



Image Classification with Ensemble of Deep Neural Networks using TensorFlow + TPUs
Last Updated on January 7, 2023 by Editorial Team
Author(s): Sanku Vishnu Darshan
Deep Learning
Detection of Foliar Diseases in Apple Trees with Ensemble of Deep Neural Networks.
Hello everyone, I welcome you to the practical Series in Deep Learning with TensorFlow and Keras. I think most of us have gone through situations where it takes ages to train a state-of-the-art deep learning model with a humongous quantity of images. Here comes the favorite step of image classification for most of the readers out there. Can you guess it?. Yes, the very famous technique which helps to avoid model over-fitting is Image Augmentation. With image augmentation, the number of images gets doubled, tripled, or even quadrupled or more over augmentations, which even leads to an egregious amount of training time. This article will help you understand how to perform multi-label image classification using TPUs. With all of that said, let's dive right in and get learning.
What is a TPU?
A tensor processing unit (TPU) is an AI accelerator application-specific integrated circuit (ASIC) developed by Google specifically for neural network machine learning, particularly using Google’s own TensorFlow software.[1]
CPU vs. GPU vs. TPU
CPU:
- Named central processing unit, CPU performs arithmetic operations at lightning speeds.
- Low Latency, thereby faster calculations.
- Low throughput.
GPU:
- Named Graphical Processing Unit, GPUs are well known for the parallel processing architecture.
- High Latency i.e., somewhat slower calculation speed when compared with CPU.
- High throughput.
TPU:
- Tensor Processing Units are developed by Google, especially for Machine Learning purposes.
So, now let’s go deep and find out the process going under the hood and figure out the way calculations are being done.
Example: Consider you want to multiply two tensors, supposing [1,2,3] and [4,5,6]. First, when you use CPU, it performs (1*4), (2*5), (3*6) sequentially, whereas if you use GPU it performs calculations in a parallel manner i.e., all the three multiplications perform simultaneously without the need to wait and go sequentially.
Now, I’m gonna ask you a question, which processing unit takes less time i.e, is CPU faster or GPU?. Yes, CPU performs faster than GPU cause it has low latency whereas GPU has high latency. Then you may ask a question “Hey, GPUs are faster than CPU right?”. Absolutely yes, suppose CPU performs in 2ns and if we multiply 3((1*4), (2*5), (3*6)) with 2ns then total time is 6ns on the other hand GPU performs all the three multiplications in 4ns.
Here comes TPUs, developed by Google meant to be used with TensorFlow have high processing power than (GPU + CPU). TPU v3 has 420 teraflops means it can perform 420 trillion floating-point operations at a time.
Suppose, we are dealing with image datasets containing high-resolution images and if we feed it into some state-of-art models like EfficientNetB7 (well known for its numerous parameters and depth), using a GPU enabled machine increases the training time significantly when compared with TPUs. TPU is designed for AI purposes and can perform complex matrix calculations within no time.
Dataset
We’ll be using the Kaggle Plant Pathology Competition dataset. It contains pictures of Apple trees affected by four unique types of foliar diseases, and the task is to classify and identify the Foliar Disease in Apple Trees; more information can be found on Kaggle.
Let’s get started!
This article is the walkthrough of my Kernel Submission for the Plant Pathology Competition. I’d suggest you make use of Kaggle Kernels or Google Colab as they provide free TPUs. 😃
Initial Setup
Import the necessary libraries….
TPU Setup
Make sure if you have TPU enabled machine. If you are using Google Colab, check the setting of your notebook and enable TPU or if you are using Kaggle Notebooks check for TPU under the accelerator window.
Consider it as boilerplate code for configuring TPU so that your model makes use of them. The TPUClusterResolver() checks for the TPU environment and applies the distribution strategy. The distributed training strategy is just like a method that makes the model make use of the high computational power of TPUs.

