



GPT-3 Explained to a 5-year-old
Last Updated on March 29, 2021 by Editorial Team
Author(s): Daksh Trehan
Natural Language Processing
If you haven’t been paying attention to the wonders of AI, you haven’t been attentive at all!
The web has gone crazy over an interactive tool GPT-3. Its use-cases and future possibilities are amazing. (G)enerative (P)retrained (M)odel is the third version of the natural language processor. You can expect it to behave like your friend Donald, throw it a prompt and it will do as directed.
If you would like to peek in the future, check out how developers are using GPT-3. Without a doubt, we can say that our world is full of AI use cases. Ranging from suggesting you something to Amazon to driverless cars, AI got you all covered up. Even, there are high chances AI suggested you this article, or an AI tool wrote it. Yes, you heard me right, that’s all GPT3 is all about.
GPT-3 is a huge network that can perform human-like language processing tasks. It can act as a writer, a journalist, a poet, an author, a researcher, or a writing bot. It is also considered as the first step towards Artificial General Intelligence(AGI). AGI is the ability of machines to learn and perform mimic human a-like tasks.

There was a time when technology was considered cryptic. But as we advance, it must be introduced to amasses. To understand the basics of how GPT-3 works, we must go through the basics of Machine Learning that fuels it. Machine Learning is an integral part of Artificial Intelligence. It provides the machine the capability to better themselves with the experience.
There are two types of Machine Learning algorithms: Supervised and Unsupervised.
Supervised learning includes all those algorithms that must need labeled data. In other words, assume your machine to be a 5-year-old kid. You wish to teach her a book and then take a test to know if he had learned anything or not. In supervised learning, we feed the machine with labeled data. We then test it to know if it has learned anything or not.
Supervised learning isn’t something humans amass intellect. Rather, most of the time, we collect knowledge based on our experience, or intuitions. That’s what roughly you can regard as unsupervised learning.

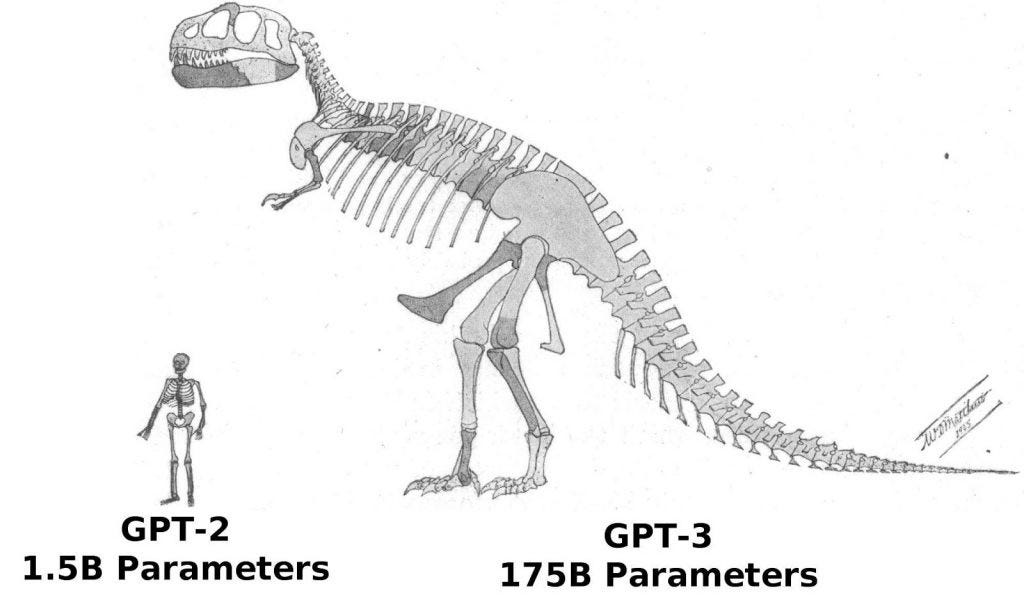
GPT-3 employs unsupervised learning. It is capable of meta-learning i.e. learning without any training. GPT-3 learning corpus consists of the common-craw dataset. The dataset includes 45TB of textual data or most of the internet. GPT-3 is 175 Billion parameter models as compared to 10–100 Trillion parameters in a human brain.
