



Intro to MLOps using Amazon SageMaker
Last Updated on June 4, 2022 by Editorial Team
Author(s): Ankit Sirmorya
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Intro to MLOps Using Amazon SageMaker
Introduction
Everything has to be excellent and advantageous in today’s generation. ML AI is always a superior method in technology to make this happen. Amazon Sagemaker is gradually gaining traction as a great platform for supporting, managing, and expanding machine learning workloads that may help enterprises. Thousands of clients are embracing Machine Learning (ML), big data, and elastic computing to change their companies using Amazon SageMaaker and other AWS cloud services [2]. The fastest-growing area of information technology is machine learning [1]. Data scientists and developers can design and train machine learning models fast and simply using SageMaker, then deploy them straight into a production-ready hosted environment. Training and hosting are priced by the minute, with no minimum payments or upfront obligations. The MLOps methods supplied by Amazon SageMaker are both beneficial and simple; they will keep the organization secure and save money on data science activities while also avoiding expensive technological debt [2]. ML Operations (MLOps) helps manage individual initiatives and utilize AI/ML at scale by exploiting AI/ML to improve the organization at scale.
The SageMaker platform enables us to automate and standardize MLOps procedures throughout our organization, allowing us to spend less time on machine learning (ML). It is simple to design, train, deploy, and manage a few, hundreds of thousands, or even millions of machine learning models. We help data scientists and machine learning engineers to boost productivity while maintaining high model accuracy and enhancing security and compliance by offering purpose-built tools for managing ML lifecycles and built-in interfaces with other AWS services.
We’ll go through what these tools are, their model training method, functionality, and real-world application in-depth, starting with a comprehensive review of AWS Sagemaker and ending with skill-building experience with MLOps.
MLOps
Machine learning and operations are abbreviated as MLOps. The phrase refers to a group of strategies for automating the life cycle of a machine learning algorithm, from initial model training to deployment and retraining with new data [7]. Machine Learning Operations (MLOps) is a subset of Machine Learning Engineering that automates the process of converting machine learning models into production, as well as maintaining and monitoring them. MLOps is a team effort that frequently includes data scientists, DevOps engineers, and IT. MLOps is developed from regular DevOps in the end.
At the height of the first digital boom, agile solutions aided firms in managing the product life cycle by reducing waste and automating creative processes, allowing for continuous innovation [7]. Big data is a new DevOps component that has helped to optimize the production lifecycle even further. We’re about to see another wave of operationalization as machine intelligence becomes more widespread. MLOps is a great place to begin.
MLOps may be used to design and optimize machine learning and artificial intelligence solutions. By integrating continuous integration and deployment (CI/CD) procedures, as well as proper monitoring, validation, and governance of ML models, data scientists and machine learning engineers may collaborate and speed up model development and production in an MLOps environment [5].
Efficiency, scalability, and risk reduction are the major benefits of MLOps [5]. MLOps enables data teams to develop models faster, deliver higher-quality machine learning models, and deploy and create models faster. MLOps also enables tremendous scalability and administration, enabling the supervision, control, management, and monitoring of thousands of models for continuous integration, delivery, and deployment [12]. MLOps, in particular, provides more tightly-coupled collaboration across data teams, eliminates conflict with DevOps and IT, and speeds up release velocity by ensuring repeatability of ML procedures [12]. Regulatory monitoring and drift-checking of machine learning models is widespread, and MLOps enables more transparency and faster replies to such requests, as well as increased compliance with an organization’s or industry’s norms.
