


")
An AI Practitioner’s Guide to the Kdrama Start-Up (Part 3)
Last Updated on July 24, 2023 by Editorial Team
Author(s): Jd Dantes
Originally published on Towards AI.
Artificial Intelligence
From life as an AI engineer to moral dilemmas.
Note: Possible spoilers ahead, you may want to go back to this post after you’ve watched the series.
In the previous posts, we’ve covered a bit about the technical AI details that the Kdrama Start-Up got right. In the first post we talked about neural network and image fundamentals (including training loss and gradient descent), while in the second post we dived into generative adversarial networks (GANs) and how they work.
In this third and last part of the series, we’ll continue by going through the other aspects that they got right when you’re working in AI, such as…
#3 Your face is a toilet!
Early on, we see the Samsan guys demonstrate their “world-class” technology to Dosan’s father. They were trying to show that their technology works and could detect and classify people and other objects. Well, for the most part it did, except when the camera was pointed to the father and classified him as a toilet.

While this was a funny moment in the series, the fact is that this is pretty close to real life! Both the technology, and how it can classify people as toilets. To see just how close, look at this video:
YOLOv3 is one of the popular neural networks for object detection. Guy who made it is pretty interesting, naming it “You Only Look Once”, as the network directly gives the detection boxes and classifications at once, compared to earlier approaches which had separate stages for region proposal and subsequent classification. He also has a TED talk where he demonstrates it live and explains how it works. He also has a resume with little ponies.
Pretty cool right? If you look closer though, you may observe that it’s not perfect. For instance, in the demo video, for a moment the detection flickers and classifies the dog in the middle as a teddy bear.

Why does this happen?
Recall the discussion in Part 1 on how the neural network takes an image, multiplies and adds things together, and when the result is 0, you have a cat, while a 1 would be a dog? Let’s tweak that a little bit. In the case of YOLO, instead of having a single sum, what you have is an array or list of numbers. The first could be the score for a cat, the second for a dog, and so on, and you get the one with the highest score. These scores are also clamped to have fractional values between 0 and 1, and could be interpreted as probabilities. These scores could flicker and oscillate a bit per frame in the video. If you’ve watched the TED talk, you can see these scores being displayed:


These scores and predictions are per image, so if you’ll observe in the TED talk, they’ll actually flicker a lot, from frame to frame.
Now going back to the picture where the dog was misclassified, the detection in the middle likely had high scores for “dog” generally, but it just happened that for that specific frame, the score for “teddy bear” overtook that of the dog’s. That’s just the way it is. Even we humans misidentify things sometimes, right? Especially if they have similar features.

How might we remedy this? One approach is to have more and better images for training, similar to when we were younger and learning what things were called. Another is to play around empirically with the score threshold. So, we only say that there’s a dog if the score is above some threshold, for example if it’s above 0.9, or 90%. I mentioned empirically as in practice, this would be influenced by things like your training data, camera height, angle, lighting, and the context of your specific application. For high-security face authentication, you might want the threshold to be something like 99.9%. On the other hand if you wanted real-time alerts for blacklisted criminals, then the threshold for that would likely be lower; there could be false alerts, but it’d be better to err on the side of caution and then double check the alert, rather than failing to catch a target because you were too careful of misclassifications.
In Start-Up, during the scene where Dalmi and team were undergoing the test for their self-driving cars, they mentioned the concept of “ghosts”. I think that they weren’t referring to paranormal existences, but instead were talking about random misdetections like what we have just talked about, or possibly reflections on surfaces as mentioned in this paper.

In the scene, their self-driving car abruptly stopped — fortunately because there was an actual cat on the road, and not a ghost detection. In the real world, such random and corner cases must be accounted for. A kid may suddenly follow a ball rolling to the road, ignorant of any cars.
There are also various levels of autonomy (and corresponding tests that must be passed), with some requiring only occasional intervention from the driver, while of course the Holy Grail would be a fully autonomous vehicle which you can sleep in as it ferries you to your destination.

