



The NLP Cypher | 03.28.21
Last Updated on July 24, 2023 by Editorial Team
Author(s): Quantum Stat
NATURAL LANGUAGE PROCESSING (NLP) WEEKLY NEWSLETTER
A Step Forward in Open Sourcing GPT-3
In the 02.21.21 newsletter, we highlighted EleutherAI’s ambitions for building an open-sourced version of the uber large GPT-3 175B param model. And this week, they released two versions in the sizes of 1.3B and 2.7B params as a stepping stone towards paradise. Here’s how the current GPT models stack up. ?
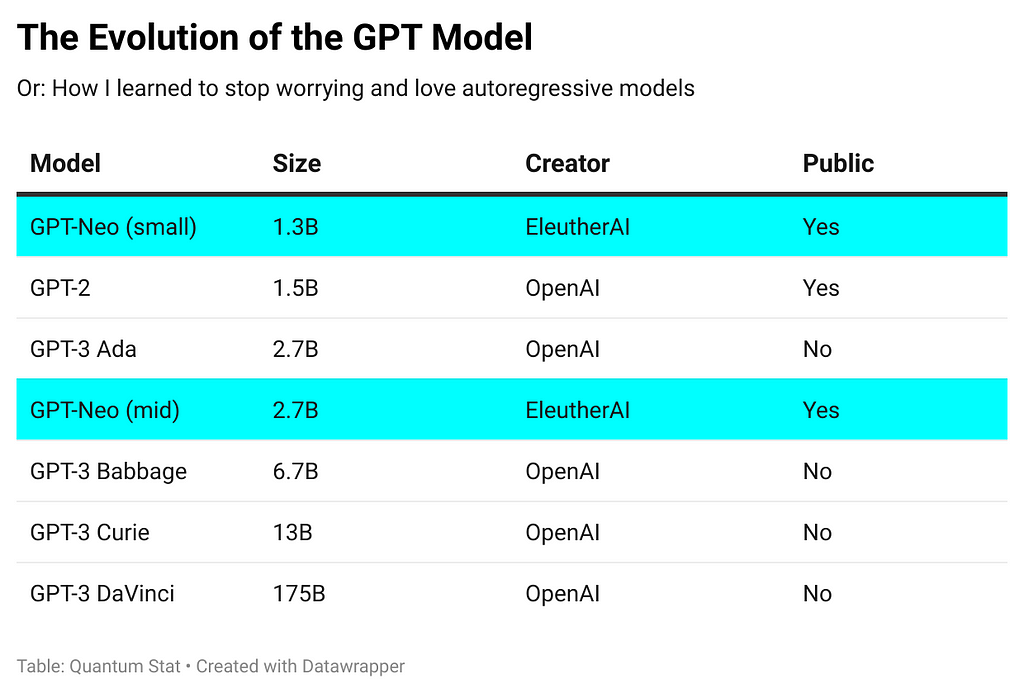
“The release includes:
The full modeling code, written in Mesh TensorFlow and designed to be run on TPUs.
Trained model weights.
Optimizer states, which allow you to continue training the model from where EleutherAI left off.
A Google Colab notebook that shows you how to use the code base to train, fine-tune, and sample from a model.”
Their notebook requires a Google storage bucket to access their data since TPUs can’t be read from local file systems. You can set up a free-trial fairly easily, they provide a link in the notebook.
Colab:
Code:
Hacker Side Note:
Earlier this year, EleutherAI apparently suffered a DDOS attack. Connor Leahy, a co-founder, tweeted a visualization of abnormal traffic receiving a bunch of HTTP 403s on the pile dataset. If you would like to help donate to their cause (and towards secured hosting), go here: SITE.
Visualization of abnormal traffic
Millions of Translated Sentences in 188 Languages
Woah, that’s a lot of translated corpora. Helsinki-NLP collection is menacing collection of monolingual data that includes:
“translations of Wikipedia, WikiSource, WikiBooks, WikiNews and WikiQuote (if available for the source language we translate from)”
Helsinki-NLP/Tatoeba-Challenge
Backprop AI | Finetune and Deploy ML Models
Library can fine-tune models with 1 line of code.
