



From Notebook to Production
Last Updated on November 29, 2021 by Editorial Team
Author(s): Eija-Leena Koponen
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
DevOps
How to Bridge the Gap between Data Science and Engineering?
Data Scientist was hyped to be the 21st century sexiest job. Now, in 2021, most of the companies have adopted some Data Science in their processes and core tasks, analyzing their customer base or optimizing and automating some of the manual processes. On the other hand, data scientists are still a very heterogeneous bunch of people, some having a background in Statistics, some in mechanical engineering, and some in Physics to name a few. Of course, there is increased output from actual Data Science Master’s programs to the workforce, but the majority of the folks are still self-taught (including me).
The bottleneck no longer seems to be the data but how to bring the exploratory projects into production. In other words, make Software Engineers and Data Scientists talk the same language to smooth the process.
Data Scientists are usually very good with fetching the data, wrangling it a bit, making visualizations, some initial models, and notebooks. But when it comes to the production phase, actually providing the model to end-users and integrating it to the (existing) tools, Data Scientist needs to pass the baton to Software engineers. Unfortunately, for a software engineer, these notebooks and messy scripts are often like shoddy cardboard models, and translating that to a real thing takes (way too much) time. So what would be the first steps to encourage everyone to take to bridge the gap?
Here are a few steps we recommend!
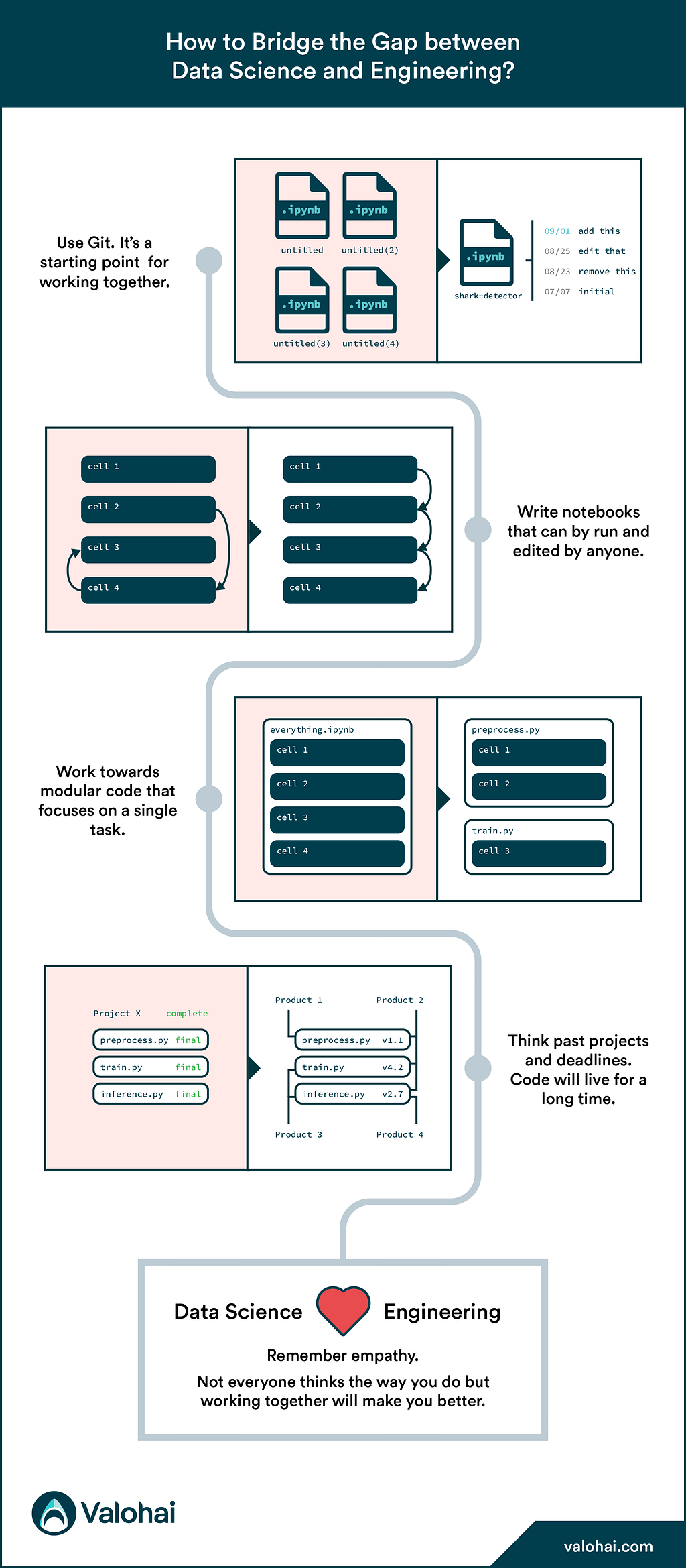
Using Git
Version control is a system that records changes to a file or set of files over time so that you can see specific versions later. Services like Github, Bitbucket, and others make it easy to see what was done with multiple people working on a single code base. This is to avoid unintentional overwrites and other mistakes. You have version control for your documents on Google Docs, so why not have that for your code too?