There may also be moral dilemmas. Let’s say that an accident occurs, and the car would be heading towards many unsuspecting pedestrians — should the car just prioritize them over the passenger as there are more pedestrians? But would you still ride in such a car that was programmed that way?
Additionally, with manually driven cars, in such an emergency the driver’s reaction would just be a reflex — instinctive, and not predetermined as would be the case for an engineer programming a self-driving car. This and other scenarios are discussed in more detail in this TED-Ed video.

So to summarize, in the development of self-driving cars, there are moral concerns and government regulations that must be addressed. These are hurdles that must be resolved, on top of the already challenging engineering research to reach the best accuracy possible.
Now speaking of obtaining the highest accuracy, let’s switch gears a little and pivot to talking a bit about such metrics…
#4. We got 99.99% accuracy!!!
Antibacterial soaps usually make this claim. They can kill 99.9% of bacteria or something along those lines. For artificial intelligence though, rather than directly entice, such statements may cause practitioners to take a second look at the details of the technology.

During the hackathon presentations in Episode 5, Dalmi was pitching that their technology was able to reach 99.8%. While I’m not saying that this can’t be done, it’s just that for people working with and modeling data, there’s something known as overfitting.
Let’s go back to the graphs of the twins before while they were training their model.
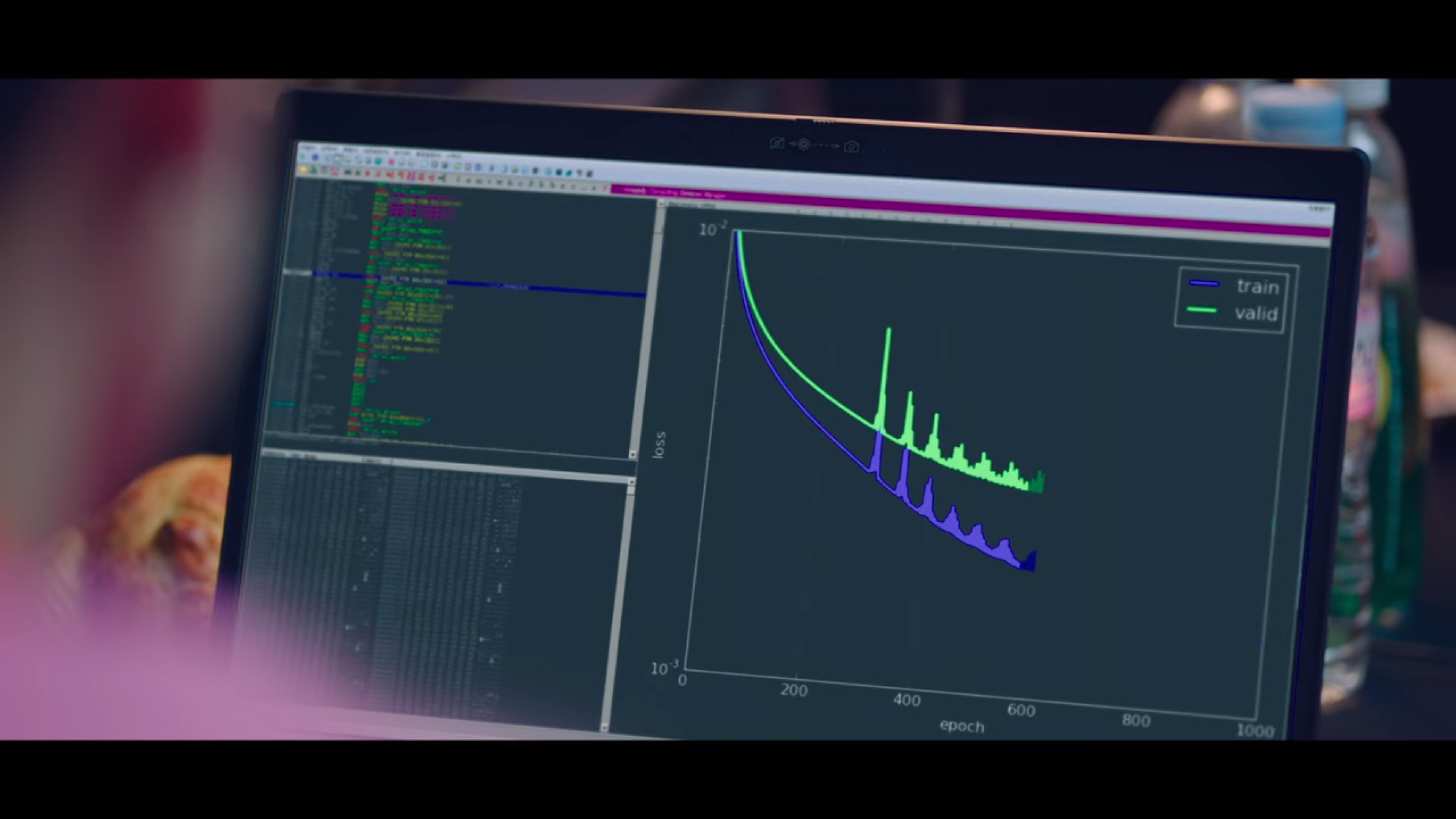
Wondered why there are two graphs? If you look closer, you’ll see that one is labelled train while the other is labeled valid. This is because generally, your dataset is split into two, the training and the validation (or simply “test”, but they could be differentiated) sets. So during training, you let your model see the images from the training set and have it learn and adjust the neural network weights (remember gradient descent?). You evaluate the performance on the test set, but do NOT use those images to update the weights. Why do we do this?
Let’s look at the graphs below. On the left, you have a model that is underfitted. The model did not learn enough, and if you give it a random data point for prediction, chances are that the error will be high.
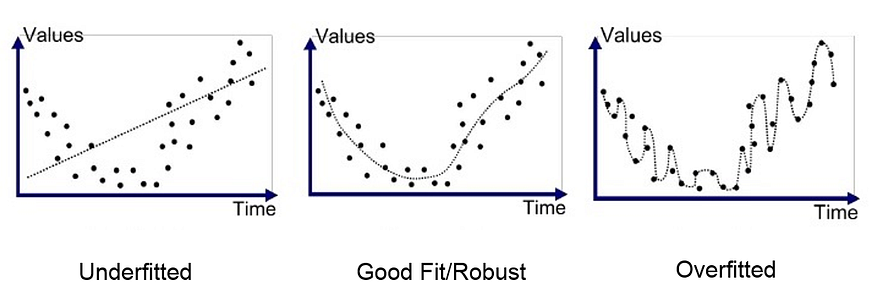
The next graph is adequately fitted, and it catches the overall trend of the data. Here, the curve is pretty near (though not exactly passing through) the data points, the loss is low enough and you probably have good accuracy with this model.
