



Deep Learning: Forecasting of Confirmed Covid-19 Positive Cases Using LSTM
Last Updated on January 6, 2023 by Editorial Team
Last Updated on August 15, 2022 by Editorial Team
Author(s): Dede Kurniawan
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Describing each step in the deep learning method for forecasting positive cases of Covid-19 in Indonesia
Introduction
Almost all parts of the world have been shocked by the Covid-19 outbreak that has infected many people; even millions of people have died in this outbreak. The first case of Covid-19 was detected in Wuhan City, Hubei Province, China, in December 2019. On January 30, 2020, it was declared a health emergency for the whole world by the World Health Organization (WHO). Covid-19 spreads quickly because it can be transmitted directly through the air within a radius of 2 meters and in direct contact or when an infected person sneezes or coughs [3].
The Covid-19 pandemic has significantly impacted people’s lives in various fields such as economy, health, education, etc. Some examples of policies implemented by the Indonesian government are wearing masks when in public places, social restrictions on a microscale, Social distancing (2 meters), online learning, working from home, closing various places that invite crowds, etc. [2]. However, not all policies implemented by the Indonesian government effectively prevent the transmission of Covid-19. Having a reliable early warning method is very important to estimate how much this disease will affect the community, on this basis, it is hoped that the government can implement the right policies in dealing with the Covid-19 pandemic.
How do we find a suitable early warning method in dealing with Covid-19? With machine learning or deep learning, we can estimate/predict/forecast the number of cases infected with the Covid-19 virus. After we know how big the estimated cases of being infected with the Covid-19 virus are, we can make a policy to deal with this pandemic by considering the data.
You can access the Google Colaboratory that we use here
Task
We will analyze Covid-19 data in Indonesia and create a deep learning model to forecast the number of cases infected with Covid-19. Our processes include data cleaning and pre-processing, exploratory data analysis, modeling, and drawing conclusions.
We use the dataset on the https://tiny.cc/Datacovidjakarta
Import library
Since we are using the python programming language, there are several libraries that we will use in this article. The first thing we have to do is import all the required libraries.
We imported Numpy to perform computation. Pandas for data manipulation purposes. Matplotlib, Seaborn, and Plotly for data visualization. Scikit-learn for algorithms that are useful in data preprocessing, machine learning, etc. TensorFlow is used to build neural networks.
Data cleaning and pre-processing
Before preparing or cleaning the data, we must load the dataset into a data frame using pandas. To do so, we can use the pd.read_excel() function.
We also display the first five rows of our dataset using .head().

Just in case our data set gets corrupted during data cleaning, we use .copy() method to duplicate our dataset.
df = data.copy()
Well, here maybe there are some column names that cannot be understood because they use Bahasa, so we will rename the column names using English. Also, here we will only focus on analyzing the columns ['Positif (Indonesia)', 'Sembuh (Indonesia)', Meninggal (Indonesia)']. Therefore, we will drop columns that are not used.
To see information from the dataset, we can use df.info().
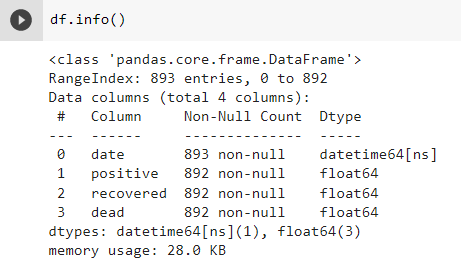
The dataset we use has 893 rows and 4 columns. In the date column, there is a datetime64 data type, and the other column has a float64 data type. However, the problem lies in the date column, which has more rows than the other 3 columns therefore we can assume that in 3 columns other than the date column, there are missing values.
In the code df.dropna(inplace=True), we drop the column with missing values. Then, in the code df.drop(index=0, inplace=True), we drop the first line because it has an inconsistent time difference compared to the lines below. Next, we reset the index on our dataset df.reset_index(drop=True, inplace=True).
The next thing we are going to do is check if there are any duplications and missing values in the data, if there are, we should drop them.
If it turns out that there is no duplication in our data, then our data cleaning process will end here. Next, we will go to the exploratory data analysis process, but before that, we will look at our data frame info once again to make sure our data cleaning process is completely complete.
