



Mastering Recommendation Engines with Neural Collaborative Filtering
Last Updated on December 11, 2023 by Editorial Team
Author(s): Priyansh Soni
Originally published on Towards AI.
This article is your go-to manual for crafting a recommendation engine with Neural Collaborative Filtering (NCF). Starting with a swift introduction to recommendation engines, we’ll dance through their different types, focusing primarily on model-based collaborative filtering, leading all the way to the working of neural recommendation engines. And just to sweeten the deal, we’ll wrap it all up with a juicy real-world example.
Kindly buckle up, ‘coz this one’s a little cool.
Disclaimer — This article assumes that the reader is familiar with recommendation engines and collaborative filtering.
OUTLINE —
- What are Recommendation Engines and their types?
- Model-Based Collaborative Filtering and NCF
- Working algorithm of pure NCF models
- Making a Recommendation Engine with NCF
- Conclusion
1. What are Recommendation Engines and their types?
Recommendation engines, also referred to as recommender systems, are nothing but engines or algorithms that serve us with content we are most likely to watch, buy, and consume. etc. These systems hold significant importance across diverse online platforms, spanning e-commerce websites, streaming services, as well as social media and content platforms. Their primary goal is to analyze user preferences and behaviors to deliver tailored recommendations, ultimately enhancing user engagement and satisfaction.
The most common example of this is online streaming services like Netflix, Amazon Prime, and such, where we are often presented with content recommendations on the home page that say “You might also like”.
Types of Recommendation Engines :
- Content-Based Filtering
- Collaborative Filtering
- Hybrid Models
Let’s get a brief about them —
Content-based filtering analyzes the characteristics and features of items users have interacted with or searched in the past. By focusing on item attributes, these systems recommend items with similar properties. This is mostly used when the user base is less and there are more products to serve — a cold start problem.
Collaborative Filtering (CF) recommends items by examining the preferences and behaviors of a group of users. This can be user-based and item-based. User-based CF identifies similar users and suggests items liked by those similar users, whereas Item-based CF suggests items similar to ones the user has previously enjoyed.
Hybrid recommendation engines follow ensemble techniques, often blending aspects of both content-based and collaborative filtering. By integrating various approaches, these models aim to overcome individual limitations, providing more accurate and diverse recommendations.
Now Collaborative Filtering recommender engines can also be categorized further as Memory-based and Model-based.
The major difference between these two methods is the way they determine the ratings given by users to items.
- Memory-based CF uses a traditional approach by measuring user/item similarity using correlation methods (e.g., Pearson’s) and then taking a weighted average of the ratings to generate a rating for an item by the user.
- Model-based CF uses machine learning or statistical models to learn patterns and relationships in the data, which is then used to determine user ratings for items.
Regardless of how interesting both of these methods are, we are going to dive deeper into Model-based Collaborative Filtering for this article to justify its title!
2. Model-Based Collaborative Filtering and NCF
Model-based CF, in brief, involves creating a model from the user-item interactions to make predictions. It uses machine learning or statistical models to learn patterns and relationships in the data. Let’s get into the details of this.
Model-based CF tends to create user-feature and item-feature matrices, which are randomly initialized, dotted, and weighted to generate the user-item interaction scores. This can be visualized in the image below
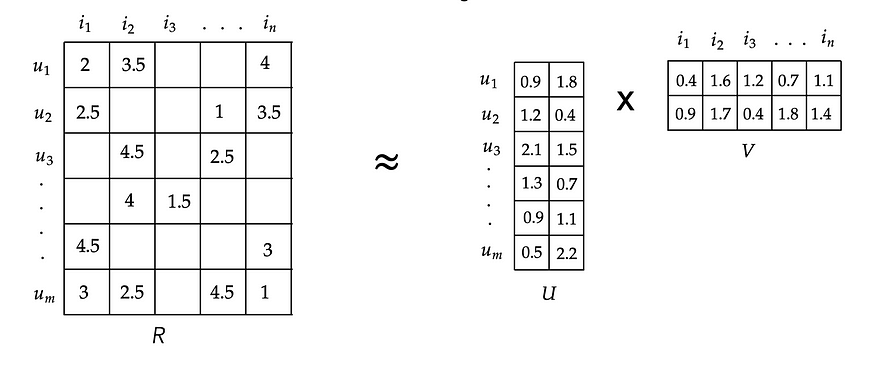
As seen above the matrices U and V are user-feature and item-feature matrices. These are randomly initialized.