However, you shouldn’t overdo it. In the third graph we can see what overfitting looks like. The graph snakes through the data points exactly, and here loss would be really low. The downside is that by looking too much at the data, it becomes too biased to what it has seen so far and loses its ability to generalize. For instance, towards the right of the graph, the curve’s trend is going downwards, but if you compare the trend on a macro level, the whole thing actually should trend upwards as seen with the adequately fitted and robust graph.
Here’s an analogy. Let’s say you had a private plane and you were hiring a pilot for it. The pilot did well on exams, but the catch is that the pilot knew the exam questions beforehand as they were very similar to the questions he saw while studying. Would you feel safe and bet that the pilot can do well in real-world scenarios? Or would you rather have a pilot who took the exams, encountered questions that weren’t seen before, yet did well anyway? If your answer is the latter, it’s the same thing with the neural networks.
So for neural networks, generally you wouldn’t really be using the same images for training and for evaluating its performance, as that would be creating bias. You may also want to check that you’re not training for too long, as there may come a point where training loss still goes down, but upon evaluation on the test set find that the accuracy actually worsens.
Again, it’s not impossible for someone like the Samsan Tech team to come up with very high accuracy, but it should be checked that they did their set up right and that the model is actually robust and generalizes well. In practice there are also standard datasets for benchmarking a model’s accuracy; for object detection prominent ones are the COCO and the PASCAL VOC datasets. As reference, when YOLOv3 was published, it had a mean average precision (or mAP for short, you can read more about this object detection metric here) of 55.3% on the COCO dataset. Since then, other variants and neural networks have been developed to increase this accuracy.
Another thing to mention is that aside from benchmarks on standard datasets, in practice there are other things to consider when deploying a real-time computer vision application. These include physical factors like the height and angle of the camera, the lighting in the room, and tradeoffs with accuracy to balance things like speed, budget for hardware, and associated risk and consequences in the case of mispredictions.
At this point, we’ve covered a lot about AI, both technical and non-technical. There’s one last thing about AI that’s also talked about a lot, and which Start-Up also touched on, to my surprise. And that is…
#5. The issue of job displacement
Towards the latter part of the series, Injae presents her team’s AI tech which utilizes CCTVs to automatically detect and prevent crime, scaling way beyond what humans can monitor.