The get_gcs_path() gets the path of the dataset located in the parent/working directory.
Reading the Dataset

The train, test (CSV) files provided by the Kaggle contains the images of leaves under the image_id column. We’ll make use of the lambda function and append (. jpg) so that the model can read the images.
Loading and Augmentation of Data
As we are dealing with TPUs the input data should be loaded using tf.data.Dataset. Once you load the data in tf.data.Dataset, the API offers a ton of functionalities that we can use for training a neural network.
Finally, we’ll map the dataset to decode_image() function which will load and decode the file into actual data. The data_augment() function reads each and every image and performs augmentations, here we’ll flip the images both horizontally and vertically, thereby reducing the problem of overfitting and increasing the variance of data.
Learning Rate Scheduler
The deep learning model adjusts the weights associated with its features so that the loss is minimized. During the process of the model training, gradient loss is being calculated this gradient loss get’s multiplied by the learning rate. At last, the weights of the neural networks are updated and replaced by the difference between old weight and product of learning rate and gradient loss. The learning rate is considered as hyperparameters so that we can tweak and tune the model performance.
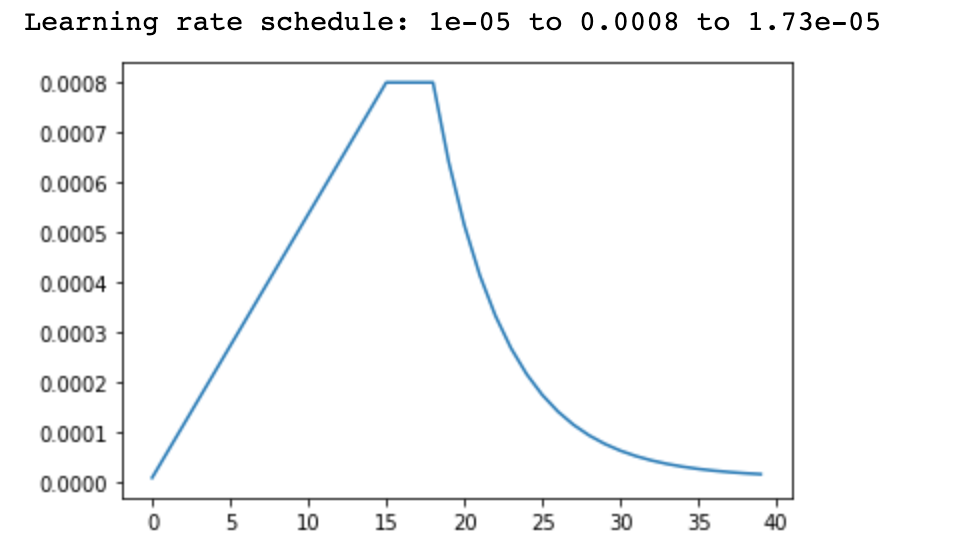
Why do we need to Ensemble Deep Neural Networks?
Ensemble learning combines the predictions from multiple machine learning models to reduce the variance of predictions and generalization error.
Each deep learning model posses certain advantages, for example, consider using the VGG16 model for feature extraction, the model does its job pretty good however it has been noticed that after substantial depth the performance of the model starts to degrade this is, in fact, the bottleneck of the VGG16. This vanishing gradient problem is solved by the ResNet Model. Thus when we make an ensemble of such neural networks, it helps to reduce the error or variance of predictions which in turn improves accuracy.
We’ll ensemble four Network Architectures
Training
When we use TPUs make sure that strategy (defined in TPU Setup block above) is applied through a scope so that the model makes use of TPUs for training. Hence the model must be defined within the strategy scope(). Repeat the above function replacing different models and compile, fit them.
Prediction
Finally, use the models to perform prediction on test_dataset and you can simply average the predictions of all the models and use it evaluation or multiply it with a number as shown(again, there are no specific numbers to be used it’s just a kind of tweaking to get the best score)
Conclusion
I hope this article has helped you train your models in a much more efficient and elegant manner. If you have any questions, feel free to drop them down below in the comments or catch me on LinkedIn.
References
- https://en.wikipedia.org/wiki/Tensor_processing_unit.
- https://machinelearningmastery.com/ensemble-methods-for-deep-learning-neural-networks/
I hope this article has helped you to get through the processing of Ensembling Deep Learning Models. If you have questions, drop them down below in the comments or catch me on LinkedIn.
Until then, I’ll catch you in the next one! 😺
Image Classification with Ensemble of Deep Neural Networks using TensorFlow + TPUs was originally published in Towards AI — Multidisciplinary Science Journal on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts



")
Recent Posts




")

