



Deep-Learning-Based Automatic CAPTCHA Solver
Last Updated on September 27, 2020 by Editorial Team
Author(s): Sergei Issaev
Computer Vision, Cybersecurity, Deep Learning
Tackling the sophisticated 10-character CAPTCHA (with code)
Disclaimer: The following work was created as an academic project. The work was not used, nor was it intended to be used, for any harmful or malicious purposes. Enjoy!
Introduction
CAPTCHAs (Completely Automated Public Turing test to tell Computers and Humans Apart) are something nearly every internet user had the experience of having to deal with. In the process of logging in or making an account, making an online purchase, or even posting a comment, many people are confronted with strange-looking, stretched, blurred, color, and shape distorted images more so resembling a Dali painting than English text.
For a long time, the 10-character blurred-text CAPTCHA was used in deployment because contemporary computer vision methods had difficulty recognizing letters against a non-uniform background, whereas humans have no problem doing so. This remains a significant issue in the field of character recognition to this day.
Therefore, in order to develop a program capable of reading the characters in this complex optical character recognition task, we will develop a custom solution specific to the problem. In this article, we will go over the start to finish the pipeline for developing a CAPTCHA solver for a specific class of CAPTCHAs.
The Data
10,000 CAPTCHA images were provided from a kaggle dataset (scraped by Aadhav Vignesh, at https://www.kaggle.com/aadhavvignesh/captcha-images). Each image the name NAME.jpg, where NAME is the solution to the puzzle. In other words, the NAME contains the correct letters in the correct sequence of the image, such as 5OfaXDfpue.
Getting a computer program to read the characters inside the image presents a significant challenge. Open source OCR software, such as PyTesseract, failed when tested on the CAPTCHAs, often not even picking up a single character from the whole image. Training a neural network with the raw images as input and solutions as output might succeed in a dataset of tens of millions, but is not very likely to succeed with a dataset of 10,000 images. A new method has to be developed.
The issue could be greatly simplified by analyzing one character at a time, rather the entire image at once. If a dataset of alphanumerics and their corresponding labels could be obtained, a simple MNIST-like neural network can be trained to recognize characters. Therefore, our pipeline looks like this:
- Invert the CAPTCHA, segment the characters, and save each alphanumeric character separately to disk (with its label).
- Train a neural network to recognize the characters of each class.
- To use our model, feed-in any CAPTCHA, invert the image, and segment the characters. Apply the machine learning model on each character, get the predictions, and concatenate them as a string. Voila.
Preprocessing
For those of you following my code on Kaggle(https://github.com/sergeiissaev/kaggle_notebooks), the following section refers to the notebook titled captchas_eda.ipynb. We begin by loading a random image from the dataset and then plotting it.