Answer to life, the universe, and everything is assumed to be 4.398 trillion parameters. The way GPTs family is growing i.e. approximately by 100x times per year is both amazing and a cause to worry.
We can always expect Machine learning models to yield good accuracy. But working on natural languages isn’t something they’re capable of. To counter the issue, we convert text into numbers using embedding and pass them to our models. The models use encoders and decoders with the help of an attention mechanism.
Recurrent Neural Networks(RNN), is a technique enabling us to work on Natural Language. But due to the enormous size of textual data, we can’t expect it to learn everything. To make better usage of our data we use an attention mechanism. The attention mechanism works exactly like our brain. When we feed information to our brain, it filters out important data and flushes the rest. The attention mechanism helps to keep a score of every embedding. The score enables our model to filter out irrelevant embeddings.
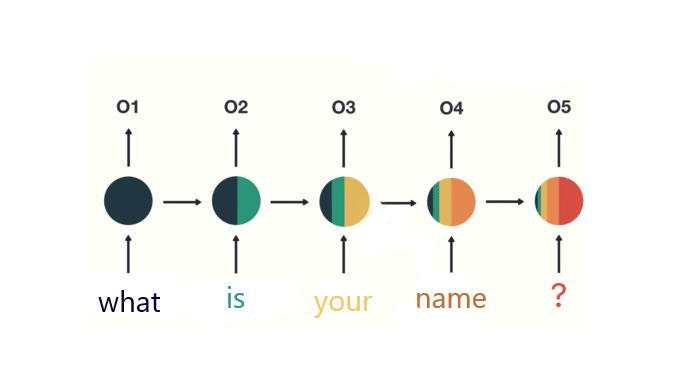
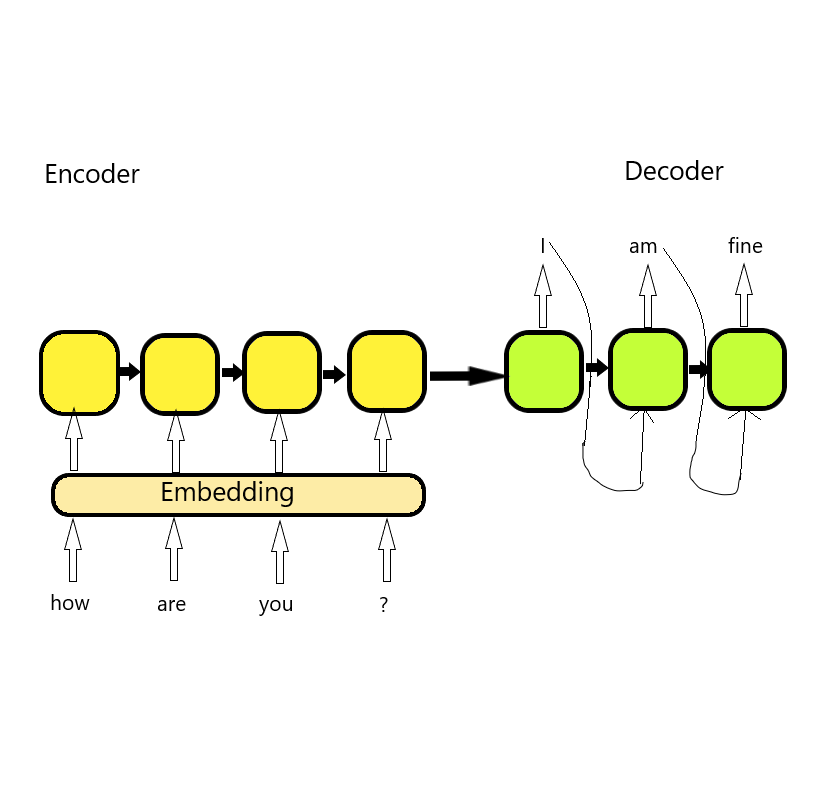
When we feed our textual data to our model, it passes through the encoder and produces vectors. The produced vectors are further inputted into the attention mechanism. The combined workflow helps to produce next word prediction. In simple words, it is “fill in the blanks” based on how confident you’re with your answer. As we hold a grip over languages we get better at it and so does our confidence. With more training and experience our model performs better at prediction. At last, we feed the next input word with the former output prediction to the decoder. The cycle continues, helping us to generate sentences and get better at AGI.