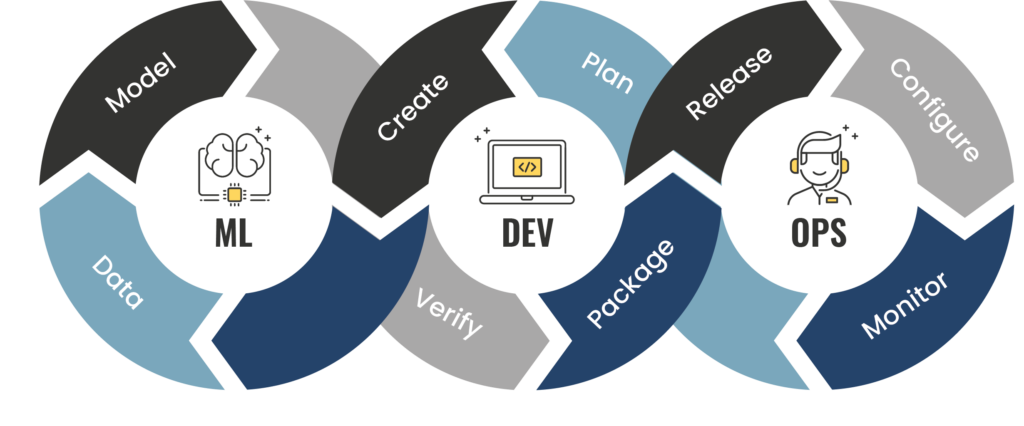
MLOps is evolved from normal DevOps at the end, as seen in fig 1. Both DevOps and MLOps pipelines involve a code-validate-deploy cycle [3]. The MLOps pipeline, however, contains additional data and model phases that are required to build/train a machine learning model, as shown in this picture. As a result, for each component of the workflow, MLOps differs from traditional DevOps. Although the terms “data” and “model” are wide, they are frequently used to refer to the processes of data labeling, data transformation or feature engineering, and algorithm selection [5]. In order to provide relevant results, models require data to be arranged in a specified way, which necessitates data transformation/feature engineering. The “Dev” and “Ops” sections are mostly the same at a high level.
Why do we need MLOps?
Commercialization of machine learning is tough [12]. The ingestion of data, preparation of it, training models, modifying them, deploying them, monitoring them, and explaining them are all part of the machine learning lifecycle. From Data Engineering to Data Science to Machine Learning Engineering, communication and handoffs between teams are also essential. High degrees of operational rigor are required for these processes to stay coordinated and functioning in tandem. The machine learning lifecycle includes experimentation, iteration, and ongoing improvement.
Four reasons why need MLOps [6]:
- Issues with Deployment: Businesses don’t realize the full benefits of AI because models are not deployed. Or if they are deployed, it’s not at the speed or scale to meet the needs of the business.
- Issues with Monitoring: Evaluating machine learning model health manually is very time-consuming and distracts resources from model development.
- Issues with Lifecycle Management: Even if they can identify model decay, organizations cannot regularly update models in production because the process is resource-intensive. There are also concerns that manual code is brittle, and the potential for outages is high.
- Issues with Model Governance: Businesses need time-consuming and costly audit processes in order to ensure compliance as a result of varied deployment processes, modeling languages, and the lack of a centralized view of AI in production across an organization.
Amazon SageMaker

Data preparation and labeling, model development, model training and tuning, model deployment, and model administration are all included in Amazon SageMaker [13]. It’s a fully managed service that lets data scientists and developers construct, train, and deploy machine learning models of any size rapidly and easily [1]. It has components for building, training, and deploying machine learning models, which may be used together or separately [1]. Sage Maker native services, which are purpose-built for machine learning and enable native integrations with Sage Maker features and capabilities, are often recommended. SageMaker’s versatility allows us to quickly access its capabilities and benefits within machine learning pipelines.
To allow customers to construct ML workflows using SageMaker’s training and deployment functionalities, we need to understand the SageMaker inputs and outputs. In a fully managed environment, SageMaker offers a number of training and deployment options [14]. The built-in algorithms of SageMaker may be used to solve a variety of machine learning problems. Training a model requires hyper-parameters, which are parameters that determine the method’s model architecture, as well as training data [13]. A model artifact is created as a consequence of a training job and saved in the S3 bucket that we specify. To deploy the model, we’ll need to provide the S3 location for the model assets, the AWS-managed inference container image for that method, and certain hosting configuration parameters like size, number of instances, feature scaling like auto scaling or AB testing, and so on [1]. We may use our own code and prebuilt container images with the built-in framework while still using our favorite frameworks like PyTorch, TensorFlow, or Scikit-learn [1].
We must utilize a built-in framework scenario to create the SageMaker training assignment, in which we must input both our training script and training data [14]. In this case, we’re utilizing a script that will need to be further developed with the help of a suitable framework. For a training task, we must describe the technique in hyper-parameters, as well as the output route, which is the S3 location where our model or artifact must be stored. In addition, we must select a computer environment.
