



Interactive Product Documentation: Creating an Engaging Conversational Q&A Bot with OpenAI and LangChain
Last Updated on July 12, 2023 by Editorial Team
Author(s): Sriram Parthasarathy
Originally published on Towards AI.
5 use cases + prototype to chat with your own in-house product documentation
All of us have undoubtedly used product documentation at least a few times. Just think about how we often feel when searching for information. It’s like searching for a needle in a haystack. You have access to thousands of pages of text and video, and you need to locate the precise information to address a particular issue. It’s easier said than done. The default route most of us take is to search on Google and click on multiple links to read.
But what if users could ask specific questions in a conversational tone and receive precise answers? Questions like, ‘How do I reset my printer?’ and instantly find the precise instructions to do so. In addition, the system could suggest the next set of questions to ask. For example, ‘What are the common troubleshooting steps to try after performing a printer reset?’ This is where the integration of a conversational user interface with a Language Model (LLM) comes into play, empowering users to navigate through documentation in an interactive way.
In this post, we will focus on two parts. First, we’ll explore five unique use cases of how Conversational UI and LLMs can revolutionize the way we interact with product documentation, with practical examples for each. Secondly, we will walk through a quick prototype for building out a chatbot using LangChain and OpenAI for product documentation. Let's start with the Use cases below
A. 5 Use cases for Conversational UI and LLMs to query product documentation
1. Interactive Product Manuals
Can we transform the thousands of pages in a static product manual into integrated guides? Users would simply ask questions to find the information they need.
For instance, let’s consider a user who has just purchased a new DSLR camera and wants to know how to change the aperture. Instead of sifting through a bulky manual, they could ask an LLM-powered chatbot, ‘How do I change the aperture on my new camera?’ The chatbot would search the product manual, comprehend the context, and provide a straightforward, step-by-step guide.
2. Instant Troubleshooting Assistance
When a product or device encounters an error, users tend to aggressively search for troubleshooting information. The time it takes to find this information and resolve the issue directly impacts customer satisfaction. This is where Conversational UI and LLMs can provide instant assistance to users, making the process much smoother.
For instance, let’s consider a user whose printer is not working and displays an error message. They could ask a chatbot, ‘My printer is showing Error Code B200. What does it mean, and how can I fix it?’ The chatbot, utilizing the power of LLM, would interpret the error code from the product documentation and guide the user on resolving the issue.
3. Product Feature Explanation
Gone are the days when users would attempt to read the entire getting started guide. Nowadays, they only seek information about a particular topic when the need arises. For instance, a user might come across a feature in a product they already own and want to learn more about it. This is where Conversational UI can bridge the gap by providing on-demand explanations of specific product features.
For example, let’s imagine a user who is curious about the features of their new smartwatch. They could ask, ‘What can I do with the heart rate monitor on my smartwatch?’ The chatbot would then provide a comprehensive list of capabilities offered by the heart rate monitor, along with explanations of how to use each one
4. Personalized User Onboarding
Conversational UI and LLMs can provide a personalized onboarding experience for new users, helping them understand how to use the product effectively.
For example, let’s say a user has just signed up for project management software. Instead of overwhelming them with all the features at once, a chatbot could guide them step-by-step. The user can ask questions like, “How do I create a new project?” or “How can I assign tasks to my team?” The chatbot would then provide tailored responses based on the product documentation.
5. Comparative Product Analysis
Everyone compares multiple options before buying a product. The way they do that is to pour over the product documentation to find the relevant details and compare and contrast. A chatbot equipped with a Large Language Model can help in this regard.
For example, a customer is debating between two models of a smartphone. They could ask the chatbot, “What’s the difference between the camera capabilities of Phone Model A and Phone Model B?” The chatbot could then analyze the product documentation for both models and provide a comparative analysis.
B. Quick prototype to showcase querying product documentation
To showcase how to query product documentation, I used the product documentation that comes with a camera. This is an example document you could use. Or you can download whatever documentation you would like to try this sample with.
This will be a web-based chatbot where users can ask specific questions about the features of their camera. In this case, I will ask questions from Chapter 2.

I would like to know what setting to enable for cloudy conditions?

