post on Medium I spoke about wordclouds and how they allow to intuitively grasp the meaning of large texts by visualising them. One solution, therefore, was feeding the data to the WordCloud algorithm. Here’s the result:

Seeing some strange words? Don’t worry, I’ll explain them in a minute. For the purposes of the discussion, this histogram with the top 50 terms could be handier:
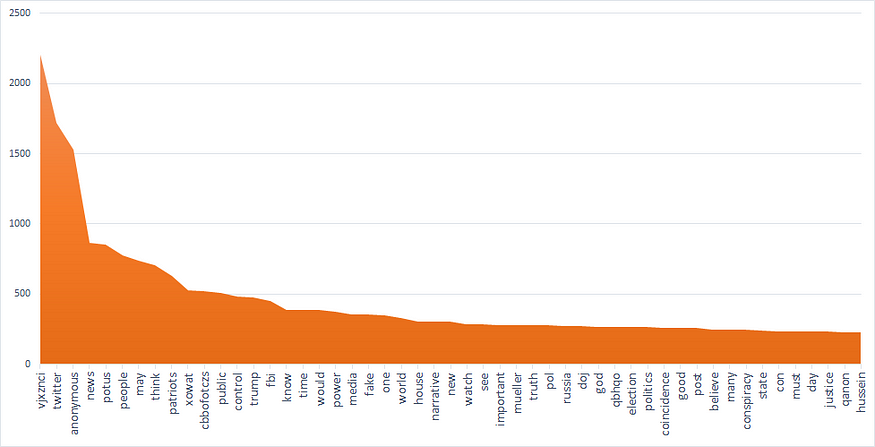
What does this graph tell us? Well, the word frequency is actually pretty even distributed, as it slowly decreases after the initial jump from the peak of Q (not shown) and the first three-four terms. Among them, twitter and anonymous should be really treated as stopwords and therefore removed, since they always occur in outbound links to tweets; I left them here and in the wordcloud above just to underline how prominent this social media has been in the spreading of QAnon theories.
Far more interesting is the cryptic vjxznci —no, it’s not Elon Musk’s newborn. I’ll be there shortly. Another zoom on the first top 20 terms:
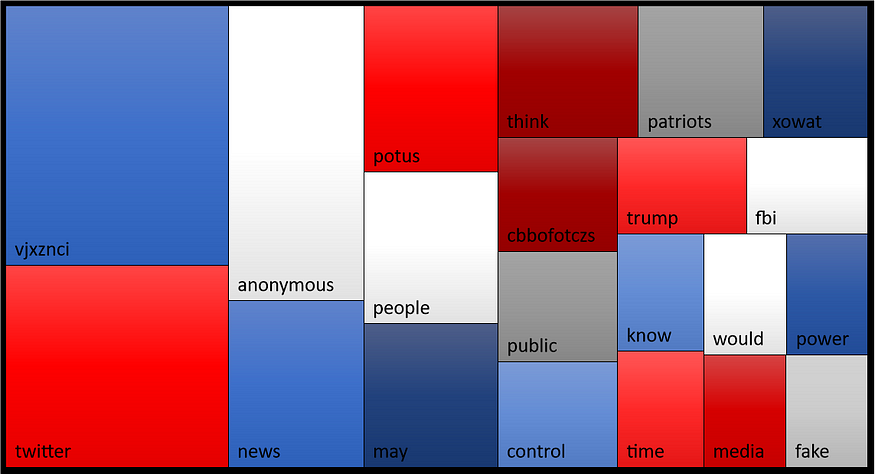
From this colorful tile mosaic one can already get a decent grasp of QAnon’s ideology, starting from their ideological referent (potus, trump), his allies (the people, the patriots) and his enemies (fake + news, fake + media are probably recurring collocations). It is also significant that, excluding the auxiliaries may and would (which express a degree of uncertainty or speculation, and are thus useful in making predictions), the most recurrent verbs are think, know and control — underlying how Q constantly reminds his followers of the dangers of mental manipulations by mainstream institutions and media.
We are left with some puzzling terms like the ubiquitous vjxznci, cbbofotczs or xowat, which reflect the more ‘hermetic’ side of QAnon. As far as I can tell, these are codewords — integrated with numbers which the preprocessing algorithm stripped — which Q uses for identity verification (the so-called ‘tripcodes’) and which followers are encouraged to interpret as enigmatic clues to be decoded in the most subtle ways (e.g. recurring to gematry).