SageMaker Studio

SageMaker studio is a fully comprehensive Integrated Development Environment (IDE) for machine learning [13]. It’s a synthesis of SageMaker’s most important features. In this environment, the user may write code in a notebook, do visualization, debugging, model tracking, and model performance monitoring all in one window. [13] It makes use of the following SageMaker features:
Amazon SageMaker Debugger
The SageMaker debugger will track the values of feature vectors and hyperparameters. Check for exploding tensors, analyze vanishing gradient problems, and use CloudWatch logs to record the tensor values in the s3 bucket. You can save time by using SaveConfig from the debugger SDK when the tensor values need to be validated, and SessionHook at the start of each debugging task.
Amazon SageMaker Model Monitor
The SageMaker model keeps track of model performance by looking at data drift. Both the set limitations and the feature statistics file are stored as JSON files. Each characteristic’s mean, median, quantile, and other statistics are included in the file. In the case of a constraint violation, the reports are kept in S3 and may be reviewed in detail. JSON, which includes data like feature names and infraction classifications (data type, min or max value of a feature, etc.)
Amazon SageMaker Model Experiment
SageMaker enables keeping track of several simple experiments (training, hyperparameter tweaking tasks, and so on). Values from the experiment may be imported into a pandas data frame, making analysis easier.
Amazon SageMaker AutoPilot
It’s simply a click away to use AutoPilot with ML. It’s done through a bespoke pipeline that’s been defined. DescribeAutoMlJob is an API. The purpose of the Machine Learning Pipeline is to provide you with control over your machine learning model. The source is Machine Learning Pipeline.
Running custom training algorithms
Use SageMaker to run the dockerized training image. The SageMaker invokes the function CreateTrainingJob, which executes training for a set amount of time. In TrainingJobName, specify the hyperparameters. TrainingJobStatus may be used to check the status.
Machine Learning With Amazon SageMaker:
In a production context, a model learns from millions of sample data pieces and produces results in seconds to milliseconds. Machine learning is a never-ending process. You must monitor conclusions, collect “ground truth,” and evaluate the model to determine whether it is drifting after it has been deployed. After that, you update your training data to reflect the new ground truth, improving the accuracy of your results. This is accomplished by retraining the model with new data. You keep retraining your model to improve accuracy as more and more example data becomes available.
The Amazon SageMaker Python SDK [11] includes a framework and generic estimators for training your model and orchestrating the machine learning (ML) lifecycle using SageMaker features and AWS infrastructures such as Amazon Elastic Container Registry (Amazon ECR), Amazon Elastic Compute Cloud (Amazon EC2), and Amazon Simple Storage Service (Amazon S3).
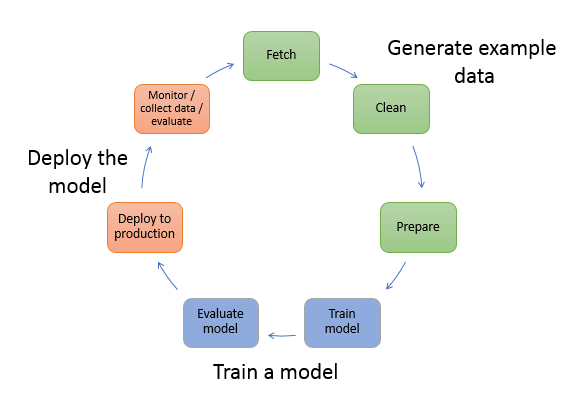
- Generate example data — Example data is required to train a model. The type of data you’ll require is determined by the business challenge you’re trying to solve using the model (the inferences that you want the model to generate). Assume you want to build a model to predict a number based on a handwritten digit as an input picture. We’ll need examples of handwritten numbers to train such a model.
Before utilizing example data for model training, data scientists generally spend a lot of time studying and preparing it, or “wrangling” it. We usually conduct the following to prepare data for analysis:
- Fetch the data — We may have in-house sample data repositories or we may utilize publicly available datasets. In most cases, we combine the datasets into a single repository.
- Clean the data — Inspect the data and clean it as needed to better model training. For instance, if the data contains a nation name property with the values United States and the United States, we may wish to update the data to make it more consistent.