Features:
- Conversational question answering in English
- Text Classification in 100+ languages
- Image Classification
- Text Vectorization in 50+ languages
- Image Vectorization
- Summarization in English
- Emotion detection in English
- Text Generation
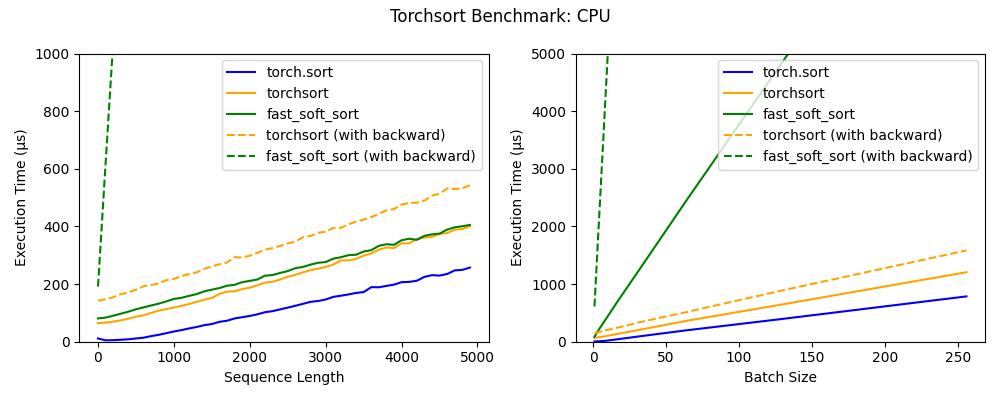
TorchSort
Mr. Koker hacked a Google library for sorting and ranking and converted it into PyTorch, (faster than the original) ?. Areas where ranking is used: Spearman’s rank correlation coefficient, top-k accuracy and normalized discounted cumulative gain (NDCG).
Benchmarks:
Dive Into Graphs (DIG) | A New Graph Library
This new library helps in four research areas:
- Graph Generation
- Self-supervised Learning on Graphs
- Explainability of Graph Neural Networks
- Deep Learning on 3D Graphs
Awesome Newspapers | A Possible Data Source?
A curated list of online newspapers covering 79 languages and 7,102 sources. The data hasn’t been scraped it just indexes the sources.
State of Search | The DeepSet Connection
DeepSet walks you down memory lane in open domain qa/search. Beginning with the 2 stage Retriever Reader (ha! remember reading the Chen et al. 2017 paper?), then to RAG or generated responses (as opposed to extractive), and finally heading into summarizing (using Pegasus), and their latest “Pipelines” initiative. They also discuss a future initiative of using a query classifier to classify which type of retrieval their software should use (dense vs. shallow). This is really cool because it shows their interest in using hierarchy in AI decision-making by using… AI. ?
Haystack: The State of Search in 2021
Stanford’s Ode to Peeps in the Intelligence Community to Adopt AI
An interesting ? white paper from Stanford giving advice and warning to the US intelligence community about adopting AI and staying up-to-date with the fast moving field to stay competitive. They also recommend an open-sourced intelligence agency. ?
“…one Stanford study reported that a machine learning algorithm could count trucks transiting from China to North Korea on hundreds of satellite images 225 times faster than an experienced human imagery analyst — with the same accuracy.”
Matrix Multiplication — Reaching N²
What will it take to multiply a pair of n-by-n matrices in only n2 steps??
FYI, matrix multiplication is the engine of all deep neural networks. The latest improvement, “shaves about one-hundred-thousandth off the exponent of the previous best mark.” Take that Elon!