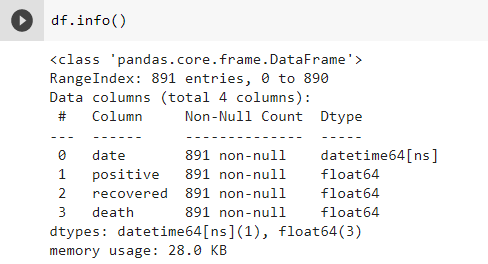
Finally, we should present an overview of our dataset once again.
Exploratory data analysis
At this stage, we will explore our dataset and try to understand more about it. We want to know a summary of the descriptive statistics of the dataset, to do that, we can use .describe() and .transpose() to convert rows into columns.
df.describe().transpose()

Next, we want to know the comparison of the total number of positive confirmed cases, the number of death cases, and the number of recovered cases. To do this, we can visualize the data so that it is easier to understand.
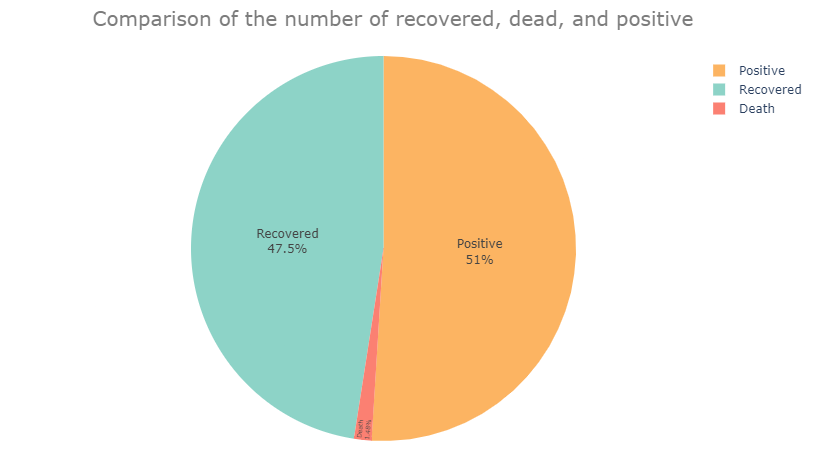
According to the pie graph above, we can take insight that the comparison of recovered cases and positive cases are almost equal. This shows a high recovery rate due to being infected with the Covid-19 virus, but the spread rate is also high. Then, it can be seen that death cases have a small area when compared to cases of recovery and death, this shows a high survival rate due to the Covid-19 virus.
Then, we also want to see the history of Covid-19 cases from some time ago using a line chart.
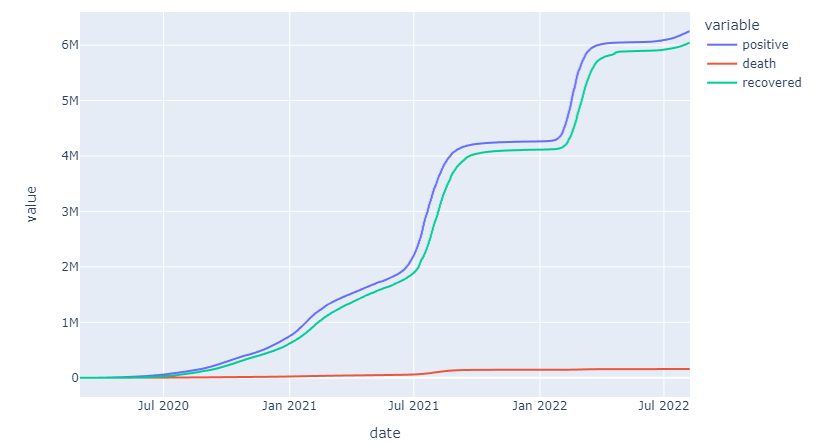
According to the line chart above, We can see that positive cases are occasionally rising quickly, but the recovery rate from Covid-19 is also quite high, and the number of deaths from Covid-19 is very small compared to the very high rate of spread.
Exploring the correlation between the data will be our final step in the exploratory data analysis process.