- The user-item interaction matrix (R) is usually sparse since most of the items are not rated by the users.
- The matrices U and V are dotted to generate the predicted values for the user-item interaction matrix. These will be some random values coming from the dot product of two random matrices (U and V). Let's call this matrix with random values R`.
- Just like we use optimization algorithms, e.g., gradient descent, in traditional ML to update the values of w and b to minimize the loss between the actual and the predicted output, a similar approach is followed here to update the values inside the matrices U and V to minimize the difference between R and R` via gradient descent.
Gradient descent adjusts these random weights to their most optimal values which minimises the difference between the predicted ratings and the actual ratings.
The model learns to assign weights to the latent features in matrices U and V. These weights capture patterns and preferences in the user-item interaction data. The weights are optimized until the model converges. The learned matrices U and V are then used to predict missing entries in the original matrix and make personalized recommendations for users.
We can also use embedding layers for user and item features, which can be learned during model training via gradient descent.
This method of decomposing the sparse user-item interaction matrix into two lower-rank matrices (U and V) is called Matrix Factorisation. There are several other types of Model-based CF methods like —
- Singular Value Decomposition (SVD)
- Probabilistic Matrix Factorization (PMF)
- Non-Negative Matrix Factorization (NMF)
- Factorization Machines
- Neural Collaborative Filtering (NCF)
- Deep Learning Models for Recommendation — RNNs, CNNs, Transformers, etc.
The gist of all these model-based CF methods is to learn the latent feature patterns of user and item interactions. Some of these methods can only capture linear patterns like Matrix Factorisation, SVD, etc., whereas others can capture non-linearity. And one such method is NCF!
Neural Collaborative Filtering
Neural Collaborative Filtering (NCF) leverages the expressive power of neural networks to model complex and non-linear relationships in user-item interactions. While traditional collaborative filtering methods capture linear patterns, NCF can use activations like ReLU to capture non-linearity.
Incorporating neural networks into the collaborative filtering layer effectively transforms the recommendation problem into a machine learning task by employing neural architectures, typically involving multi-layer perceptrons (MLP) or deep neural networks.
Let’s dive into how NCF models are built
Working algorithm of pure NCF models
While building traditional collaborative filtering models like Matrix Factorisation(MF), we usually start with a sparse user-item interaction matrix, then we make separate user and item latent feature matrices U and V, that are randomly initialized or created with embeddings. Then, these feature matrices are dotted to generate the matrix R`, which is then used to update the values inside the matrix U and V. NCF incorporates the structure of MF models and combines it with neural networks.
A typical NCF model utilizes embeddings. The architecture can be broken down to 3 layers—
- Matrix Factorisation (MF) layer — generates dotted output for user and item embeddings — R`. The matrix R` captures linear interactions between users and items.
- Neural Network (NN) layer — generates concatenated user and item embeddings passed through an MLP. The MLP layer is used to capture non-linear interactions between users and items.
- NCF output layer — combines the output from MF and NN layers to generate the final output. The output R` from the MF layer is concatenated with the output of the NN layer. This concatenated vector is passed through a Dense layer, which generates the final output for the model.

The sole purpose of incorporating an MLP for training is to capture the non-linear interactions bewteen the latent features of users and items.
The models can be tweaked for various incorporations like batch normalization, dropout layers, optimizers like Adam, etc.
Let’s look at a real-world problem statement to get a little hands-on.
4. Making a Recommendation Engine with NCF
4.1 Problem Statement
We will take the usual movie recommender problem set but will approach it using NCF instead of traditional CF models. Any related problem statement can be found on websites like Kaggle, UCI machine learning repository, etc.
