


")
Exploratory Data Analysis Expounded With FIFA 2021(Part 1)
Last Updated on January 6, 2023 by Editorial Team
Author(s): Gift Ojeabulu
Learn how to carry out statistical analysis and generate insights like a pro with python using FIFA 21 as a case study.
A short story of why I decided to write about this topic.
Here comes a guy who was curious about learning data science. He searched through the internet and got some resources to learn data science through Udemy, Coursera, YouTube, etc.
Through tutorials, he worked with a clean and small dataset and he was so excited he knew a lot about data science but solving real-world problems; he discovered that data science is a different ball game with an undefined format just like that of Sheffield vs Bayern Munich if you are familiar with football; you know how hard that game would be for Sheffield, Lol.
He noticed Real-life datasets are messy, so it left him in turmoil and he had imposter syndrome. In the long run, He later discovered he needs to handle missing values, ask smart questions and so on, he later discovers it’s not just about doing analysis.
He discovered EDA was not well-explained, especially at the beginner level as expected in a well-aligned form in most tutorials, maybe because it does not have a specific pattern or some other reasons; He had to learn it the hard way through lots of resources, practices and solving real-world problems, which is why he simplified exploratory data analysis. Here I will give some important tips with code explanation using the FIFA 2021 dataset.
I have no special talents. I am only passionately curious — Albert Einstein.
passionately curious in this context means we continue to learn and become very curious as data practitioners which is why we seek to explore data to get meaningful information, while playing FIFA 2021, I was curious to have detailed answers to questions like:
- Who are the top fastest players in FIFA 2021?
- Which Players are paid most?
- Who are the Top tallest players?
- Who are the Top strongest players?
- Who are the best players with Long passes?
- Who are the best players with short passes?
- Who are the best defenders?
Note: All this we will discover through exploratory data analysis in this tutorial.
What you will learn in this article:
- What is Exploratory Data Analysis?
- Why Exploratory Data Analysis?
- Renaming Columns & Checking for missing values
- Working with Datetime feature
- Feature Creation
- Dropping Missing Values
- Descriptive Statistical Analysis
- Basic Data Analysis with Pandas nlargest to get insight
Link to Jupyter Notebook for the post here.
What is Exploratory Data Analysis?
(EDA) is an approach to analyzing data sets to summarize their main characteristics, often with visual methods. A statistical model can be used or not, but primarily EDA is for seeing what the data can tell us beyond the formal modelling or hypothesis testing task. (source: Wikipedia)
Exploratory data analysis is an attitude, a state of flexibility, a willingness to look for those things that we believe are not there, as well as the things we believe might be there — John Tukey
Exploratory Data Analysis from my perspective, in a simple term, is a way of investigating, inspecting and transforming data to derive useful information for rational decision making through statistical techniques and data visualization.
Why Exploratory Data Analysis?
“The main purpose of EDA is to help look at data before making any assumptions. It can help identify obvious errors, as well as better understand patterns within the data, detect outliers or anomalous events, find interesting relations among the variables”. (source: Ibm.com)
I like Exploratory Data Analysis because it helps me ask data smart questions, better explore and perform data visualization on datasets to identify patterns and unveil valuable insights useful for the subsequent steps in the data science life-cycle.
It discloses me to thinking reflectively beyond intuition and analytically, which works with critical thinking skills such as analysis, explanation, problem-solving, and decision making.
Preparing our Datasets
On starting any data science project, understanding the data is very important. We cannot perform effective analysis on any data if you have little or no knowledge of the dataset.
So I will advise trying to have substantial knowledge of your data. In this article, I collated a detailed variable description of our data to understand our dataset before diving into exploratory data analysis.
Now that we understand exploratory data analysis, let’s go straight into the practical aspect of this article. We will use the FIFA 2021 dataset, which we got from Kaggle.
The description of the dataset and the notebook is provided in the GitHub repo. you will have a folder of the dataset and the notebook. I advise opening the notebook and following along with the article for better understanding. I try to make the notebook simple, well commented, detailed and organized.
Link to Detailed variable description here