The main highlight of GPT-3 is its large corpus of data and its training. The training is not domain-specific yet enables it to master any domain-specific task. Re-programming is easy as it has learned too much from the dataset that it has now started to memorize. Ask it to write a SQL query, it will ace at it. Ask it to assist in sports writing, it will again ace at it.

GPT-3 works better with few-shot learning i.e. when you provide it with a prompt and few examples. It is like that, you gave some books to a freshman and asked her to solve questions. Sometimes she did and other times she fails. So you keep on providing her more books and question that makes her better at it. Sometimes by learning again and sometimes by looking over similar examples.
GPT-3 is yet another machine and we can’t expect machines to learn with a lot of examples. When we learn to drive we pick too many places to brush up our skills. We start from highways with a lot less traffic, once we gain confidence. Then we move on to suburbs with a little more traffic. And at last, find our way towards the busiest street to get better at it. If you learn to drive only on a highway you can’t drive better in suburbs or streets. Similarly, if we want a better model we need to provide it different circumstances to learn.
GPT-3 learned from us and is our best shot at AI. But it can’t behave like us, after-all kids don’t need to see millions of examples to learn something new. It learns from the internet and sometimes it also ingests its negativity. GPT-3 can mimic natural language but when it comes to natural thoughts AI still needs to up its game. There is a thin line between Natural language and Natural thoughts. GPT-3 has shown us scaling up the language model can improve accuracies. And, to generate human-like language all we don’t need a soul but plenty of data.
Back when I was a kid, our teacher would give us a scenario and ask us to write about it. As a kid I spent hours imagining fake plots and give it to our teacher, he would return me with low scores.
For years, I kept doing this and was never able to find the reason for the same. Then one day I realized I was doing it all wrong. I was too busy focusing on imaginative scenarios, but all it needs to get good grades was “grammar”. Apparently, he was teaching us how to “write” and not how to think “creatively”. In my defense, maybe my imagination was my strength but my grammar wasn’t.
That’s exactly what GPT-3 is doing, expect it to be a writing bot. It derives most of its output from people’s previous writings. And all it cares about is to produce something that looks human-produced. It focuses on “style” rather than “creativity or understanding”. Grammar is its programming language, be clear and you got great accuracies.
With no denial, it is good at prediction. But it is neither designed to store facts nor to retrieve them like a human brain. It is more of a keyword pattern matching algorithm more like an SEO.
It is a language smoke machine due to no exposure to the practical world it lacks human traits. Even after knowing everything about humankind. It is an algorithm and it is not fair to expect it to spat out any reasoning. It lacks IQ that differentiates humans from the machine and I hope that stays true at least quite for a while.
References:
https://medium.datadriveninvestor.com/gpt-3-ai-overruling-started-15fd603470f2
https://pub.towardsai.net/ai-copy-assistant-powered-by-gpt-3-d5b175a025e1
https://theconversation.com/gpt-3-new-ai-can-write-like-a-human-but-dont-mistake-that-for-thinking-neuroscientist-146082
https://pub.towardsai.net/email-assistant-powered-by-gpt-3-ba39dfe999d3
https://dev.to/ben/explain-gpt-3-like-i-m-five-477b
https://in.springboard.com/blog/openai-gpt-3/
https://arxiv.org/pdf/2005.14165.pdf
Feel free to connect:
Portfolio ~ https://www.dakshtrehan.com
LinkedIn ~ https://www.linkedin.com/in/dakshtrehan
Follow for further Machine Learning/ Deep Learning blogs.
Medium ~ https://medium.com/@dakshtrehan
Want to learn more?
Are You Ready to Worship AI Gods?
Detecting COVID-19 Using Deep Learning
The Inescapable AI Algorithm: TikTok
GPT-3: AI overruling started?
Tinder+AI: A perfect Matchmaking?
An insider’s guide to Cartoonization using Machine Learning
Reinforcing the Science Behind Reinforcement Learning
Decoding science behind Generative Adversarial Networks
Understanding LSTM’s and GRU’s
Recurrent Neural Network for Dummies
Convolution Neural Network for Dummies
Cheers
GPT-3 Explained to a 5-year-old was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