Not only will the solution improve the safety of citizens, but from an operational and business point of view, it saves costs as well. By a lot.

Of course, these same cost savings would be at the cost of the displaced laborers.


As someone who works in AI, I’ve come across this topic a lot. There are also already numerous articles, studies, and analyses about this. Personally, I think that this is not just one question, but rather can be split into two separate and distinct concerns: the first is innovation, while the other would be the job transition itself.
As for innovation, I think that the answer is generally to go towards the better technology. Injae actually mentions this:



If we were to stifle technology, then we wouldn’t have cars today, but would still use horses just so horse-related jobs could remain.
And it’s not just about us either. Injae makes the point that such choices will have an impact on future generations as well.

Now, an observation is that these days, we don’t have as many horse-related jobs for transporting people around, but we do have taxi drivers, and even platforms where that role has been democratized in a gig economy. And this applies even to the digital industry. When personal computers came about, jobs related to editing and re-typing documents were affected, but there were also 15.8 million net new jobs as a result, accounting to 10 percent of employment (page 40 in this McKinsey report).
So jobs may be displaced, but many more could also be created.
For AI, one big transition could be about data annotation. As we already know, for neural networks to work well, they need lots of good quality images, and those must be labelled depending on the computer vision task. For some, only the category of the image may suffice, but for others, it may involve drawing bounding boxes around the objects, marking body parts (“keypoints”), or even segmenting the objects per pixel. Labelled training data is so important to the industry that there are even companies doing just that, and were able to reach unicorn status (i.e., be valued at over a billion dollars)!
For me, another opportunity that I think may happen is that if manual tasks could be automated and done more efficiently, time would be freed up so that people could learn new things and upskill themselves. They’d be able to contribute and do more meaningful and other impactful things for society.
This topic has many facets to it that we could go on and on about it. For now, I’m just pleased at how Start-Up approached this topic.
“If everyone in this world were like you and my son, this world would quickly become an innovative place.”


“But it’s never good to move too fast. That speed can hurt many people. We’ll see a lot of people lose their job, unable to adapt to the changes. We need people like me to slow things down a little.”