In addition to version control (which is worth it even when working alone), your code will be stored on the cloud, accessible for all of your project members and not on someone’s laptop, ready to be forgotten. As a result, your teammates can be aware of what you are building and pick up where you left off.
There’s also a side effect — code tends to be less spaghetti-like when you know someone will read it.
Reproducible notebooks
Notebooks are the holy grail of Data Scientists; they are super handy for exploring your local machine! Nowadays, there are many online providers too, e.g. Kaggle kernels, Sagemaker, Google Colab to name a few.
Notebooks, however, give quite many liberties for Data Scientists. For example, you can run the code in any order you want — and trust me; people do — they include loads of checks and other “unnecessary” things for anyone else. Then there’s the setup hassle; which version of python, pandas, and other libraries did you have installed, and what are the other dependent libraries when trying to reproduce whatever the other DS just did. Thus they are far from production-ready.
Valohai has done a unique solution to this problem: Jupyhai. You can run a Valohai cloud execution from your local Jupyter notebook. It requires the whole notebook to be run simultaneously and from top to bottom, forcing data scientists to keep the code cleaner and in order. You don’t need Valohai to adopt this principle; every notebook will be easier to understand if written this way.
Voilá! You are one step close to the production code.
Modular work
When you need to scroll and scroll the notebook, it’s time to start thinking modularly. Splitting your work into steps forming a pipeline requires a little extra work now, but it will pay in the longer run.
You can run only one piece at a time, see where the possible errors and bugs are and the bottleneck of your project. Maybe even write some tests to ensure future changes to a single part don’t break the whole.
It also helps in staying organized and eases code maintainability. This way, it might also be easier to explain to a new person the flow of your work on a higher level and focus on one thing at a time.
Definition of done
Hopefully, many of your projects turn to products; a never-ending loop where there is always something to iterate on, make better, optimize, and thus the definition of done is very vague.
Here we can learn again from frameworks such as agile development. Of course, not all parts of it work for Data Science, but trying to plan sprints, prioritize each of them, clearly define tasks with deliverables and timelines, and use retrospectives and demos might make you feel that you finished something.
In addition, communication with developers (and business stakeholders) is more straightforward.
Last but not least: empathy
We are all different, all from various backgrounds, and diversity is a richness. But having diverse thoughts and ways of doing requires work. It is so much easier to communicate with a person, e.g. from a similar educational background on a project, but, well, then it is a project done with only one set of skills.
So, for all the Data Scientists reading this: developers aren’t trying to make your life miserable by introducing tools and frameworks working for them. For all the developers: Data Scientists aren’t producing incomprehensible spaghetti code on purpose; it’s usually a different way of thinking and lack of knowing better — this whole industry is where you were 10–15 years ago.
Trying to understand and learn from others, trying to see the other’s perspective, i.e. being empathetic, allows you to work on way more incredible things than you’d do on your own!
Recap
Giving the wild bunch of Data Scientists in your team frameworks and best practices that help them do their work, you promote making the work understandable and transferable to others. Tackle one workflow obstacle at a time and only after start tackling MLOps and tooling.
DS ❤️ Dev
Originally published at https://valohai.com.
From Notebook to Production was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")