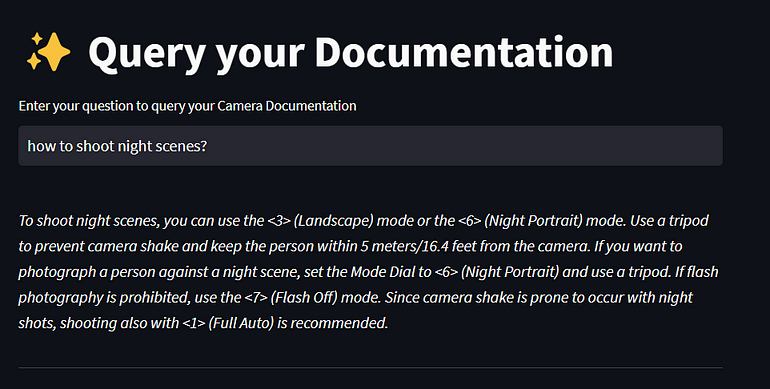
I would like to know what setting to enable for shooting night scenes.
In the next section, I will walk through how this was built.
Initial setup
Install OpenAI, LangChain, and StreamLit
pip install openai
pip install langchain
pip install streamit
Import the relevant packages
# Imports
import os
from langchain.llms import OpenAI
from langchain.document_loaders import TextLoader
from langchain.document_loaders import PyPDFLoader
from langchain.indexes import VectorstoreIndexCreator
import streamlit as st
from streamlit_chat import message
from langchain.chat_models import ChatOpenAI
Set the API keys
# Set API keys and the models to use
API_KEY = "Your OpenAI API Key goes here"
model_id = "gpt-3.5-turbo"
# Add your openai api key for use
os.environ["OPENAI_API_KEY"] = API_KEY
Define the LLM to use
# Define the LLM we plan to use. Here we are going to use ChatGPT 3.5 turbo
llm=ChatOpenAI(model_name = model_id, temperature=0.2)
Ingesting product documentation
We used Langchain to ingest product documentation data. LangChain supports multiple formats, including text, images, PDFs, Word documents, and even data from URLs. In the current example, the pdf loader was utilized to ingest the product documentation, but if you wish to work with a different format, you simply need to refer to the corresponding loader specifically tailored for that format.
# We will use their PDF load to load the PDF document below
loaders = PyPDFLoader('docs/cannondocumentation.pdf')
This document I used has a lot of pages. So I saved this into a vector database. (default is chroma). You can use other vector datastores like Pinecone. The advantage of this is, your content is split into smaller chunks. So when a question is asked, instead of sending all the pages to LLM, we first query the vector database to retrieve the chunks that are relevant to the question and only send those chunks to the LLM to answer the question.

Within the LangChain framework, the VectorstoreIndexCreator class serves as a utility for creating a vector store index. This index stores vector representations of the documents (in chromadb), enabling various text operations, such as finding similar documents based on a specific question.

# Create a vector representation of this document loaded
index = VectorstoreIndexCreator().from_loaders([loaders])
Now we are ready to query these documents.
Setting up the web application
The application is presented in the browser using Streamlit, providing a user-friendly interface.
# Display the page title and the text box for the user to ask the question
st.title('U+2728 Query your Documentation ')
prompt = st.text_input("Enter your question to query your Camera Documentation ")

When a user enters a question, this question is sent to the vector database to query relevant chunks, and this, along with the question is sent to LLM via index.query() method. The response is displayed on the screen.
if prompt:
# stuff chain type sends all the relevant text chunks from the document to LLM
response = index.query(llm=llm, question = prompt, chain_type = 'stuff')
# Write the results from the LLM to the UI
st.write("<br><i>" + response + "</i><hr>", unsafe_allow_html=True )
#st.write("<b>" + prompt + "</b><br><i>" + response + "</i><hr>", unsafe_allow_html=True )
Here is an example of asking questions about night shooting using this chatbot, where the precise answers are from the product documentation.

As you can see, it's a lot easier to query using a conversational UI to get the exact answer you are looking for. And as you saw from the above simple prototype, it's not difficult to build either. If you have tons of documentation in your company, it's a great opportunity to wrap up chatbot UI on top of it to query your documents.
Conclusion
In conclusion, the integration of Conversational UI and Large Language Models brings a host of benefits to the realm of product documentation. By enabling interactive manuals, instant troubleshooting, feature explanations, personalized user onboarding, and comparative analysis, these technologies can significantly enhance user experience and engagement.
The rise of conversational UIs raises a series of intriguing questions. Are we on the verge of seeing traditional, static product documentation being completely replaced by conversational ones? Will information-heavy product documentation be substituted with interactive, conversational interfaces that offer users personalized information in direct response to their inquiries? While it’s too early to confirm these possibilities, the signs certainly suggest a shift in this direction.
As we continue to make strides in AI, these LLM applications are only the beginning, promising an exciting future for user support and product understanding.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