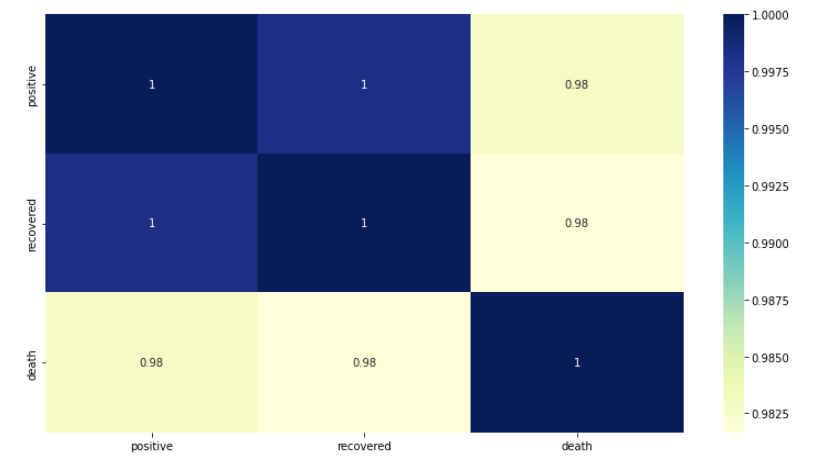
Here, we calculate the correlation between data using the Pearson correlation method, which is a measure of the linear correlation between two variables. All of these data have a high positive correlation with each other. We can understand that if one variable value increases, the other variable value will also increase. Just like if positive cases go up, the recovery rate will also go up.
Modeling
What we have to do before creating a deep learning model is to prepare preprocessed data first. Since we are focusing on the positive column, we will drop the other columns.
Here, we also change the data type to int64 and convert the data frame to a one-dimensional NumPy array. Then, the data must have been scaled.
Here we are scaling the data using the MinMaxScaler method present in Scikit-learn. We also only apply scaling to 80% of the total dataset, to be precise, we only scale the data used for the model training process.

We next create a function that is used to separate the dataset into training data and test data. We separate with a composition of 80% for training data and 20% for test data.
Next, we design a neural network architecture to be used in time series data prediction (forecasting).

We design a neural network model using Conv1d, LSTM, and dropout layers. LSTM neurons are very effective when used in time series data. here we also add a dropout layer as a regularization. The total parameters in our model are 99.521.
After finishing constructing the neural network architecture, we have to define the matrix for the loss function as well as the optimizer. We choose Mean Square error as the loss function and optimizer Adam (Adaptive Moment Estimation). We chose Adam based on consideration because it is adaptive and requires less learning rate hyperparameter adjustment.
model.compile(loss= 'mse', optimizer= 'adam')
The next step we will take is to train our model with the data that has been prepared.
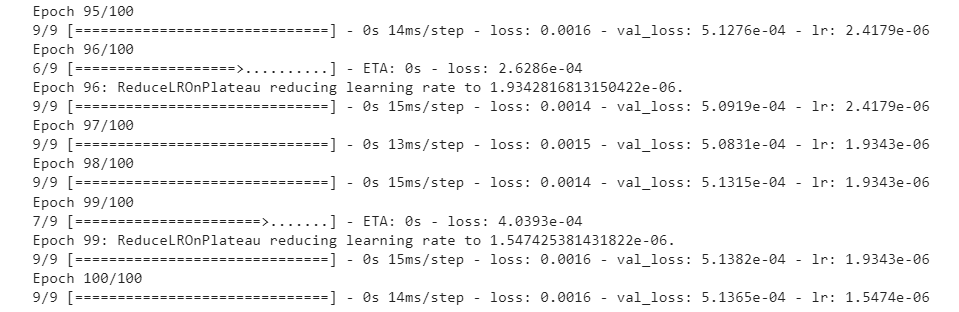
When conducting the model training process, we also determine the learning rate and perform early stopping. We chose the ReduceLROnPlateau algorithm for the learning rate because the learning rate can be adaptive according to the matrix (the learning rate will decrease when the matrix is not growing).
After we finish training the model, we will evaluate the performance of the model we have trained.