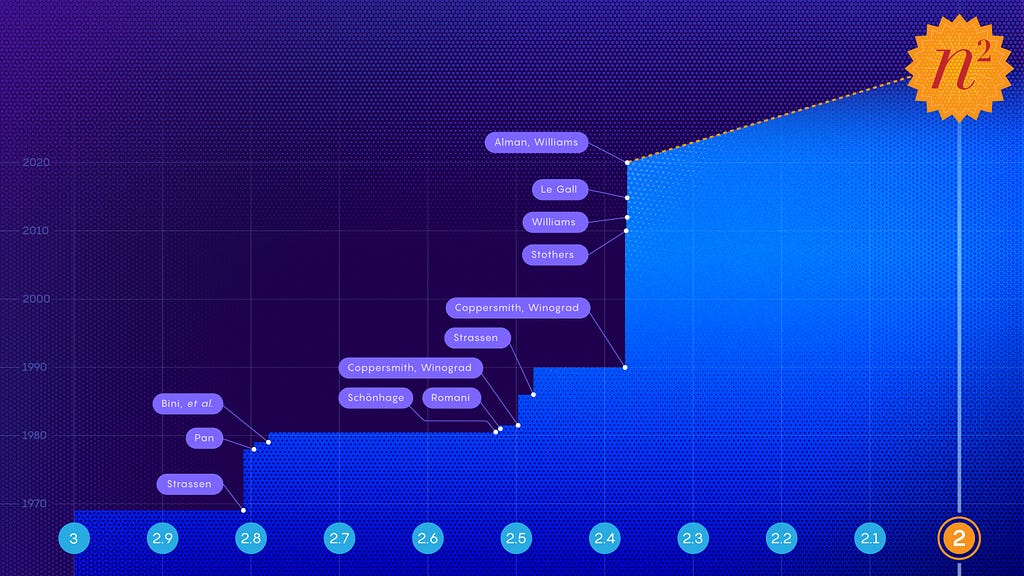
Matrix Multiplication Inches Closer to Mythic Goal
The Repo Cypher ??
A collection of recently released repos that caught our ?
GENRE (Generative Entity Retrieval)
GENRE uses a sequence-to-sequence approach to entity retrieval (e.g., linking), based on a fine-tuned BART architecture. Includes Fairseq and Hugging Face support.
Shadow GNN
A library for graph representational learning. It currently supports six different architectures: GCN, GraphSAGE, GAT, GIN, JK-Net and SGC.
Unicorn on Rainbow | A Commonsense Reasoning Benchmark
Rainbow brings together six pre-existing commonsense reasoning benchmarks: aNLI, Cosmos QA, HellaSWAG, Physical IQa, Social IQa, and WinoGrande. These commonsense reasoning benchmarks span both social and physical common sense.
TAPAS [Extended Capabilities]
This recent paper describes an extension to Google’s TAPAS table parsing capabilities to open-domain QA!!
MMT-Retrieval: Image Retrieval and more using Multimodal Transformers
Library for using pre-trained multi-modal transformers like OSCAR, UNITER/ VILLA or M3P (multilingual!) for image search and more.
AdaptSum: Towards Low-Resource Domain Adaptation for Abstractive Summarization
The first benchmark to simulate the low-resource domain Adaptation setting for abstractive Summarization systems with a combination of existing datasets across six diverse domains:, email , movie review, debate, social media, and science, and for each domain, we reduce the number of training samples to a small quantity so as to create a low-resource scenario.
CoCoA
CoCoA is a dialogue framework providing tools for data collection through a text-based chat interface and model development in PyTorch (largely based on OpenNMT).
Dataset of the Week: MasakhaNER
What is it?
A collection of 10 NER datasets for select African languages: Amharic, Hausa, Igbo, Kinyarwanda, Luganda, Naija Pidgin, Swahili, Wolof, and Yoruba. The repo also contains model training scripts.
Where is it?
Every Sunday we do a weekly round-up of NLP news and code drops from researchers around the world.
For complete coverage, follow our Twitter: @Quantum_Stat

The NLP Cypher | 03.28.21 was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