4.2 Dataset
The dataset, after filtering and preprocessing, looks like this —

We have the userId, movieId, and ratings given by users to movies. Collaborative filtering methods just require user and item interactions, since they learn the patterns in these interactions irrespective of other user and item features. Therefore, all we need for a CF model or a model derived from CF (like NCF), is the user and item interactions and nothing else.
4.3 User-Movie Interaction Matrix
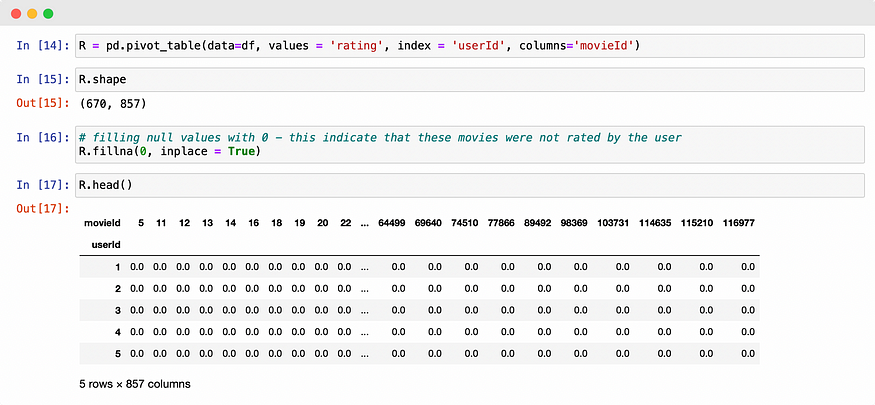
The user-movie interaction matrix denotes the ratings given by users to movies. This is a sparse matrix since users have not seen all the movies
4.4 Getting Data Ready for Modelling

As a neural network takes only numeric input, we made indices of userId and movieId. This will help if we have userId and movieId in categorical or some other format other than an integer.
Next, we split the data into a random 80–20 split and generated the training and validation sets.
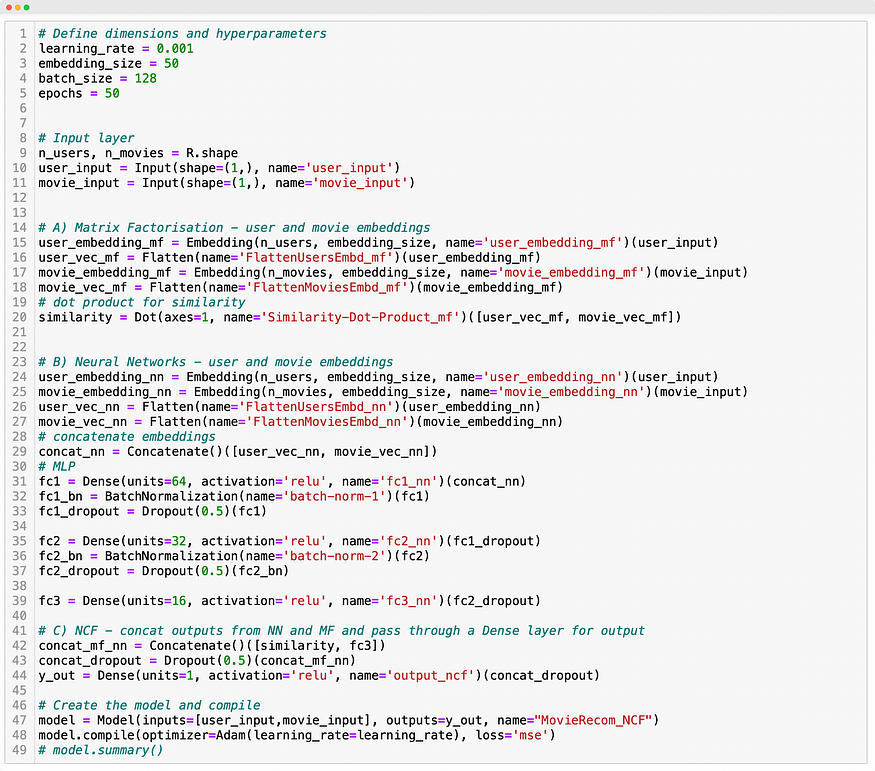
4.5 Model Architecture
We’ll go through the model architecture step by step —
- Define hyperparameters like epochs, batch size, learning rate, and embedding size.