Next, using OpenCV (a very useful computer vision library available in Python and C++) the image is converted to grayscale, and then a binary threshold is applied. This helps transform the complex, multicolored image into a much simpler black and white image. This is a very crucial step — contemporary OCR technology often fails when the text is against a nonuniform background. This step removes that problem. However, we aren’t ready to OCR just yet.
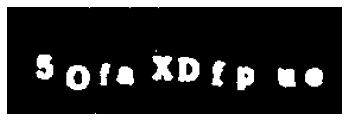
The next step is to locate the contours of the image. Rather than dealing with the CAPTCHA as a whole, we wish to split the CAPTCHA up into 10 separate images, each containing one alphanumeric. Therefore, we use OpenCV’s findContours function to locate the contours of the letters.
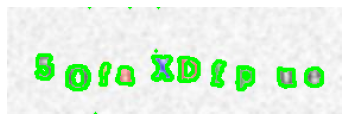
Unfortunately, most images end up with over 20 contours, despite us knowing that each CAPTCHA contains precisely 10 alphanumerics. So what are the remaining contours that get picked up?
The answer is that they are mostly pieces of the checkered background. According to the docs, “contours can be explained simply as a curve joining all the continuous points (along the boundary), having the same color or intensity”. Some spots in the background match this definition. In order to parse the contours and only retain the characters we want, we are going to have to get creative.
Since the background specks are much smaller than the alphanumerics, I determined the 10 largest contours (again, each CAPTCHA has precisely 10 alphanumerics in the image), and discarded the rest.
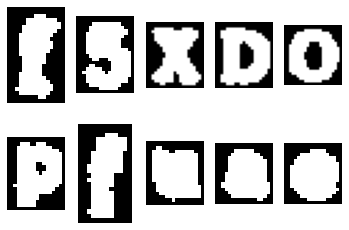
However, there is a new problem. I have 10 contours sorted in order of size. Of course, when solving CAPTCHAs, order matters. I needed to organize the contours from left to right. Therefore, I sorted a dictionary containing the bottom right corner of each of the contours associated with the contour number, which allowed me to plot the contours from left to right as one plot.
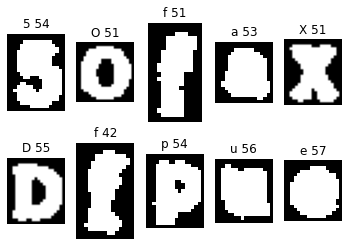
However, I noticed that many of the outputs were nonsensical — the images did not correspond to the label. Even worse, by having one image not correspond to its label, it often disrupted the order of all the downstream letters, meaning that not just one but many of the letters displayed had incorrect labels. This could prove disastrous for training the neural network, since having incorrectly labeled data can make learning much more error-prone. Imagine showing 4-year-old child letters but occasionally reciting the wrong sound for that letter — this would pose a significant challenge to the child.
I implemented two error checks. The first was for contours that are complete nonsense, which I noticed usually had very different white to black pixel ratios than ordinary letters. Here is an example:
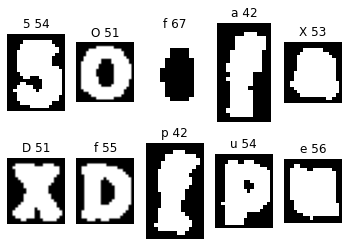
The third contour in the top row is actually the inner circle of the previous “O”. Notice how all the downstream letters are now incorrectly labeled as well. We cannot afford to have these incorrectly labeled images appended to our training data. Therefore, I wrote a rule saying that any alphanumeric with a white to black ratio above 63% or below 29% would be skipped.
Here is an example of my second error check:
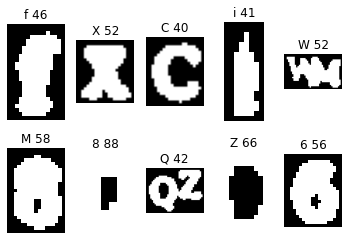
Sometimes, separate alphanumerics are touching each other slightly, and get picked up as one alphanumeric. This is a big problem because just like error check #1, all the downstream alphanumerics are affected. To solve this issue, I checked whether each image was significantly wider than longer. Most alphanumerics are taller or at least square, and very few are much wider than taller unless they contain an error of type #2, meaning they contain more than one alphanumeric.
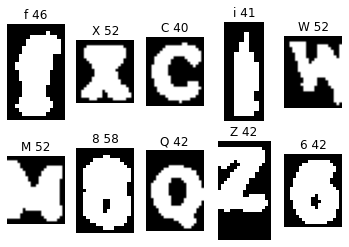
It seems the error checking works great! Even very difficult CAPTCHA images are being successfully labeled. However, now a new issue arose:
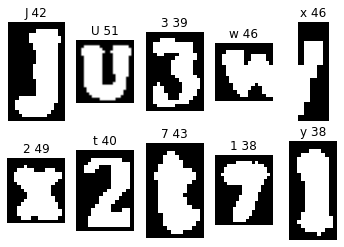
Here, the “w” in the top row matched the error check #2 criteria — it was very wide, and so the program split the image. I spent a long time trying out different hyperparameter settings wherein wide “w” and “m” images wouldn’t get split, but real cases of two alphanumerics in one image would. However, I found this to be an impossible task. Some “w” letters are very wide, and some image contours containing two alphanumerics can be very narrow.

There was no secret formula to get what I wanted to be done, so I (shamefully) had to do something I’m not really proud of — take care of things manually.
Obtaining the Training Data
For those following on Kaggle, this is now the second file, named captchas_save.ipynb. I transferred the data from Kaggle to my local computer, set up a loop to undergo all the preprocessing steps start to finish. At the end of each loop, the evaluator was prompted to perform a safety inspection of the data and labels (“y” to keep it, “n” to discard it). This isn’t ordinarily the way the author prefers to do things, but after spending enough many hours trying to automate the process the efficiency scales started to tip in the automation versus manual balance.
I got through evaluating 1000 CAPTCHAs (therefore creating a dataset of roughly 10,000 alphanumerics) in the span of watching the Social Network, switching between myself and my friend who I paid a salary of one beer for his help.

All the files that received a passing grade were appended to a list. The preprocessing pipeline looped through all the files in the list saved all the alphanumerics into their respective folders, and thus the training set was created. Here is the resulting directory organization, which I uploaded and published as a dataset on kaggle at https://www.kaggle.com/sergei416/captchas-segmented.

