



Data Science Guidebook 2021
Last Updated on January 6, 2023 by Editorial Team
Last Updated on September 12, 2021 by Editorial Team
Author(s): Tim Cvetko
Careers
Things to keep an eye out for during your DS Problem
The world’s sexiest job of the 21st century may be appealing but it also comes with a lot of challenges. No worries. This is your lucky day!!!
I present to you a modern end-to-end data science guidebook. Hopefully, after reading this article you’ll be able to spark that little lightbulb at the back of your head every time you face a challenge in the AI world.
Understanding the Problem
As researchers, programmers, and ‘smart creatives’ we get carried away by the outcome and the hype of artificial intelligence and its capabilities. We want to get results and we want them fast.
Sit down, breathe, take a piece of paper and a pen and start sketching.
Brainstorm, if necessary. Make a plan. I want you to embrace the mentality of thinking 3 steps ahead. Before the attractive code [ML] begins, I want you to think about :
1 -> what tools you will use for your data pipelines,
2 -> is there going to be an overhead in data (lightbulb should go off: Python generators, Spark pipelines)
3 -> what data format will I use, how is this compatible with the one I need for training?
4 -> does my problem really acquire an ML solution?
Always think of an easier [non ML] solution.
I guarantee you: As you find for one, you’ll find insights that you wouldn’t have otherwise. You’ll see your problem from a different perspective. Even if your solution does require an ML solution, you’ll benefit tremendously.
Why getting to know the problem is mainline of the project?
- You can’t understand the data if you don’t understand the problem
- You should have a narrative throughout the process and you should aim to get as close to finding the solution.
- Your actions are otherwise aimless. Remember, the algorithms revolve around problems, not the other way around. You shouldn’t look at an algorithm and imagine or even force it to solve a task. For example: solving the shortest path problem should spark that lightbulb: “Dijkstra”.
The Next Step is choosing an Approach
Once long enough in the ML world, you’ll be able to envision a solution prior to receiving the data. Even though it sounds great, it isn’t.
Here’s why: the reason why you’re so good at what you do, is because you’re able to think beyond the scopes of your knowledge. As a modern data scientist, your job is to come up with clever solutions to modern-day problems. We might as well turn our focus to AutoML if that would not be the case.
Remember the motto from before: Problem First, Algorithm, and Solution later? Add this: “More times than not it’s easier to delegate your tasks. “
Break your problem apart. See the big picture.
At this point, I want you to dig deep into your expertise in algorithms and mathematic techniques. Think like an end-to-end developer from the beginning. Anticipate the unpredictable. Assuming you understand the type of data you’re dealing with and the type of problem you’re trying to solve. It’s rarely a one-type algorithm kinda work.
While researching, think about where each algorithm might go wrong. If you’re dealing with neural networks, I want you to think about gradients, choosing the right optimizer, what effect the regularization might have, etc. You have to be that under-the-hood guy, not TensorFlow.
hands-on learning is the best kind of learning
For example:
- Stochastic Gradient Descent has a nosier convergence than Adam.
- One advantage of using sparse categorical cross-entropy is it saves time in memory as well as computation because it uses a single integer for a class, rather than a whole vector. These are the kind of lightbulbs I was talking about.

Note: once data is manageable, is when the magic begins. At that stage, you can of course try many different approaches, do hyperparameter tuning, and so forth.
Understanding Your Data -> EDA
EDA stands for exploratory data analysis and is probably the most vital part of your DS project’s journey. No real-world project relies on pure data. You’re going to spend a lot of time on data fetching and manipulation.
“Everyone wants to do the model work, not the data work”: Data Cascades in High-Stakes AI — Google Research
The project revolves around your aim. Seek for hidden meanings in data, their correspondence. Don’t underestimate the power of data visualization. As programmers, we get quite arrogant about data visualization because it suggests we don’t understand our data. Don’t let that ego undertake you.
Go deep. Find every insight possible.
Feature engineering is the process of using domain knowledge to extract features from raw data via data mining techniques. These features can be used to improve the performance of machine learning algorithms.
