


 and Reinforcement Learning (RL)")
Neural Architecture Search (NAS) and Reinforcement Learning (RL)
Last Updated on January 4, 2021 by Editorial Team
Author(s): Arjun Ghosh
Deep Learning
Computer vision, and more specifically in classification tasks, are among the most popular deep learning techniques. Convolution Neural Network (CNN) particularly popular in the computer vision field of machine learning. CNN particularity lies in the selective connection of each hidden layer neuron to a subset of neurons in the previous layer. It means that the initial hidden layer can display borders, the second a specific shape, and so forth in classification tasks, up to the final layer that identifies the particular object.
The CNN architecture includes several layer types, including convolution, pooling, and fully connected. Many research efforts in meta-modeling tries to minimize human intervention in designing neural network architectures. The RL (Reinforcement Learning)-based approach by [1] achieved state-of-the-art results on well-known classification benchmarks. The NAS approach boosted the attractiveness of NAS and triggered a series of exciting work on this topic of research. Our survey is mainly motivated by examine the background of architecture search and focus on RL approaches that gained most of the interest these recent years.
The performance of the CNN depends primarily on the model structure, the training process, and the data representation. Several hyperparameters are used to control all these variables and have a significant influence on the learning process. CNN parameters setting is considered as a black box problem because of the unknown nature of CNN architecture. In this context, automatic design solutions are highly required and initiate a large volume of research. The task of CNN hyperparameters tuning has been handled through meta-modeling.
Some papers for Neural Architecture Search (NAS) using Reinforcement Learning (RL):
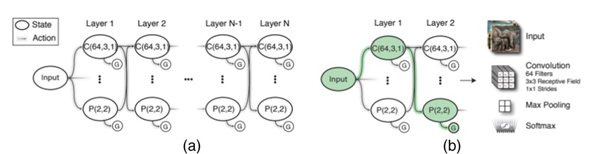
MetaQNN [2]:
This model [2] relies on Q-learning to sequentially select network layers and their parameters among a finite space. Layers compose it, depicted in Figure 1: convolution (C), pooling (P), fully connected (FC), global average pooling, and softmax. MetaQNN was evaluated competitively with similar and different hand-crafted CNN architectures. The agent action space is integrated into the possible layers the agent may move to, given a certain number of limitations (Figure 2).
Neural Architecture Search with Reinforcement Learning [1]:
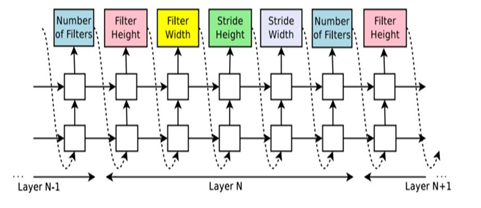
The controller Recurrent Neural Network (RNN) select parameters sequentially for convolution layers of CNN [1]. A softmax classifier predicts each sequence output and is used as the input for the following sequence. Parameters are- height and width of the filter, height, and width of stride, number of filters each layer. The architectural design stops as soon as the number of layers exceeds a predefined value. The accuracy of the built architecture is given as a reward for RL training of the RNN Controller. Competitive results are achieved for CIFAR10 and Penn Treebank data sets (Figure 3).
Efficient Architecture Search (EAS) [3] :
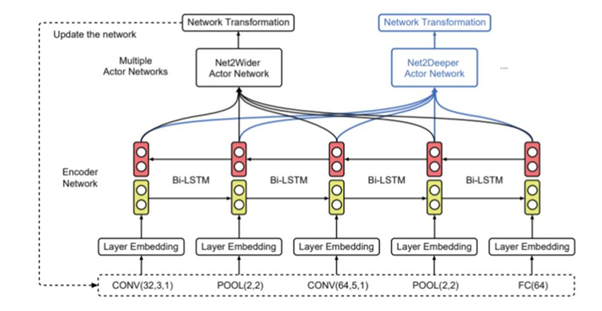
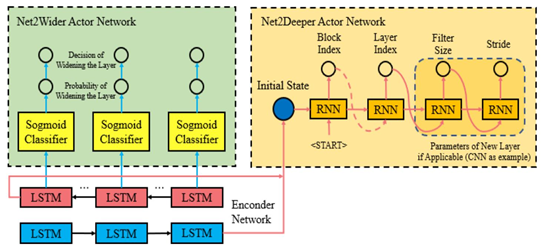
In recent work, Efficient Architecture Search (EAS), [3] implement techniques that allow reusing pre-existing models. Action encompasses network transformation activities like adding, expanding, and deleting layers. The EAS solution is focused on the idea of deeper student networking, inspired by Net2Net technology. As shown in Figure 4, an encoder network implemented with the bidirectional recurrent neural network [4] feeds actors to network with given architectures. The action network of Net2Wider shares the same sigmoid classifier and decides whether the layer is widened according to each encoder's hidden state. The Action Network in Net2Deeper inputs the final Bi-LSTM hidden layer into the recurrent network, and the recurring network decides where to insert the layer and corresponding parameters of the inserted layer. EAS offers similar state-of-the-art models, either manually or automatically, which provide comparatively smaller computational resources.