Ultimately, I was left with 62 directories, and a total of 5,854 images in my training dataset (meaning 10,000–5854=4146 alphanumerics were discarded).
Finally, let us begin the machine learning section of the pipeline! Let’s hop back onto Kaggle, where we will be training a handwritten digit recognition software based on the segmented alphanumerics we received in the training set. Again, existing open-source OCR libraries fail with the images that we have obtained so far.
Training the Model
To build the machine learning system, we use a vanilla PyTorch neural network. The complete code is available on Kaggle, at https://www.kaggle.com/sergei416/captcha-ml. For brevity, I will only discuss the interesting/challenging sections of the machine learning code in this article.
Thanks to PyTorch’s ImageFolder function, the data was easily loaded into the author’s notebook. There are 62 possible classes, meaning a baseline accuracy for predicting completely random labels is 1/62, or 1.61% accuracy. The author set a test and validation size of 200 images. All the images were reshaped to 128 x 128 pixels, and channels normalization was subsequently applied. Specifically for the training data, RandomCrop, ColorJitter, RandomRotation, and RandomHorizontalFlip were randomly applied to augment the training dataset. Here is a visualization of a batch of training data:

Transfer learning from wide_resnet101 was used, and training was done using Kaggle’s free GPU. A hyperparameter search was used to identify the best hyperparameters, which resulted in a 99.61% validation accuracy. The model was saved, and the results were visualized:
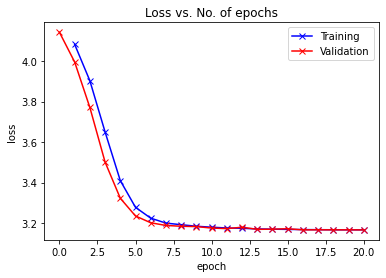
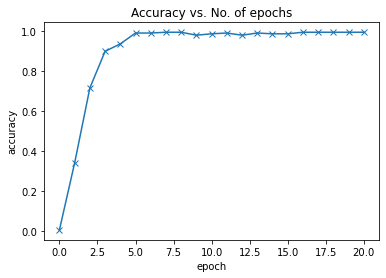
The final results demonstrate a 99.6% validation accuracy and a 98.8% test accuracy. This honestly exceeded my expectations, as many of the binary, pixelated images would be hard for even a human to decipher correctly. A quick look at the batch of training images above will show at least several questionable images.
Evaluation of our Model
The final step of this pipeline was to test the accuracy of our ready-built machine learning model. We previously exported the model weights for our classifier, and now the model can be applied to any new, unseen CAPTCHA (of the same type as the CAPTCHAs in our original dataset). For sake of completeness, the author set up a code to evaluate the model accuracy.
If even a single character is incorrect when solving a CAPTCHA, the entire CAPTCHA will be failed. In other words, all 10 predicted alphanumerics must exactly match the solution for the CAPTCHA to be considered solved. A simple loop comparing equality of the solution to the prediction was set up for 500 images randomly taken from the dataset, and checked whether the predictions were equivalent to the solutions. The code for this is in the fourth (and final) notebook, which can be found at https://www.kaggle.com/sergei416/captchas-test/.
This equivalency was true for 125/500 CAPTCHA images tested, or 25% of the test set*. While this number does seem low, it is important to keep in mind that unlike many other machine learning tasks, if one case fails, another case is immediately available. Our program only needs to succeed once but can fail indefinitely. Since our program has 1–0.25 = 0.75 probability of failure for any given try, then given n number of attempts, we will pass the CAPTCHA as long as we do not fail all n attempts. So what is the likelihood of passing within n attempts? It is
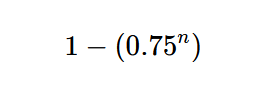
Therefore, the likelihood of n attempts is as follows:

*EDIT: The accuracy on the kaggle link is 0.3, or 30% for any single CAPTCHA (97.1% with n=10).
Conclusion
Overall, the attempt to build a machine learning model capable of solving 10-character CAPTCHAs was a success. The final model can solve the puzzles with an accuracy of 30%, meaning there is a 97.1% probability a CAPTCHA image will be solved within the first 10 attempts.
Thank you to all who made it to the end of this tutorial! What this project showed, is that the 10-character CAPTCHA is not suitable for differentiating human from non-human users and that other classes of CAPTCHA should be used in production.
Links:
Linkedin: https://www.linkedin.com/in/sergei-issaev/
Twitter: https://twitter.com/realSergAI
Github: https://github.com/sergeiissaev
Kaggle: https://www.kaggle.com/sergei416
Jovian: https://jovian.ml/sergeiissaev/
Medium: https://medium.com/@sergei740
Deep-Learning-Based Automatic CAPTCHA Solver was originally published in Towards AI — Multidisciplinary Science Journal on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts



")
Recent Posts






")