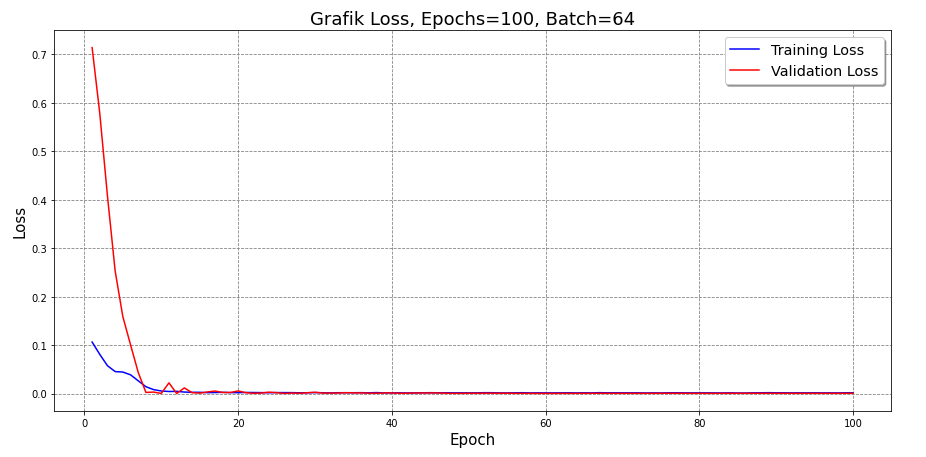
To make it easier for us to evaluate the model, we visualize the training loss and validation loss using a line chart. It can be seen from the graph that the error in the test data decreases as the number of epochs increases.
We will also compare the actual value as well as the predicted value of the model. To make it easier to observe, we will also visualize it.
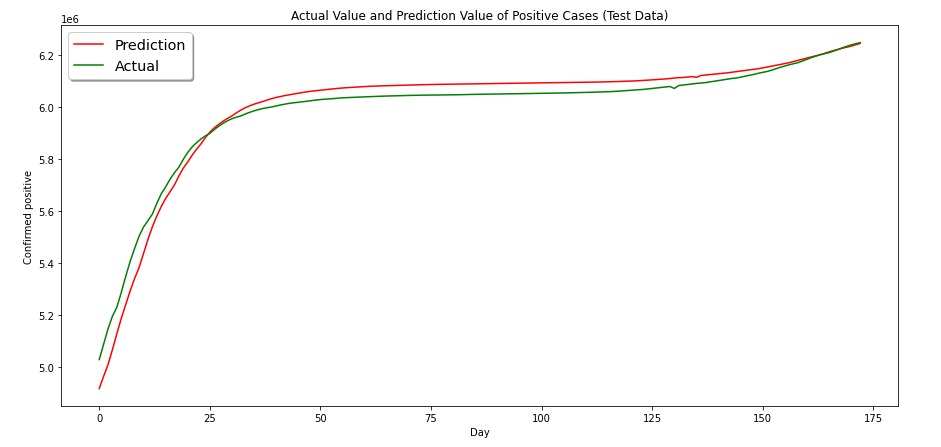
It can be seen that the model predicts a value that is close to the actual value. We then assume that our model performs reasonably well.
Next, we prepare the data that we will use to make predictions (forecast).
Next, we will plot the entirety of the data and compare it with the predicted results from the model. Actually, it’s pretty much the same as above, but here includes all of our data.
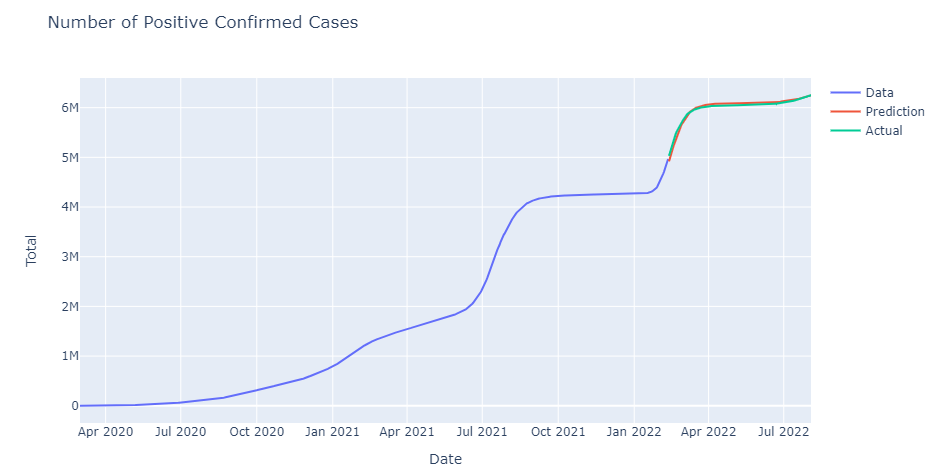
In the line chart, it can be seen that the predictions of the model are almost equal to the actual values.