- Prepare or transform the data — We may need to execute extra data transformations to increase performance. We may, for example, opt to mix qualities. Instead of utilizing temperature and humidity variables separately, we may combine them into a single attribute to achieve a better model if the model anticipates circumstances that necessitate deicing an airplane.
In SageMaker, we preprocess example data in a Jupyter notebook on your notebook instance. We use the notebook to fetch the dataset, explore it, and prepare it for model training.
2. Train a model — Model training includes both training and evaluating the model, as follows:
- Model training — To train a model, you’ll need an algorithm. A variety of things influence the algorithm we use. We might be able to utilize one of the SageMaker algorithms for a rapid, out-of-the-box answer. For a list of SageMaker’s algorithms and associated concerns. For training, we’ll additionally require computational resources. We may employ resources ranging from a single general-purpose instance to a distributed cluster of GPU instances, depending on the size of our training dataset and how soon we need the results.
- Evaluating the model — We examine our model once it has been trained to see if the accuracy of the inferences is satisfactory. To submit queries to the model for inferences in SageMaker, we utilize either the AWS SDK for Python (Boto) or the high-level Python library that SageMaker offers.
To train and assess our model, we utilize a Jupyter notebook in our SageMaker notebook instance.
3. Deploy the model — Before we connect a model with an application and deploy it, we usually re-engineer it. We may deploy the model independently of our application code thanks to SageMaker hosting services.
Training and Deployment of Model with Sagemaker
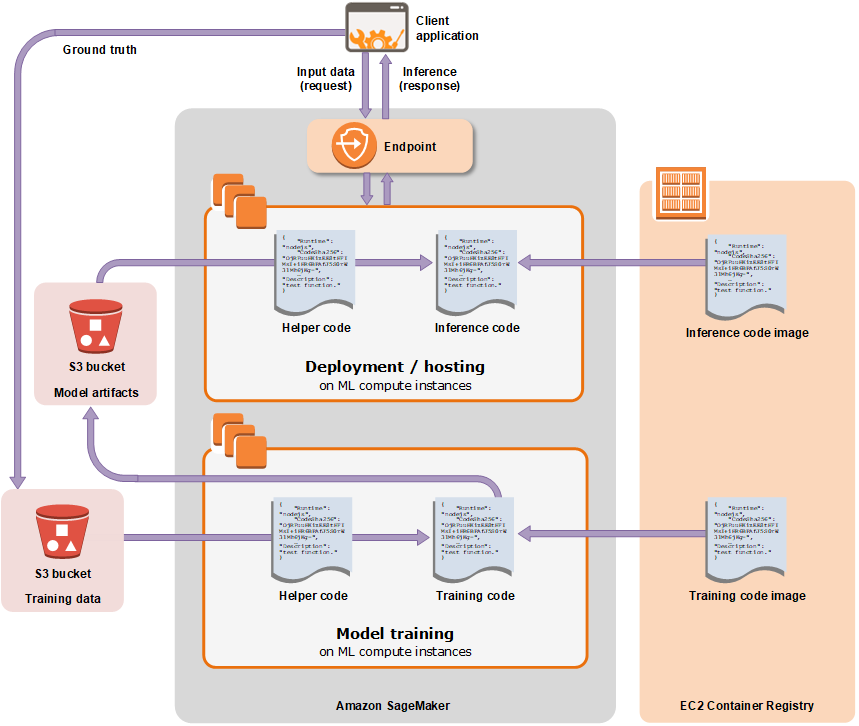
Model training:
To train a model in SageMaker, you create a training job. The training job includes the following information [1]:
- The URL of the Amazon Simple Storage Service (Amazon S3) bucket where you’ve stored the training data.
- The compute resources that you want SageMaker to use for model training. Compute resources are ML compute instances that are managed by SageMaker.
- The URL of the S3 bucket where you want to store the output of the job.
- The Amazon Elastic Container Registry path is where the training code is stored.
After constructing the training task, SageMaker launches the ML compute instances and trains the model using the training code and the training dataset. It saves the model artifacts and other output to the S3 bucket [1]. To create a training job, we may utilize the SageMaker UI or the SageMaker API. When we use the API to start a training task, SageMaker replicates the whole dataset on ML compute instances by default. To have SageMaker repeat a portion of the data on each ML compute instance, set the S3DataDistributionType field to ShardedByS3Key [1]. This field can be set using the low-level SDK.
