



How to Run Stable Diffusion 3X Faster at Lower Cost
Last Updated on May 2, 2023 by Editorial Team
Author(s): Towards AI Editorial Team
Originally published on Towards AI.
Available for Early Access on OctoML Compute Service on AWS
This is a Sponsored Guest Post brought to you by OctoML.
For a team of AI fanatics like us, it’s been a thrill to see the AI market take off over the last 12 months. The barrier to entry is getting lower for AI builders. The prohibitive expense of training new models is an upfront cost that is increasingly being fronted by closed source API providers like OpenAI, as well as researchers and projects building open source foundational models such as Stable Diffusion, Whisper, LLaMA and others.
Even with upfront training expenses drastically reduced, we continue to hear that the long term compute costs of production deployment threatens the economic viability of any AI offering. And that’s if the developer or enterprise can even get access to the AI compute they want to create their app/service in the first place.
At OctoML, we are on a mission to deliver affordable AI compute services for those who want control over the business they are building. That’s why we built a new compute service, available now in early access. It delivers AI infrastructure and advanced machine learning optimization techniques that you can only find in large scale AI services like OpenAI, but gives you the power to control your own API, choose your own models and work within your AI budget.
Early access users can try the fastest Stable Diffusion 2.1 model (with no change to the accuracy/performance of the model) on the market, without needing to train or retrain the model. Here is some early data that demonstrates the performance gains:
Stable Diffusion Runs Blazing Fast on A10Gs Why Are You Waiting on A100s?
We are hearing time and time again from AI developers that GPU availability is hampering their ability to create their new AI-powered app. When we double-click on these conversations, we are finding that organizations are taking it on faith that only newer NVIDIA hardware i.e. A100s deliver the price/performance they need to run their models at scale. That’s why we are excited to share that A10Gs can deliver the right user experience i.e. 1.35 seconds, that any mainstream Stable Diffusion powered-app needs. And most importantly A10Gs ARE available everywhere and aren’t being rationed like the A100s are.
Not only is OctoML’s optimized version of Stable Diffusion 2.1 blazing fast, it actually outperforms by 30% the best in class do-it-yourself configuration available to sophisticated users who have experience in machine learning engineering. The DIY configuration running on the A100 uses the xFormers package from Meta that leverages leading edge memory efficient attention implementations, fused kernels, and other sophisticated techniques to get high performance on GPUs running on the beefiest hardware (assuming you can get it). Even with that level of DIY sophistication and running on A100s the OctoML version of Stable Diffusion 2.1 actually outperforms it on less powerful hardware.

How does OctoML stack up against hosted services? 3x faster, ⅕ the cost.
When running AI in production, hosted services like HuggingFace (Inference Endpoints) are popular options because they’re easy to use and reduce the headaches of manual deployment and infrastructure management. Now that we’ve grounded you in the fact that you don’t need the latest/greatest NVIDIA hardware to run your models, let’s compare to HuggingFace, which is the most popular distribution source for Stable Diffusion.
Whereas the HuggingFace version running on their Inference Endpoints–that infrastructure has been designed for and optimized for the ML researcher community–has not been developed to deliver best-in-class compute services.
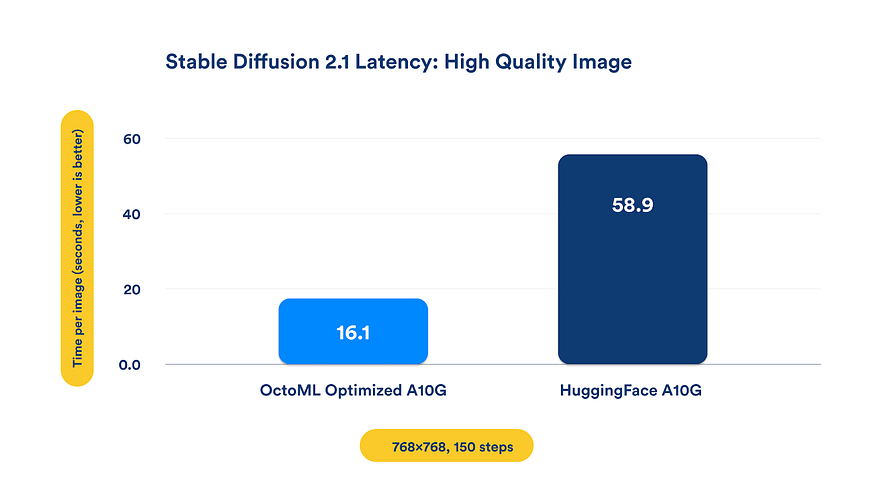
As a proof point of that we highlight that our Stable Diffusion model hosted in our compute service has a speedup range between 2X on a lower end image quality (512×512, 30 steps) to 3X better at the very high image quality (768×768, 150 steps).



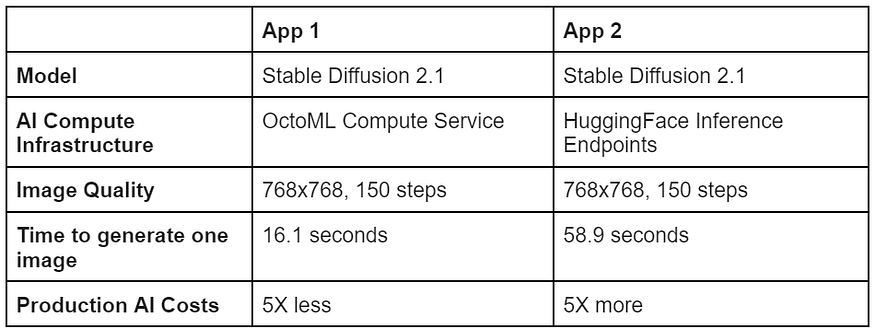
How to win the battle of the AI apps
OctoML gives you the choice and flexibility to tailor price and performance for your use case and the experience you want to deliver your user.
It can also give your business big competitive advantages.
Imagine you have an application running Stable Diffusion from OctoML, and a competing AI-powered app is using Hugging Face. It would take them nearly 4X longer to deliver a customer an image at the same quality– nearly a minute! And it would have cost them 5X as much as you would be paying using OctoML. If your image quality requirements are flexible, you could deliver images with OctoML for under 1/100th of a cent.
Another unique aspect of the OctoML approach is that unlike other solutions on the market, it supports friction-free fine-tuning to customize Stable Diffusion against your own data sets. Other approaches require that the model be recompiled every time there is fine-tuning which in the case of doing so with TensorRT can take approximately 30 minutes.
To get early access to the OctoML compute service early access, please sign up here.
If you are interested in also working with us on your fine-tuning requirements/needs, or if you have a use case to leverage our Stable Diffusion model outside of our compute service because you built your own serving infrastructure, please contact us here so we can schedule a time to talk.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