QAnonworld, visualised
Perhaps we did a bit too much close reading here, so let’s jump back to a more quantitative view. Eventually, one could try to understand the main topics in QAnon posts by clustering their words according to their meaning — this should underline which semantic areas are prevalent. Seems quite straightforward, isn’t it?
Actually, I spent a lot of time trying to figure out the best solution to do it, and I’m not still 100% satisfied with the result [1]. Anyway, the standard NLP method for representing words on maps involves the use of word embeddings, i.e. vectors (set of numbers) which express the relationship between a word and the others within a given text (if you have no idea what I’m talking about, you may get a clue by trying this tool or reading this article).
Representing words as embeddings results in words with similar meaning having similar embeddings, and therefore laying close in a visual representation: as you probably guess, this automatically builds rough semantic clusters, since the vector representing the word ‘congress’, for example, will be more similar (and nearer in a graph) to the one for ‘ senate’ than to the one for ‘marshmallow’.
To be honest, it’s not that simple, and a better solution would have been calculating some similarity metric between vectors and clustering them before plotting. Furthermore, tutorials generally advise to train word embeddings on the specific corpus, while I wanted to take the short route and get them from some pretrained model [2].
Eventually, I settled down with the simplest solution I found for direct plotting from user-inserted words. I employed the whatlies library (Warmerdam, Kober & Tatman 2020) together with the largest spaCy English-language model (including more than half a million embeddings). Since vectors are multidimensional and wouldn’t fit on a XY map, one has to apply some dimensionality reduction method, so I experimented with PCA, UMAP and the standard whatlies word-wise scaling (which uses two words from the set as parameters for similarity).
OK, enough technicalities for today. Here’s our map rendering of QAnon discourse: at first sight it seems pretty messy, so you’ll probably find the interactive version in the notebook more rewarding.

Let’s take a snapshot and do manually what a better NLP engineer would have made in Pyhton (sorry for the bad Paint graphics). Can you see some interesting semantic groups?
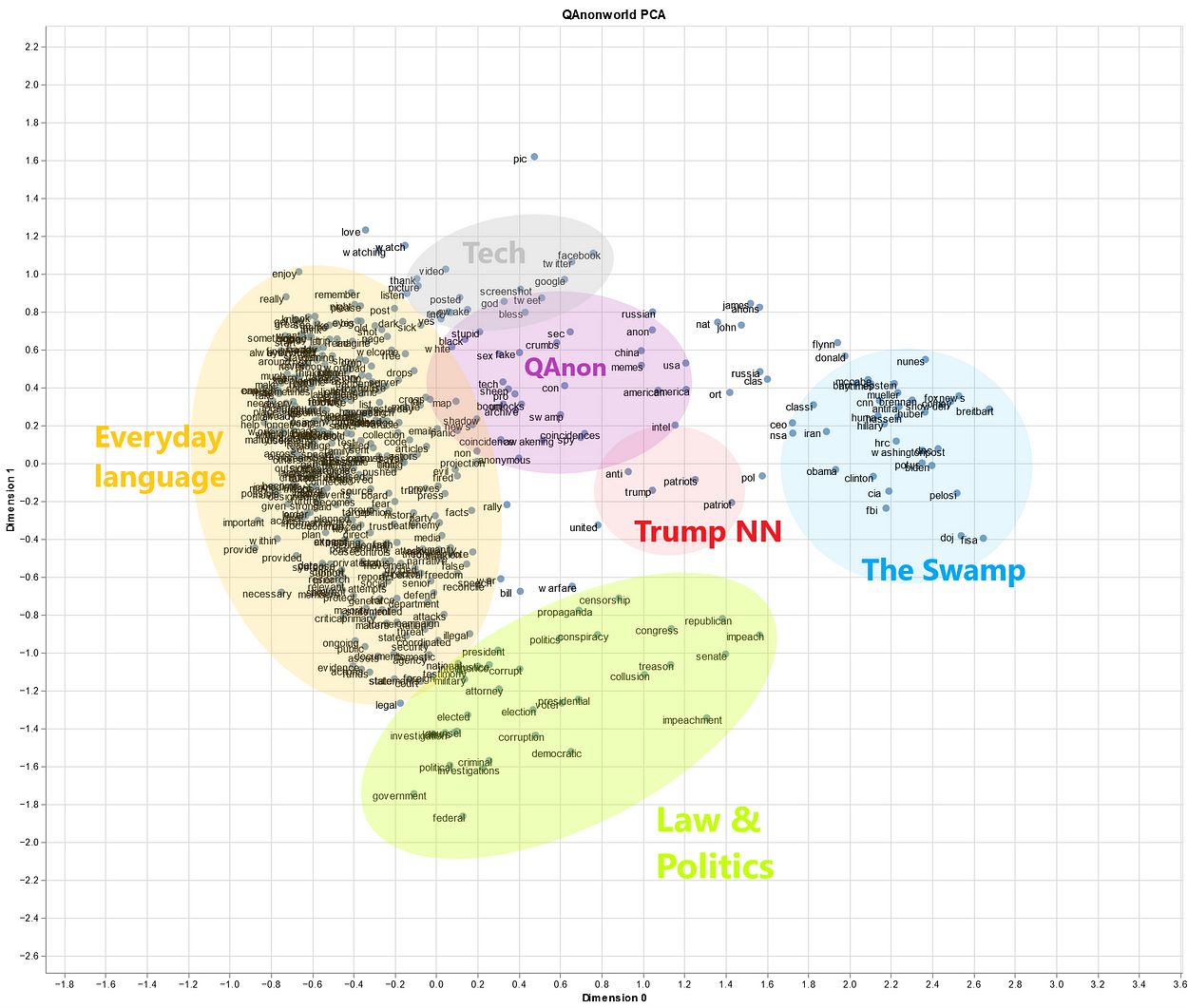
As you see, apart from the big blob of common language on the left, we have some pretty well defined topics of discussion. The blue bubble, for example, groups most of the enemies of the 45. President, ranging from prominent Democrats (Obama, Biden, Pelosi, Clinton with her much-discussed aide Huma) to recalcitrant federal agencies (FBI and its former director Mueller, NSA, DOJ), from foreign states (Iran, while Russia is significantly farther) to “fake news” (Washington Post, CNN). Some drawbacks of using a pretrained model for word embeddings are also evident, as Trump-leaning terms like potus, Fox News and Breitbart got also sucked in.