Model deployment:
After you train your machine learning model, you can deploy it using Amazon SageMaker to get predictions in any of the following ways, depending on your use case[1]:
- For persistent, real-time endpoints that make one prediction at a time, use SageMaker's real-time hosting services.
- Workloads that have idle periods between traffic spurts and can tolerate cold starts, use Serverless Inference.
- Requests with large payload size up to 1GB, long processing times, and near real-time latency requirements, use Amazon SageMaker Asynchronous Inference.
- To get predictions for an entire dataset, use SageMaker batch transform.
SageMaker also provides features to manage resources and optimize inference performance when deploying machine learning models [1]:
- To manage models on edge devices so that you can optimize, secure, monitor, and maintain machine learning models on fleets of edge devices such as smart cameras, robots, personal computers, and mobile devices.
- To optimize Gluon, Keras, MXNet, PyTorch, TensorFlow, TensorFlow-Lite, and ONNX models for inference on Android, Linux, and Windows machines based on processors from Ambarella, ARM, Intel, Nvidia, NXP, Qualcomm, Texas Instruments, and Xilinx
Sagemaker Workflow
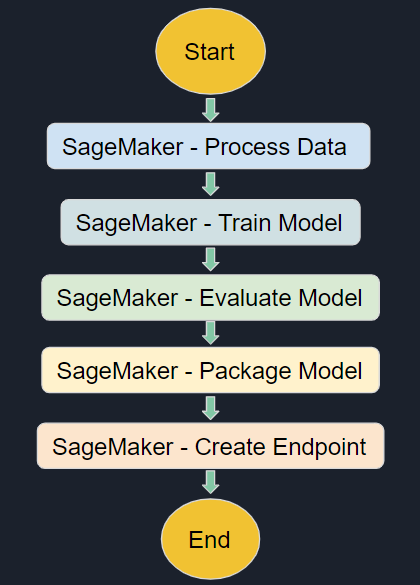
We can build scalable, distributed applications with state machines and AWS step functions. Creating workflows using Step Functions formerly necessitated knowledge of the Amazon Sagemaker Language (ASL).
Planned, event-driven, and metric-based retraining are the three basic retraining methodologies. Using the first two choices, we may create either schedule or event-driven triggers for the Amazon EventBridge, with step functions as our goal. The Amazon SageMaker model monitor may be used to keep track of metric-based training and send out an alarm when it’s time to retrain due to things like data drift.
Benefits of creating Amazon SageMaker workflows:
Workflows are utilized to take advantage of Amazon SageMaker’s enhanced training and deployment features. Reduce the size of the workflow tooling capacity footprint. Reduce the amount of time it takes to manage servers.
Examples:
· Amazon SageMaker Operators for Kubernetes
· Amazon SageMaker Components for Kuberflow
· Apache Airflow
CI/CD pipelines for Amazon SageMaker:
The first machine learning-specific continuous integration and continuous delivery (CI/CD) solution is Amazon SageMaker Pipelines (ML). With SageMaker Pipelines, you can create, automate, and manage end-to-end machine learning processes at scale.
By integrating CI/CD principles to machine learning, such as preserving parity across development and production environments, version control, on-demand testing, and end-to-end automation, Amazon SageMaker Pipelines lets you grow machine learning throughout your organization.
We must first identify the source code while architecting or creating SageMaker CI/CD pipelines. The next step is to determine the version inputs, which include typical data science libraries and packages. Then we must identify and secure our pipeline’s version artifacts, which may include container images if we’re employing a bring-your-own-algorithm scenario in buildings that include images. Next, we must decide which quality gate we want or, in certain cases, are compelled to include in our pipelines. Things like training metrics and data validation, for example, might be driven by corporate or industry-specific requirements. Then we must decide on our deployment strategy, which includes determining if our model will be consumed via SageMaker batch transform or whether we will distribute to a SageMaker endpoint. Finally, we must determine the operating requirements ahead of time. This is where cross-functional product teams come in handy, because they can grasp the logs and metrics that matter to each of our cross-functional team’s personas.