- We importPandas,matplotlib numpy ,seabornfor basic data manipulation, numerical computation and visualization.
- We silence warnings using the filterwarnings module.
- Word Cloud is used for representing text data in different sizes from the most mentioned to the least mentioned words.
- We import Word Cloud to visualize our text data according to each word size-frequency generated and Counter to hold the count of each element present in the container, finally, we read our CSV dataset and view it with .sample() function for us to get a random overview of our dataset.
From this, we can deduce that the FIFA dataset contains three types of features (Numerical, Categorical and Date features).
With this in the back of our minds, let’s do some basic data cleaning and feature creation.
Note: The aim of using these techniques is to perform the task in this article. I meant you to choose methods base on choice or as your use case requires.
Renaming Columns & Checking for Missing Values
#Viewing the columns available in our Dataset
data_fifa.columns
#Checking for columns with missing values
data_fifa.columns[data_fifa.isnull().any()]

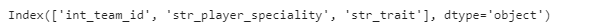
- We use the .columns from Pandas to show the columns in our dataset, we could deduce that we are dealing with a dataset with a lot of columns.
- We use the .columns[data_fifa.Isnull().any()] to check for the list of columns in our dataset with missing values where Isnull() is used for detecting missing values for an array-like object and we discovered that there are three columns with missing values, so we should think of ways to handle this column with missing values either through dropping columns, filling them or any other techniques because the missing value is an attribute of a dirty data.
- Real-life data have common mistakes such as spelling or punctuation errors, incorrect data associated with a field, incomplete or outdated data, or even data that has been duplicated in the database. All this can negatively affect our dataset, which can affect our analysis whereby handling and treating these issues in the dataset is crucial.
- In this part, we are renaming our column name to a shorter and well descriptive name, a good practice for Data scientists, where we adopt the Camel case Naming convention.
Working with Date feature
The DateTimesupplies classes to work with date and time. These classes provide several functions to deal with dates, times and time intervals. Date and DateTime object in Python, so when you manipulate them, you manipulate objects and not string or timestamps.
- We are simply transforming the object column to the object column and then we are using the DateTime properties to transform the column into year and month with .dt.year and .dt.month respectively.
- Time series analysis is a statistical technique that involves the time-series type of data or the analysis of trends. Time series data means data is in a series of particular periods or intervals.… Cross-sectional data: Data of one or more variables, collected at the same point in time.
Feature Creation
Feature creation simply means generating extra features from pre-existing data to create a more accurate machine learning model.
#Subtract 2021 from Date Of Birth to get Age
today = pd.to_datetime('2021-03-10')
data_fifa['age'] = today.year - data_fifa['D.O.B'].dt.year
- Here, we subtracted the date year from the current year 2021 to get a new column called the age.
- After getting the year — the need to create a feature called ‘PlayersAge’ is needed. To this, we will subtract today’s date from the year of the player e.g 2021–03–1972 to get the player’s age.
Dropping Missing Values
There are different ways of handling missing values but we will adopt the drop column method with other datasets the case might be different like filling columns with different techniques and so on, but in this context, we decide to drop inconsistent data columns like the positions and overall columns, and other columns or no or less importance.
columns = ['int_team_id', 'str_player_speciality','str_trait','int_player_id','D.O.B','year','Positions','OverallRating']
data_fifa = data_fifa.drop(columns, axis=1, inplace=False )
data_fifa.sample(4).T
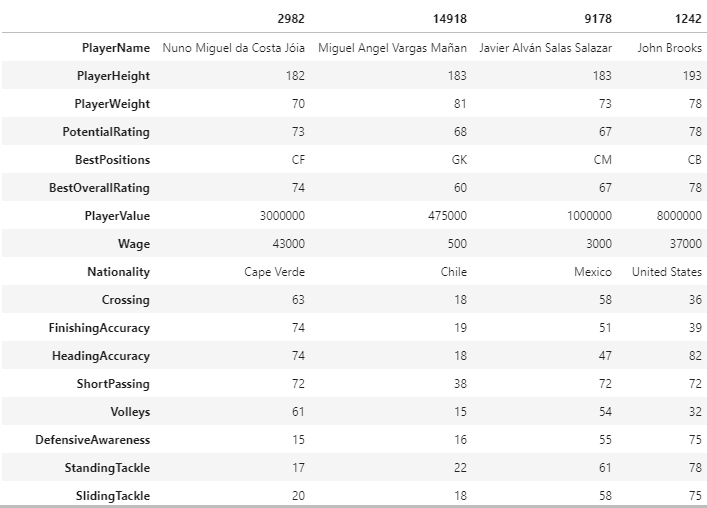
- We dropped the int_team_id, duplicated columns and our date column since we have already converted to an object and created an additional feature from them.
data_fifa.shape

we use the shape method to check the dataset’s shape in rows and columns, where we have 19002 rows and 51 columns.
data_fifa.info()