Now we will predict Covid-19 cases for the next 30 days.
Finally, we visualize the predicted data. This also makes it easier for us to analyze and understand the data.
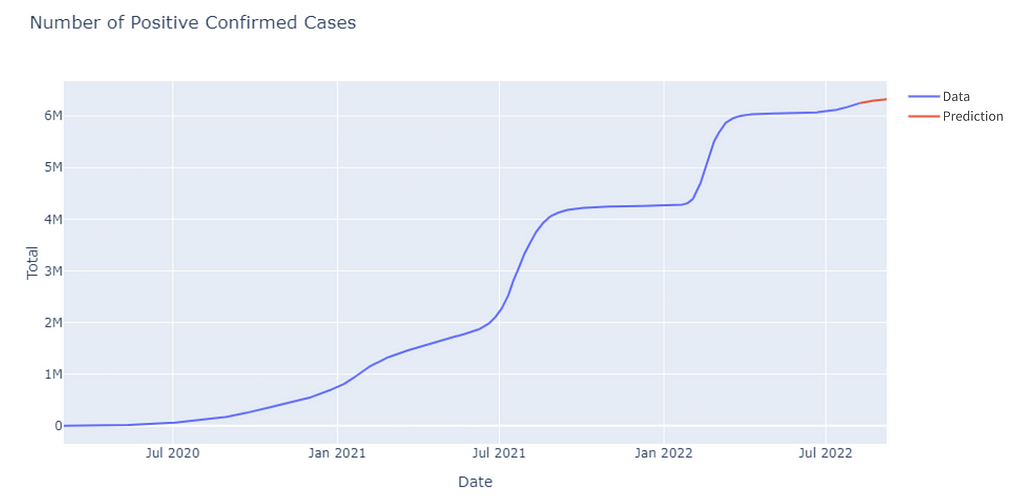
We make predictions for the next 30 days using the model we have designed and trained. After that, we did a visualization using a line chart to see the prediction results. It can be seen that for the next 30 days, our model predicts that Covid-19 cases in Indonesia will continue to increase.
Summary
Covid-19 is a pandemic that is still happening today. Wise decision-making is based on existing data, and by using the data, we can predict future events. Based on the process we have done, we understand that the Covid-19 pandemic in Indonesia is not too bad. This is based on comparing positive, recovered, and death cases.
We focus on positive cases and build deep learning models to predict future cases. As a result, we predict that positive cases of Covid-19 in the next 30 days will continue to increase. However, it is also based on uncertainty, and our model also does not 100% predict the true outcome. Based on that we will also make our decisions according to future conditions.
References:
[1] Kurniawan, A., & Kurniawan, F. (2021). Time Series Forecasting for the Spread of Covid-19 in Indonesia Using Curve Fitting. 2021 3rd East Indonesia Conference on Computer and Information Technology (EIConCIT). https://doi.org/10.1109/eiconcit
[2] Géron, A. (2019). Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow, 2nd Edition (2nd ed.). O’Reilly Media.
[3] Painuli, D., Mishra, D., Bhardwaj, S., & Aggarwal, M. (2021). Forecast and prediction of COVID-19 using machine learning. Data Science For COVID-19, 381–397. https://doi.org/10.1016/b978-0-12-824536-1.00027-7
[4] Setiati, Siti & Azwar, Muhammad. (2020). COVID-19 and Indonesia. Acta medica Indonesiana. 52. 84–89.
Deep Learning: Forecasting of Confirmed Covid-19 Positive Cases Using LSTM was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