“…To help find the right pace that allows people to adjust and live.” — Nam Sunghwan
So yes, we should strive for innovation and making the world a better place, but at the same time, we should also consider the pace at which we do so and be conscious of how our changes impact others in the present.
Whew, that took a while! If you made it here, congratulations! Hopefully you’ve learned a bit about AI, both the technical details as well as the non-technical considerations relating to society.
If all these have piqued your interest to learn more, then here are some resources.
Learn Programming
If you haven’t learned programming, this is fundamental. Python is my personal recommendation — it’s designed to be clean and easy to learn, and is used in different areas (machine learning, computer networks and security, web development).
- Look for sites like codeacademy.com. This one’s interactive and you can code in the browser itself, so it’s good to start with. I haven’t used this in a while, but I think this and other sites should be good.
- Reddit is pretty helpful. Look for subs like /r/learnpython, /r/learnprogramming, /r/computerscience. Go through their wikis/FAQs, and follow related subreddits.
- VisualGo was developed by professors at the National University of Singapore, and contains interactive visualizations for standard data structures and algorithms.
- Learn about Big O notation. Cheatsheet.
- I’ve compiled more resources here, including articles on some topics and general programming exercises. These cover beginner concepts like loops and arrays, but also include more advanced (and interesting!) topics like dynamic programming and max flow networks.
- There’s a part there labeled “competitive programming”. If you’re not familiar, this refers to algorithmic type contests where you solve computer science/math problems, not the hackathon type where you build and pitch an app or website in 24 hours.
- The problems in these contests are similar to the questions in technical interviews, and are probably helpful when applying for software engineering roles in general (i.e., even if you’re not aiming to do machine learning stuff). I plan to write introductory articles on this some time in the future; you can follow this account or leave your email here if you’d like to be updated when that comes out.
Learn some math
I don’t have any particular preferred resource for this, but you’d probably need some fundamentals on statistics, linear algebra, and calculus before learning more about AI. (Or perhaps just dive into AI resources, then learn what you need along the way.)
Resources for learning AI stuff
My recommendation is to first learn about the classic techniques used for modeling data in general, even back when hardware could not really run neural networks.
Not a strict requirement to go through all of these, but I’d recommend learning about:
- image processing techniques (spatial and frequency transforms, RGB/HSV/HSL, filters, edge detectors). These classic and manually designed filters also give insight into what convolutional neural networks (CNNs) automatically accomplish these days.
- logistic and linear regression
- random trees/forest
- Naive Bayes
- support vector machines
- k-nearest neighbors
- k-means clustering
- breadth first search (BFS), depth first search (DFS), A* search
- minimax, alpha-beta pruning
- ensemble learning (e.g. AdaBoost)
- principal component analysis (PCA)
- independent component analysis (ICA)
For neural networks specifically, there are also lots of resources out there, from Medium articles, publications, and blog posts to several online courses. I’d recommend these ones from Stanford:
- CS229. Classic course. This actually covers several of the topics mentioned above.
- CS231n. Convolutional neural networks (CNNs) and computer vision. Notes. YouTube (2017).
There are also sites like:
- https://www.fast.ai/
- http://neuralnetworksanddeeplearning.com/
- https://www.deeplearningbook.org/. Another classic, the book by Goodfellow (creator of GANs) et al. This is pretty dense; I haven’t gone through this book completely, but the graduate courses I took used this as reference.
- Reddit is still helpful. Check /r/LearnMachineLearning and related subs.
The field also changes so fast, that what was taught in one semester may be different from the next, so it’s a good habit to be updated on the latest papers and developments.
I would also suggest that you pick a project or topic that is of interest to you, and then go ahead about learning and trying to build it, whether you fully understand the details or not.
We don’t necessarily understand how a car works, but we know that pressing the pedals and brakes provides us value: getting to our destination. Not everyone needs or wants to understand how a car works to use it, but for those who want to improve it, they can then take the time to open the hood and learn about the engine and its internals.
Happy learning!
If you haven’t read the previous posts, you can start here (Part 1), or go to Part 2 here.
Acknowledgments
Thanks to Lea for her suggestions and reviewing early drafts of this post.
Connect on Twitter, LinkedIn for more frequent, shorter updates, insights, and resources.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