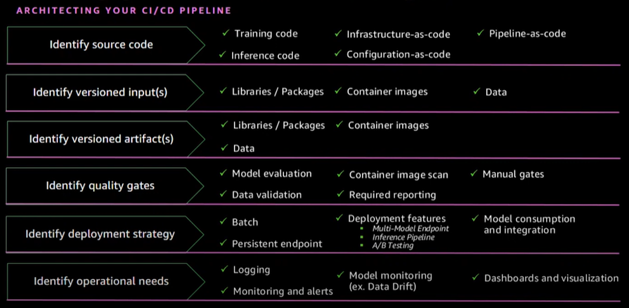
Security at SageMaker
Cloud Security:
AWS employs a shared responsibility approach, in which AWS is responsible for safeguarding the cloud’s infrastructure and security. AWS is in charge of safeguarding the infrastructure that powers AWS Cloud services. This includes customer-selected services, IAM key management, assigning privileges to various users, keeping credentials safe, and so on [14]. As part of the AWS compliance initiatives, third-party auditors examine and verify the efficacy of our security.
Data Security:
In Amazon SageMaker, the AWS shared responsibility paradigm applies to data protection. SageMaker keeps the data and model artifacts encrypted in transit and rest. Requests for a secure (SSL) connection to the Amazon SageMaker API and console. Encrypted notebooks and scripts are using AWS KMS (Key Management Service) Key. If the key is not available, these are encrypted by using the transient key. This transitory key becomes outdated after decoding [14]. For data protection purposes, AWS account credentials should be protected and individual user accounts with AWS Identity and Access Management (IAM). As a result, each user is only given the rights they need to do their job obligations.
Benefits of AWS SageMaker
SageMaker provides a variety of computing instances with varying CPU, GPU, and RAM capacities. With only one click, we can pick any instance from 2 core CPUs to 96 core CPUs, and 4GB RAM to 768GB RAM [20]. SageMaker includes Amazon’s libraries, which feature high-performing algorithms for training models utilizing Amazon’s pre-trained models. In training, it employs a debugger with a predetermined set of hyperparameters. Aids in the rapid deployment of an end-to-end machine learning pipeline. SageMaker Neo is used to deploy machine learning models at the edge. While executing the training, ML compute instances offer the instance type. AWS also provides a broad community of data scientists, software engineers, AI researchers, and industry specialists with vast expertise in the field of machine learning. When you use SageMaker, you’ll be able to tap into this community and work with these professionals. One of the nicest features of AWS SageMaker is the cost. We don’t have to pay for resources we don’t utilize using SageMaker. Data scientists may use AWS SageMaker to create Jupyter notebooks [20]. The data scientist community appreciates this benefit since it allows them to utilize Jupyter notebooks for the whole ML lifecycle — creating, training, and deploying models.
MLOps Practice benefits
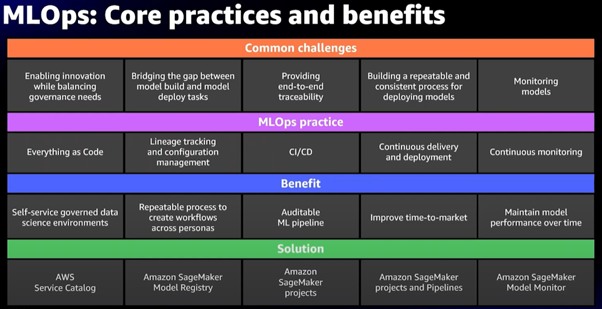
Advanced Sagemaker features
AWS has announced Sagemaker Ground Truth Plus [15], a new service that employs an expert workforce to produce high-quality training datasets more quickly. SageMaker Ground Truth Plus employs a labeling workflow that includes active learning, pre-labeling, and machine validation approaches, as well as machine learning techniques. The new service, according to the business, saves up to 40% on expenditures and doesn’t require consumers to have extensive machine learning knowledge. Users can utilize the service to construct training datasets without having to write their own labeling apps. In Northern Virginia, SageMaker Ground Truth Plus is now available.
SageMaker Inference Recommender[16] is a new tool that helps customers pick the best available compute instance for deploying machine learning models for the greatest performance and cost. According to AWS, the tool chooses the appropriate compute instance type, instance count, container settings, and model optimizations automatically.
Except for the AWS China regions, Amazon SageMaker Inference Recommender is normally accessible in all locations where SageMaker is offered.
