



How to train a Topic Tagging model to assign high-quality topics to articles
Last Updated on January 6, 2023 by Editorial Team
Last Updated on November 29, 2021 by Editorial Team
Author(s): Fabio Chiusano
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Natural Language Processing
From training set creation to the trained model
Topic Tagging is the process of assigning topics to the content of various forms, the most spread being text. We commonly see articles tagged in newspapers by the authors as a form of organizing knowledge and to make the content easier to be discovered by the audience that wants it the most. Moreover, it can be used to analyze a vast amount of text data, like a stream of articles from internet blogs (where each blog uses different tags or doesn’t use them at all) or like social posts.
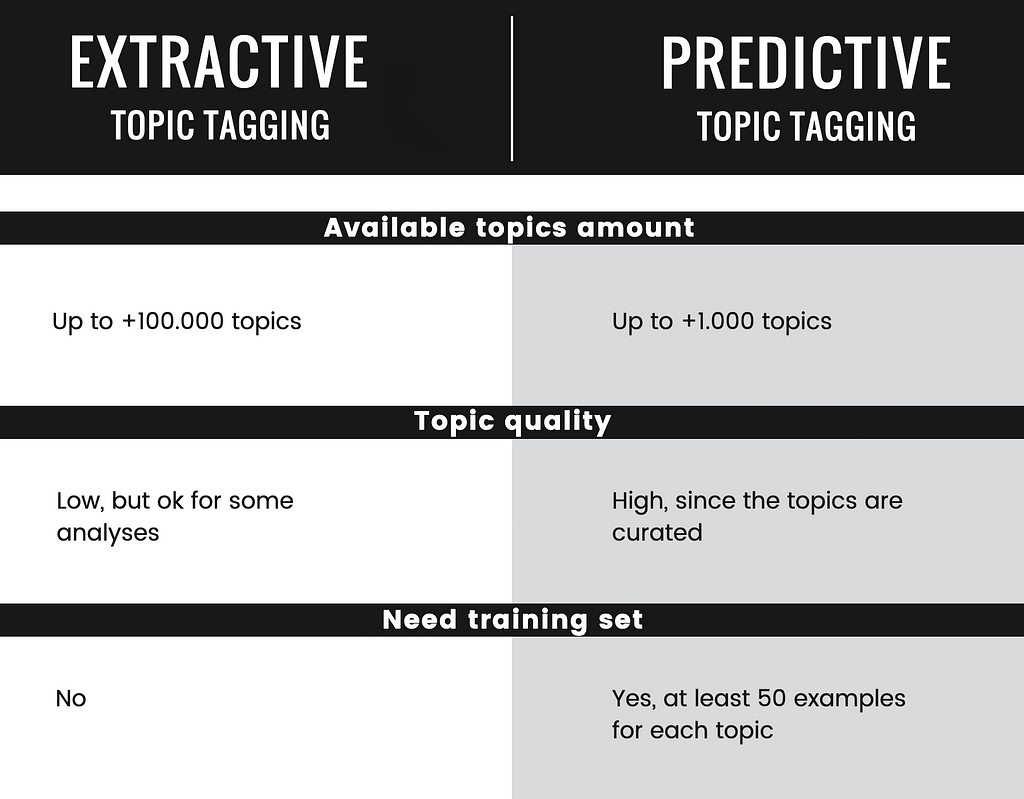
Extractive vs Predictive Topic Tagging
We can distinguish between two types of topic tagging. Let’s consider the following text as an example:
Cryptocurrencies let you buy goods and services, or trade them for profit. Here’s more about what cryptocurrency is, how to buy it and how to protect yourself.
- Extractive Topic Tagging works by detecting the keywords contained in a text and using their normalized forms as topics. Often these topics are enriched using categories from open source knowledge bases like Wiki Data. The topics predicted for the previous examples would be something like Money, Business, Give, Wage, Price, Help, Buyer, Work, Store, Service.
- Predictive Topic Tagging works with a predefined set of topics, by training a classification model with several examples of texts for each topic. The training set can be scraped from the web since each published article with tags is a potential training sample. The topics predicted for the example would be something like Bitcoin, Cryptocurrency, Crypto, Blockchain Technology, Cryptography, Trade, Cybersecurity, Information Security, Security, Safety, Privacy, Blockchain, Economics, Economy.
Here is a brief comparison for extractive and predictive topic tagging, with pros and cons.
Since the goal of this article is to teach how to predict high-quality topics, we’ll focus on how to perform Predictive Topic Tagging. To train a topic tagging model we need training data. For example, articles published online with tags associated with their authors, which ensure that data has good quality. Medium is a good source of such articles, let’s scrape Medium to build a training set. The full code can be found in this Colab.
Scraping Medium to get training data
We’ll need newspaper3k to extract article data from HTML and langdetect to keep only English articles.
The next step is to define a function that scrapes an article from its URL, parses it with newspaper3k to extract its title and text content, and gets the article tags with some heuristics.
Now that we know how to scrape an article from an URL, we need a place to find all the articles with the tags we are interested in. For this purpose, we can scrape the archive pages of Medium which are organized by tag and by date. For example, the archive page for the topic Artificial Intelligence for the date January 15th, 2020 is https://medium.com/tag/artificial-intelligence/archive/2020/01/15. We can generalize the URL structure as https://medium.com/tag/<tag>/archive/<year>/<month>/<day> and generate a list of archive pages with random dates for a specific tag to scrape. To get the actual article URLs from each one of these archive pages we just need to use a working CSS selector.
Let’s define some tags to scrape, we start with these six.
Now we can stick together all the pieces and start collecting 50 articles for each tag. Remember to perform gentle scraping and wait sometime between requests!
Eventually, we save the scraped articles in a Pandas dataframe. It will be useful in the next section to train our machine learning model.
Training the Topic Tagging model
We’ll need Pandas and NumPy for data manipulation, NLTK to normalize text, and Sklearn for the machine learning model.
This is how our dataframe with the scraped data should look like.