At this point, I want to show you a bag of tricks useful for selecting features:
- feature cross -> the most famous example of a feature cross is the longitude-latitude problem. These two values could be but lonely floating values in the dataset. If you choose to pursue the importance of location, the end goal is to determine what regions have the highest correspondence to the output. Crossing combinations of features can provide predictive abilities beyond what those features can provide individually.
Feature Crosses | Machine Learning Crash Course | Google Developers
Another possibility for the location is to define clusters of data points and pass their label to the model.
- dealing with missing values (NaN)-> this is always an obnoxious problem, right? First step: — find insights for the columns with missing data and feature cross them out of the equation. Second: Perhaps, it shares a high correlation with another column and then you can use padding. Find more here:
Padding and Working with Null or Missing Values
Let me give you advice they don’t teach at school, guys. If the desired column matches none of the previous requirements and you find that it has a low correlation to the output, drop it.
- data normalization ->simply put, this is the process of scaling your data while still representing what it should represent. Why would you do that? Firstly, it helps with outliers. Secondly, while it doesn’t fix the exploding gradients problem, it outlasts it. Thirdly, provides a more unique distribution than before.
- dealing with outliers->outliers are unlikely elements of the dataset which are way out of the desired limits.
How to Remove Outliers for Machine Learning – Machine Learning Mastery
Good news: You get to pick what is an outlier to your data and what you’re going to do about them.
Model Interpretation
You’ve reached the final steps of your project. Yet, this is perhaps the one that cements you as a data scientist. “He who tells the story”, right?
Coming this far, you feel no doubt you’ll push your model to the limit of its possibilities. We’re all thinking about it by now, so I’ll just say it: “Hyperparameter tuning”.
I’ve gone into much detail about it in the following article, so go ahead.
Keynote: “Don’t reinvent the wheel. There’s no need. The goal is to provide the best hyperparameters for your model. “
In addition, I would like to add something referred also to as the Pandas vs Caviar method. It’s a matter of babysitting a model and waiting for its results or diverting into multiple models and choosing the best one.
Caviar > Pandas. Always.
Every project has its own interpretation of metrics. In order to be successful, you must think beyond the scopes of general compliance. Ask yourself this:
What criteria would make this project/model successful?
What point could you say you’re satisfied with your model performance at?
You know your model best, so again, these are just a few tricks:
- plot accuracy/loss percentiles ( these indicate how faulty your model is on the test set, i.e how off are your predictions)
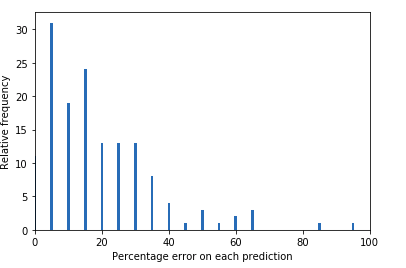
- track loss and accuracy ( use early stopping callback, regularization, or TensorBoard for logging)
- find out hidden connections between data that are mispredicted, so you can fix why it is so
Finally, think of the customer/business interactions. What are the applications of your model?
Get in the shoes of a person you’re trying to sell your AI power force to and think of the struggles they might have. Such preparation will be noted, trust me.
Conclusion
Here you go. This was my all-out step-by-step guidebook to Data Science. I encourage you to take this list before you start a new project and think ahead. If I could sum up, my greatest piece of suggestion to you, that would be: Get to know what you’re dealing with. Data really is the centerpiece of your project. The model can only be as good as your data. Be prepared and the results will not disappoint.
Embrace the mindset of a modern data scientist. And remember, when in a seemingly hopeless position, we’ve all been there. My motto is if it doesn’t take at least 100 bugs during the coding, what’s the point?
Connect and read more
Feel free to contact me via any social media. I’d be happy to get your feedback, acknowledgment, or critic.
LinkedIn, Medium, GitHub, Gmail
I have just recently started writing my own newsletter and I would really appreciate it if you checked it out.
Link: https://winning-pioneer-3527.ck.page/4ffcbd7ad7.
- Deploying a Neural Style Transfer App on Streamlit
- How GANs Are Capable of Creating Such High-Resolution Images
- Kubernetes vs. Docker Explained
Data Science Guidebook 2021 was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