BlockQNN [5]:
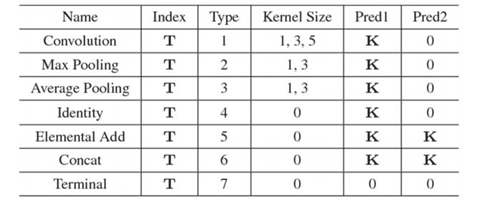
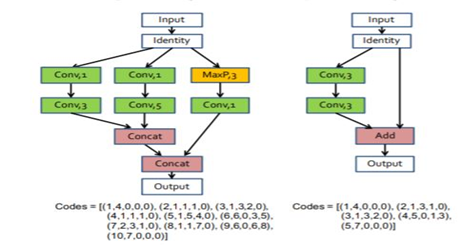
Most of the recent work on neural architecture search is based on more complex modular (multi-branch) structures. These multi-branch components are then repetitively stacked to create a deep architecture through skip connections. “Block-wise” architecture decreases search space significantly by speeding the search process. BlockQNN is one of the first approaches to implementing block-wise architecture [5]. It automatically builds convolutional networks using the Q-Learning reinforcement technique. Block architecture is close to existing networks, like ResNet and Inception (GoogLeNet). The block search space is detailed in Figure 5 and consists of five parameters. This parameter is composed of five layers: indexes (situated in blocks), operation type (commonly selected from seven types), kernel sizes, and 2 layer indexes of predecessor layers. The entire network is constructed based on specified blocks by sequentially stacking n times. Figure 6 depicts two different samples of blocks, one with a multi-branch structure and the second showing a skip connection.
Progressive Neural Architecture Search (PNAS) [6]:
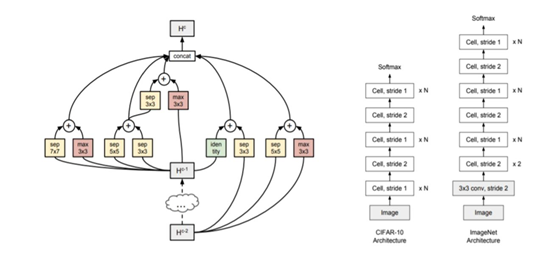
Progressive Neural Architecture Search (PNAS) [6] proposes to explore the space of modular structures starting from simple models then evolving to more complex ones. Under this method, the modular structure is called a cell and comprises a set number of blocks. In this approach, the modular structure is called a cell and contains a fixed number of blocks. Each block consists of two operators among eight selected operators. In order to create the resulting CNN, the cell structure is first learned then it is stacked N times. The main contribution of PNAS lies in the search process optimization by avoiding direct search in the entire space of cells. With a cell size maximum of 5 blocks and K equivalent to 256, PNAS is up to 5 times faster. The performance prediction takes much less time than the full training of designed cells. The best cell architecture is shown in Figure 7.
The success of current RL approaches in the NAS field is widely proven. However, this is achieved through the costs of high computational resources. For this reason, the current state of the art is preventing individual researchers and small research entities (companies and laboratories) from full access to this innovative technology.
Follow the author Arjun Ghosh here.
References:
[1] B. Zoph, Q.V. Le, Neural Architecture Search with reinforcement learning, Proceedings of the International Conference on Learning Representations (ICLR), 2017.
[2] B. Baker, O. Gupta, N. Naik, R. Raskar, Designing neural network architectures using reinforcement learning, Proceedings of the International Conference on Learning Representations (ICLR), 2017.
[3] Cai H., Chen T., Zhang W., Yu Y., & Wang J., Efficient architecture search by network transformation, In Thirty-Second AAAI conference on artificial intelligence, 2018.
[4] M. Schuster, K. Paliwal, Bidirectional recurrent neural networks, Trans. Sig. Proc. 45 (11) 2673–2681, 1997.
[5] Z. Zhong, J. Yan, W. Wu, J. Shao, C.-L. Liu, Practical block-wise neural network architecture generation, The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
[6] Liu C, Zoph B, Neumann M, Shlens J, Hua W, Li LJ, Fei-Fei L, Yuille A, Huang J, Murphy K, “Progressive Neural Architecture Search,” In: European Conference on computer vision, 2018.
Neural Architecture Search (NAS) and Reinforcement Learning (RL) was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts



")
Recent Posts




")