Similarly, the green zone at the bottom reflects contents about some highlights of Trump’s presidency, like his first impeachment, Mueller’s investigation, and his fraud claims regarding the 2020 election, while also expressing broader political themes and some core concerns of the QAnon movement (propaganda, censorship). The movement’s specific language, conversely, is recognisable in the upper part of the graph (purple): although the set is quite loose, one can recognise conspiracy-related keywords such as crumbs, awakening, coincidences, anonymous and even memes.
Quite fittingly, Trump stands at the centre of graph, with his nearest neighbours being, of course, the patriots.
That’s it for our gentle introduction to QAnon language from a computational perspective: although the NLP techniques I employed were quite basic, it did yield nonetheless some interesting results, highlighting some recurrent linguistic patterns within the drops corpus. In case you want to further dive in the phenomenon, I do recommend you this recent study by Aliapoulious et al. (“The Gospel According to Q: Understanding the QAnon Conspiracy from the Perspective of Canonical Information”). Until next post!
Thanks for reading and, as always, feedback and comments are very welcome! If you liked this article, you may be interested in my previous data science-oriented contributions:
Data Science Meets “Murder, She Wrote”
A data-driven analysis of NBC’s classic whodunit “Murder, She Wrote” (1984–96), starring Angela Lansbury, William…
towardsdatascience.com
The Aesthetic of Wordclouds
An elegant way to represent word frequency in texts — and how to make yours without having to write a single line of…
towardsdatascience.com
Notes:
[1] That’s an euphemism: I spent several days trying to find a solution. Apart from whatlies, I found these pieces on Medium (1 and 2) and this question on StackOverflow quite helpful, albeit I lacked the technical skills to put it all together and make it work (or better: I found a custom way to plot word embeddings on a map, but without labels). Another option would have been employing Tensorflow’s Embedding Projector (by loading TSV files of vectors and metadata) or parallax, which I am not familiar with.
[2] Training the model on the actual corpus would have entailed more accurate preprocessing, like splitting the corpus in sentences, and I’m not sure it would have made sense: although it is normally useful in underlining corpus-specific word connections, the nature of the drops themselves (brief, fragmentary, obscure messages) might have made results less meaningful.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