AWS has announced a trial of a new SageMaker Serverless Interface[17] option that allows customers to quickly install machine learning models for inference without having to worry about configuring or managing the underlying infrastructure. Northern Virginia, Ohio, Oregon, Ireland, Tokyo, and Sydney are among the cities where the new option is accessible.
AWS recently announced SageMaker Training Compiler[17], a new technology that can speed up deep learning model training by up to 50% by making better use of GPU instances. From high-level language representation to hardware-optimized instructions, this feature covers deep learning models. Northern Virginia, Ohio, Oregon, and Ireland are among the first to get a new function.
Users may now monitor and debug[17] Apache Spark operations running on Amazon Elastic MapReduce (EMR) from SageMaker Studio notebooks with a single click, according to AWS. You can now identify, connect to, build, terminate, and manage EMR clusters straight from SageMaker Studio, according to the firm.
AWS also released SageMaker Studio Lab[18], a free offering to assist developers to learn and experimenting with machine learning techniques. AWS just unveiled Amazon SageMaker Canvas[19], a new machine learning service. Users will be able to create machine learning prediction models using a point-and-click interface using the new service.
Conclusion
In recent years, machine learning has progressed in leaps and bounds. Several businesses have made investments in this technology and are reaping the rewards. With such a high demand for AI applications, the supply of tools and technology has been fast increasing. Most businesses want an “ideal” machine learning platform that can help them design, train, and deploy models at all phases of the ML lifecycle. Though we feel there is no one-size-fits-all platform, AWS Sagemaker comes close owing to its flexibility and scalability, which are required to develop a high-performing model while being cost-effective [20]. SageMaker is a wonder drug for every machine learning issue [21].
AWS charges each SageMaker user for the computation, storage, and data processing resources needed to design, train, execute, and log machine learning models and predictions, as well as the S3 costs associated with preserving the data sets used for training and forecasting [13]. The SageMaker framework’s design allows for the end-to-end lifecycle of machine learning applications, from model data generation through model execution, and its scalable architecture allows for flexibility. That implies we can use SageMaker on its own for model construction, training, and deployment. A developer may connect SageMaker-enabled Machine Learning models to other AWS services, such as the Amazon DynamoDB database for structured data storage, AWS Batch for offline batch processing, or Amazon Kinesis for real-time processing, regardless of the degree of abstraction used. Developers may use a number of APIs to connect with Amazon SageMaker. The first is a web API that enables developers to remotely control the SageMaker server instance. While the web API is independent of the developer’s programming language, Amazon provides SageMaker API bindings for a variety of languages, including Python, JavaScript, Ruby, Java, and Go. AWS SageMaker now has managed Jupyter Notebook instances available for interactively programming SageMaker and other apps. With all of the above, AWS Sagemaker is shaping out to be a fantastic tool.
Reference
[1] https://docs.aws.amazon.com/sagemaker/latest/dg/whatis.html
[4] https://aws.amazon.com/sagemaker/mlops/
[5] https://databricks.com/glossary/mlops
[6] https://www.datarobot.com/lp/why-you-need-mlops/)
[7]https://mobcoder.com/blog/mlops-methods-and-tools-of-devops-for-machine-learning/
[11] https://sagemaker.readthedocs.io/
[12] https://databricks.com/glossary/mlops
[13] https://www.xenonstack.com/blog/amazon-sagemaker-machine-learning-platform
[14] https://www.youtube.com/watch?v=8ZpE-9LnaJk
[15] https://aws.amazon.com/about-aws/whats-new/2021/12/amazon-sagemaker-ground-truth-plus/
[16]https://aws.amazon.com/about-aws/whats-new/2021/12/amazon-sagemaker-inference-recommender/
[17] https://aws.amazon.com/about-aws/whats-new/2021/12/amazon-sagemaker-serverless-inference/
[18] https://studiolab.sagemaker.aws/
[19] https://techcrunch.com/2021/11/30/aws-gets-a-no-code-ml-service/
[20] https://attri.ai/blog/advantages-of-aws-sagemaker
[21] https://towardsdatascience.com/what-makes-aws-sagemaker-great-for-machine-learning-c8a42c208aa3
[22] https://www.projectpro.io/recipes/explain-amazon-sagemaker-and-advantages-of-sagemaker
Intro to MLOps using Amazon SageMaker was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts

")