The first thing to do is to remove from the scraped articles all the tags that we didn’t scrape for (i.e. we keep only the six tags we defined before as they are the only ones for which we have enough data to train a model) and to apply a MultiLabelBinarizer on the tags to convert them to the supported multilabel format.
To give you an idea, this is an example of how the MultiLabelBinarizer works, taken from the Sklearn documentation.
>>> mlb.fit_transform([{'sci-fi', 'thriller'}, {'comedy'}])
array([[0, 1, 1],
[1, 0, 0]])
>>> list(mlb.classes_)
['comedy', 'sci-fi', 'thriller']
We can now prepare the data for our model. The model will predict the topics from the title and the text of the article, which we concatenate. This text is then cleaned with standard text processing like transforming it to lower case, replacing bad characters, and removing stopwords.
The cleaned text is then transformed by a TfidfVectorizer. In addition to being commonly used in information retrieval, TF-IDF has also been found to be useful in document classification. Utilizing TF-IDF instead of raw token frequencies in a document reduces the impact of tokens that occur very frequently and are therefore empirically less informative than tokens that occur in a small fraction of documents.
Now that we have prepared the training data, we can train our model. Our problem is a multilabel classification problem, that is, we want to label each sample with a subset of all the possible labels. We can do this by training a binary classifier for each topic, exactly what the MultiOutputClassifier does.
We are at the end! Let’s try the model with some mock sentences.


The predicted topics are consistent with the text input. Good job!
Possible improvements
In this tutorial, we got to the point, but there are many aspects that we have overlooked.
- Evaluate the model with suited metrics and train validation-test split the dataset. We should evaluate the precision, recall, and F1-score of the model so that we know if changes to the model are beneficial. Usually, F1-score is used as the metric to optimize in a multilabel classification setting, but you should choose the metric according to the use case of the model. For example, if the model aids humans in assigning categories to articles, the recall may be more important than precision as there is always a person that can fix prediction errors.
- Finetune the classification threshold of each binary classifier. Remember to tweak this parameter on the validation set to optimize your metric.
- Get training data from multiple websites. In this tutorial, we scraped only Medium, but there are many other websites to gather data from.
- Better training data preparation with taxonomies. We data scientists tend to work too much on the model and little on the quality of the data. Our training set is made up of articles and tags assigned by their respective authors, but authors are often limited in the number of tags that can be assigned. This means that the author often has to choose which tags to assign among many plausible ones, according to some logic of visibility of the tags and their specificity. Consequently, our training set is dirty because there are plausible tags that are not assigned to the articles! To work around this problem, we could build a topic taxonomy and clean up the dataset with it, assigning more generic tags whenever we see more specific tags assigned. For example, if an article has the tag Machine Learning, we can deduce that it talks about Artificial Intelligence too, as Artificial Intelligence is a hyperonym of Machine Learning.
Use case examples of Topic Tagging
In these other articles, I scraped the blog section of famous companies' websites and applied topic tagging to analyze what are the companies writing about.
- Fast Content Marketing Analysis with NLP: GitHub vs GitLab
- Fast Content Marketing Analysis with NLP: Pocket vs Evernote
Conclusion
Predictive Topic Tagging is a solution to predict high-quality topics to articles and it’s rather easy to train a model with decent quality. However, in my experience, the actions proposed in the possible improvements section dramatically improved the quality of the final model. Possible use cases are derived from the automatic analysis of a large number of texts, such as social media analysis or competitor analysis.
Thank you for taking the time to read this article. Make sure to clap this post if you enjoyed it and want to see more!

Stay up to date with the latest stories about applied Natural Language Processing and join the NLPlanet community on LinkedIn, Twitter, Facebook, and Telegram.
How to train a Topic Tagging model to assign high-quality topics to articles was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")