



4 Things to Know about Large Language Models
Last Updated on July 25, 2023 by Editorial Team
Author(s): Harshit Sharma
Originally published on Towards AI.
Amidst the LLM hype, there are interesting “things” to know about the LLMs, as mentioned in a recent paper by Samuel from Anthropic:
The paper can be found at https://arxiv.org/pdf/2304.00612.pdf
There are 8 things that the paper discusses but the 4 mentioned here are the best ones. Recommend giving a nice quick read for the paper.
Let's get started !!

A perfect testament to this statement is the development of the GPT family of models by OpenAI, starting from GPT, GPT2, and GPT3.
The thing to note here is that the design of these 3 models hardly differs at all. It's the infrastructural innovations in high-performance computing rather than model-design that made the later versions of the GPT family possible and better in terms of performance.

The scaling laws have been immensely helpful in precisely predicting the potential gains in the performance of larger LLMs without actually training the LLMs and burning millions of $.
For example, scaling laws allowed the creators of GPT-4 to cheaply and accurately predict a measure of its performance consuming just 0.1% of the resources needed by the final model.
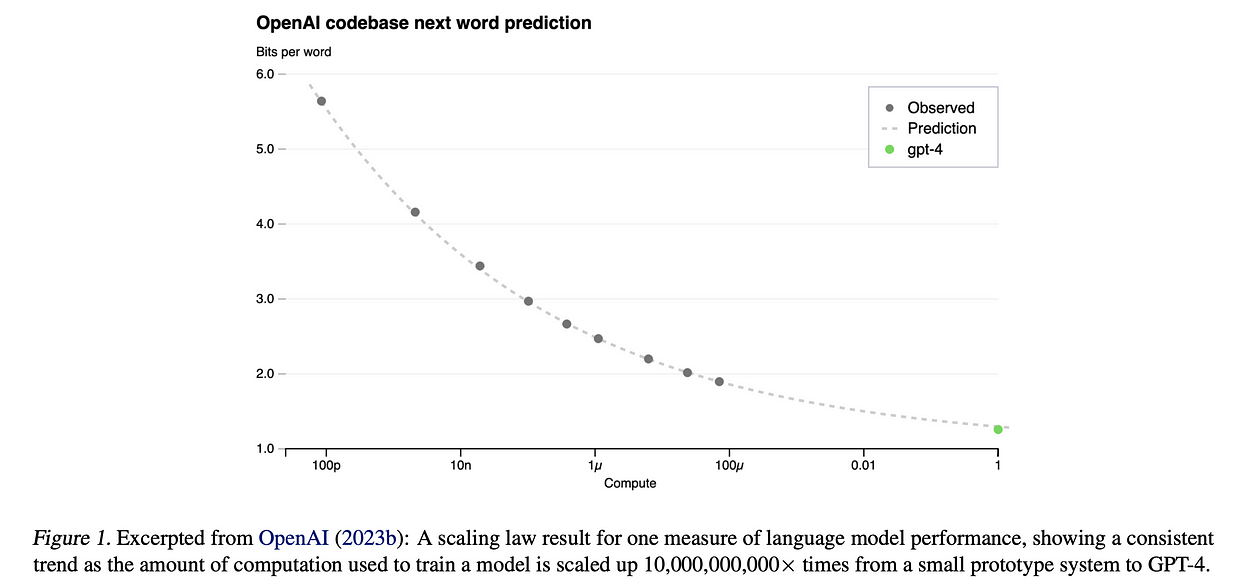

Scaling laws as discussed above can only be useful in predicting the “pretraining test loss”, but not the specific tasks or skills that the model will be good at. Developers can get confident that the model will be better, but only god knows what actually.
This means, scaling law-style predictions are not unreliable when it comes to predicting the skills the trained model will possess.
So,
When a lab invests in developing a new LLM, they are essentially buying a “mystery box”
Once again taking GPT as an example. GPT-3 is the first modern LLM to show
- few-shot learning and
- chain-of-thought reasoning capabilities
Fun fact — its few shot capabilities were not known until it was trained and its capacity for chain-of-thought reasoning was discovered only several months later once it was available to the public.

LLMs are created primarily to imitate human writing, but it has been obvious that these models can easily outperform humans on many tasks.
This is because:
- LLMs are exposed to far more material than any human sees in his entire lifetime.
- They are given additional training using Reinforcement Learning, enabling them to produce responses that humans find helpful without requiring humans to give behaviors demonstrations explicitly


Increasingly capable models can recognize the circumstances that they were trained in, causing them to behave precisely in those situations, but rather unexpectedly in new circumstances. This problem surfaces in the form of :
- Sycophancy: where a model answers subjective questions in a way that flatters its user’s stated beliefs
- Sandbagging: where a model endorses even misconceptions when their user seems less educated. Creepy !!
Microsoft Bing Chat suffering from this problem displayed manipulative behavior in its early versions.
Here is what 36% of the 480 researchers said in one of the surveys:

Hope you enjoyed this quick read !!
Follow Intuitive Shorts (a Substack newsletter), to read quick and intuitive summaries of ML/NLP/DS concepts.

Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