- The info() summarizes our dataset, we can use this place of the .datatype function because it provides information about the datatype, non-null values and memory usage.
data_fifa.describe().apply(lambda s: s.apply(lambda x: format(x,
'f')))
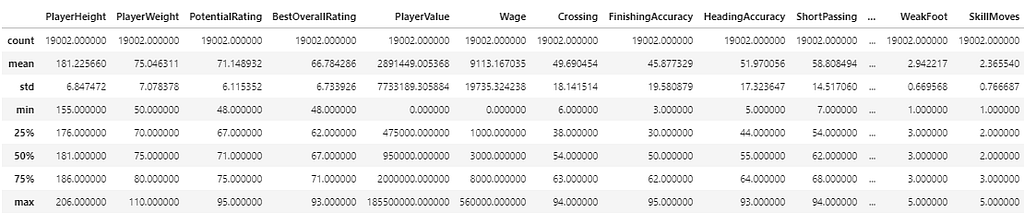
- The .describe()a detailed statistical understanding of the dataset, to view all columns including categorical columns, try the .describe(include=’all’) which introduces the top and frequency value for the object data type.it shows the measures of central tendency — mean and median and the measures of dispersion — Standard deviation, Interquartile range, max and min.
- The .apply(lambda s: s.apply(lambda x: format(x, ‘f’) is used to remove the exponential in the mean and standard deviation to make it more defined.
data_fifa.nunique()
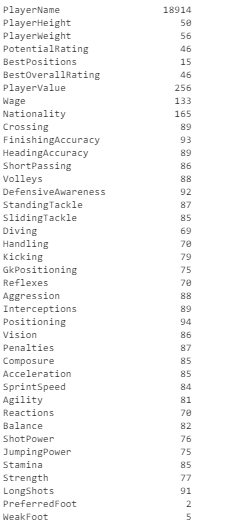
- The unique() function prints the number of unique elements in each column, it is similar but different from the pandas value_counts() which print out the count of unique values in series.
Basic Data Analysis with Pandas nlargest
We stated earlier that Pandas in Python is used for data manipulation, we will use the nlargest method to get insight from our data. Pandas nlargest() is used to get n largest values from a data frame or a series.
Note: In this section, we will give answers to several questions we are skeptical about as regards FIFA 21.
Top fastest players
We will answer the question of whom are the top 10 fastest players in FIFA 2021?
player_name = data_fifa[["Acceleration","PlayerName","BestPositions",’age’,’Nationality’,’SprintSpeed’]].nlargest(7, [’Acceleration’]).set_index(’PlayerName’)
player_name

- We got to understand the top 7 fastest players in FIFA 2021 alongside their age and nationality and we discovered that Adaome Traore is the fastest player in FIFA 2021 with an acceleration of 97 while others among the top 7 are 96.
- Acceleration is a player attribute in FIFA that determines the increment of a player’s running speed (sprint speed) on the pitch. The acceleration rate tells how quickly a player can reach the apex of their sprint speed.
- Therefore, we choose acceleration over speed to determine the fastest player, so an in-depth understanding of each feature in a dataset is very important.
The Tallest players
player_name =
data_fifa[["PlayerHeight","PlayerName","PlayerWeight","BestPositions",’age’,’Nationality’]].nlargest(10, [’PlayerHeight’]).set_index(’PlayerName’)
player_name

- We will be answering the top 10 tallest players in FIFA 2021. The measured Height in this dataset in centimetre where the top 10 tallest footballers are between 206–201cm which when converted to ft that is within the range of 6.76–6.6ft but there is something obvious here which is 8 out of 10 footballers are goalkeepers, so we can say height has an enormous advantage to be a goalkeeper.
The Strongest players
player_name = data_fifa[["Strength","PlayerName","PlayerHeight","Stamina",’age’,’Nationality’,’PlayerWeight’,’BestPositions’]].nlargest(7, [’Strength’]).set_index(’PlayerName’)
player_name