- Define the input layer for the model using Keras layers.Input
- Define the MF layer with user and movie embeddings. Flatten the embeddings and take the dot product to generate a similarity score (traditional MF architecture).
- Define the NN layer with user and movie embeddings, flatten and concatenate the embeddings, and pass them as input through a Multi-Layer Perceptron(MLP) to generate the output. Add and tweak modifications like the number of neurons, batch normalization, and dropout layers.
- Define the NCF layer by concatenating the output from the MF and NN layers. Pass the concatenated vector through a Dense layer with a single neuron to generate the output for the entire model.
- Build and compile the model with the ‘MSE’ loss and optimizer of your choice.
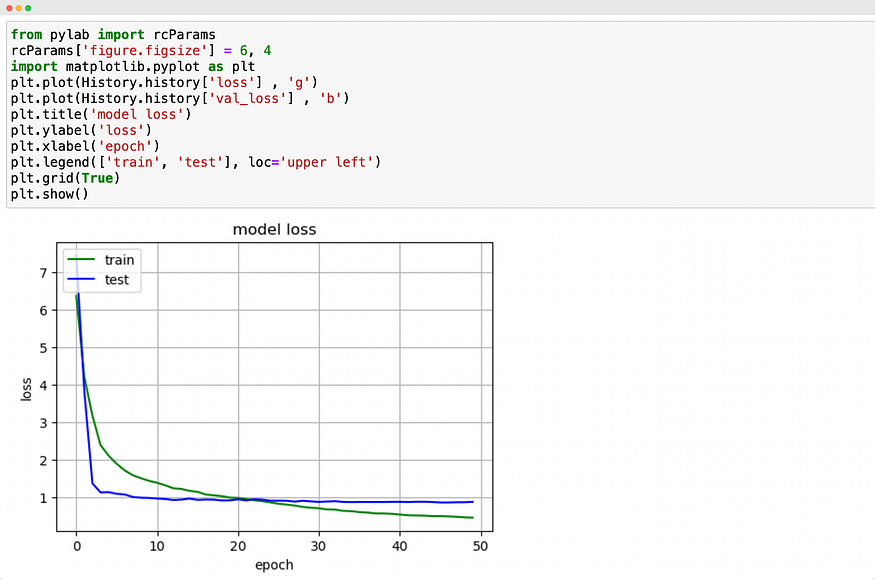
4.6 Model Training and Evaluation
Train the model on the desired number of epochs and batch_size. Try with multiple combinations of epochs and batch_size to generate the best results.

4.7 Make Predictions
After successful model training and evaluation, make predictions on the entire dataset to get the ratings for unrated movies.

5. Conclusion
Embarking on the journey of recommendation engines reveals a world where technology understands us better than we know ourselves. Neural Collaborative Filtering (NCF) isn’t just an algorithm; it’s a wizard crafting tailored journeys for every user. With NCF’s prowess, recommendations aren’t just suggestions — they’re personalized invitations to uncover new passions and experiences. As we bid adieu, let’s embrace the excitement of evolving technology, knowing that every recommendation is a tiny spark igniting joy in our digital adventures.
Check these out as well —
The Power of Click Probability Prediction
CPP — the engine that fuels the algorithms behind modern recommendation systems, online advertisers, and much more. This…
medium.com
One Stop For Logistic Regression
Logistic Regression? Why is it called Regression? Is it linear? Why is it so popular? And what the hell is log odds?
pub.towardsai.net
A One-Stop for Support Vector Machine
Support Vectors? Machine? And, why isn’t Oswald Mosely dead?
medium.com
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