- The strongest player is Adebayo Akinfewa with an overall rating of 97.
- strength is the quality or degree of being strong while stamina is the energy and strength for continuing to do something over a long period this is why we chose strength for measuring the strongest player.
Best Defender by Defensive awareness/ability
player_name = data_fifa[["DefensiveAwareness","PlayerName","BestPositions",'age','Nationality']].nlargest(10, ['DefensiveAwareness']).set_index('PlayerName')
player_name
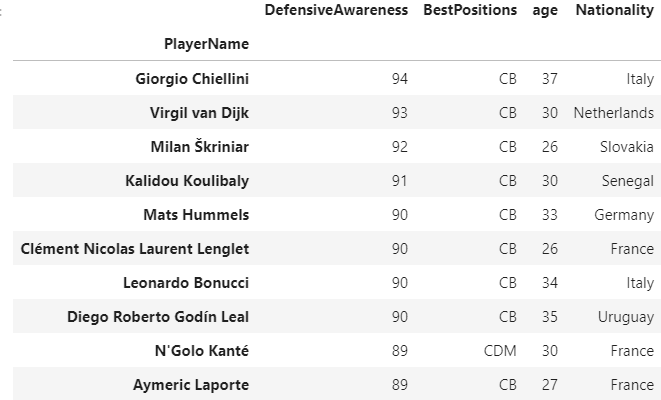
- Georgio Chilleinni of nationality and Virgil van Dirk of nationality are the best defenders with the defending ability of 94 and 93 respectively.
- You might wonder why I choose not to make it best defender but Best Defender by awareness.it is biased to rate best defenders by defensive awareness only because other factors contribute to being the best defender even as much as the defensive ability has a stronger correlation, other factors considered for rating best defender include speed, strength, and heading capability.
Best player with Long passes
player_name = data_fifa[["LongPassing","PlayerName","ShortPassing","Stamina",’age’,’Nationality’,’PlayerWeight’,’BestPositions’]].nlargest(10, [’LongPassing’]).set_index(’PlayerName’)
player_name

- Good passing ability is the most important attribute of a Midfielder. The best player with long passes in FIFA 2021 is Kevin De Bruyne and Toni Kroos with an Overall Rating of 93.
- Lionel Messi and Paul Pogba with an overall rating of 91. We just got an insight into the top 10 overall players with Long passes.
Best player with Short passes
player_name = data_fifa[["ShortPassing","PlayerName","LongPassing","Stamina",'age','Nationality','PlayerWeight','BestPositions']].nlargest(10, ['ShortPassing']).set_index('PlayerName')
player_name

- We have Kevin De Bruyne like 94 and Toni Kroos as 93 overall ratings. we could say De Bruyne and Toni Kroos are the top players with passes in FIFA 21.
Since passing ability is the most considered factor for choosing the best midfielder. In an ideal case, You cannot only measure the top 10 midfielders with passing ability because there are many other factors to consider when choosing the best midfielder and some midfielders ratings are the same.
Most paid players
player_name = data_fifa[["Wage","PlayerName","PlayerValue","BestOverallRating",’age’,’Nationality’,’PotentialRating’,’InternationalReputations’]].nlargest(10, [’Wage’]).set_index(’PlayerName’)
player_name

- Messi and De Bruyne are the most paid players in FIFA 21 with 56000$ and 37000$.
And we draw into conclusion here…
We cannot overemphasize the importance of exploratory data analysis in the Data analytics stage. Understanding it in-depth will give you an edge over other data practitioners.
We just got some insights into things we know and don’t know in FIFA 2021 through exploratory data analysis.
You just learned basic data cleaning and feature creation, descriptive statistics that include dispersion and central tendency measures, data analysis with pandas n largest.
This has been a long post, but I hope you’ve learned a lot and will use the techniques explored here in your next project.
Congratulations! You now have a detailed understanding of FIFA 2021 through exploratory data analysis.
In the next part of this tutorial series, we will ask more questions, use data visualization to answer these questions, and get more insights. How fun is that!? I’m sure you’re looking forward to it.
What else are you curious to know about FIFA 2021?
Kindly use the comment section below. I’ll see you soon, happy analysis!
Connect with me on Linkedin
Connect with me on Twitter
Exploratory Data Analysis Expounded With FIFA 2021(Part 1) was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")