


Sora AI: Unraveling Sora’s Architecture and Working Intuitively!
Last Updated on April 2, 2024 by Editorial Team
Author(s): Prashant Kalepu
Originally published on Towards AI.
Here comes a new AI again. The Sora AI by OpenAI. A new text-to-video generative AI model has gained lots of interest and focus during the past few days.
I have been looking over it online, and most of the information available only covers the capabilities and limitations of Sora but doesn’t dive into its architecture or workings. I know many data enthusiasts are eager to know about the internal workings of this new AI, if you are a techie like me I am sure you are interested in this. Although the model and its implementation have not been released to the public yet, don’t worry, my fellow enthusiasts! We won’t sit behind and wait until then.
We are up for the challenge of keeping our brains working and attempting to figure out its details on our own. This is a fantastic opportunity for those of us who want to improve our perception and strategies in building model architectures. In this blog, we will be exploring Sora AI, its applications, and primarily, the model architecture based on my research from various online sources, the official website, and my personal knowledge and experiences.
Introduction
OpenAI is a company that has gained a lot of attention in recent years for creating mind-blowing generative AI tools. In February 2024, OpenAI announced a new text-to-video generation AI tool called Sora AI. This tool using a diffusion transformer, takes the video generation abilities to a whole new level by turning our words into rich and immersive video scenes with stunning visuals that captivate and engage the audience. Sora’s biggest development is that it doesn’t generate a video frame by frame. With Sora AI, you don’t need a Sharingan to transform your thoughts into a visual form. Do you think this is enough for the introduction? Okay then, let’s jump into the heart of our discussion today!

Understanding the Architecture of Sora AI
Are you ready to dive into the architecture of Sora AI for text-to-video generation? Great! But before we do, let’s talk about the exciting tasks involved in building such an AI.
- First of all, we need to focus on data representation.
- Then, we have to understand the context of the text (prompt) provided by the user.
- And of course, an encoder-decoder architecture is essential. But that’s not all!
- When building something, we must always strive for novelty.
And guess what? Sora AI has introduced not one, but two exciting features that we will discuss later. So, buckle up and get ready for the ride!
Before we dive into the details, let’s talk about existing research. Traditional diffusion models typically use convolutional U-Nets with downsampling and upsampling blocks as the backbone of the denoising network. However, recent studies have shown that the U-Net architecture is not essential for good performance of the diffusion model. And here’s where it gets really exciting! By incorporating a more flexible transformer architecture, transformer-based diffusion models can use more training data and larger model parameters. This opens up a world of possibilities for text-to-video generation. So, stay tuned because we’ll be discussing this further later on.
Data Representation
As an AI enthusiast, you probably understand the secret of creating a high-performing AI model — quality data! When processing image or video data, it’s common to stick with traditional methods like resizing, cropping, and adjusting aspect ratios. But, have you heard of the latest innovation in AI? Sora is the first model that uses the diffusion transformer architecture to embrace visual data diversity. This means that Sora can sample a wide range of video and image formats, maintaining their original dimensions and aspect ratios.
You may be thinking, “What’s the big deal?” Well, Sora does something remarkable by training on data in their native sizes, which results in a more natural and coherent visual narrative. Imagine capturing the full scene, ensuring that the subjects are entirely captured in the video. This approach also enhances the composition and framing of the generated videos, giving you an excellent advantage over traditional methods.

Turning visual data into patches
Do you know what the smallest unit of text in natural language processing is? It’s called a token! Just like how LLMs use tokens to unify different types of text, OpenAI has come up with a similar approach for images and videos called Patch.
What Sora does is it takes an input video, compresses the input video, and divides it into smaller blocks, or patches. But that’s just the beginning. To compress the video into a lower dimensional latent space that captures the essential features of the input data, Sora has its own video compression network. This network takes the raw video and outputs a compressed latent representation that is both temporal and spatial.
Once the video has been compressed, the latent representation is decomposed into spacetime patches. These patches are then arranged in an order, and the size of the generated video is controlled by arranging randomly initialized patches in an appropriately sized grid. It’s like putting together a puzzle but with patches instead of pieces!

Okay here is the first problem we encounter, how do you deal with the variability in latent space dimensions before feeding patches into the input layers of the diffusion transformer?
Let’s think, the first thing we have in mind, is just to remove some patches from the larger patch grid. Well, that is a good idea, but think of it: what if we removed some patches that provide really important details about the video? So what is the other way, let’s say we padded the smaller patch grids to match with larger patch grids, use a super long context window, and pack all tokens from videos although doing so is computationally expensive e.g., the multi-head attention operator exhibits quadratic cost in sequence length.
However, we know that 3D Consistency is one of the amazing features of Sora, so we can’t go with the first option of removing the patches. So what’s the way? well, one way is to use Patch n’ Pack.
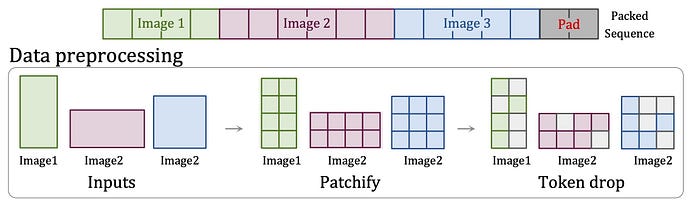
Interestingly, the patching method used in Sora should likely be similar to Patch n’ Pack, which is mentioned in the references section of the technical report. So what may be likely to happen is that the input videos are patched, then pack all the patches and pad the sequence. I think they would not consider the token drop step since it could remove the fine-grained details during training.
Model Intuition
Diffusion Transformer Model
Here comes the main part of our discussion. While Sora has covered data representation in the technical report, we’re yet to discuss its architecture. So let’s put our thinking hats on and come up with some intuitive ideas.
First, we need to consider a few facts and gather information. When designing a model architecture, we usually consider:
- Traditional methods
- Current trends
- The available research on the use case we’re solving
Speaking of the traditional methods, we talked about using diffusion models with U-Net as a backbone. However, it’s worth noting that U-Net is not always necessary and can be replaced by transformers to focus on temporal changes and subject context in the video.
Now current trends, the text-to-video models have been evolving every year. We hear new approaches to solve the shortcomings of the previous models.
So here comes another intuition to come up with the idea of architecture. There are many varieties of diffusion models, like denoising diffusion, stable diffusion, diffusion with transformer, latent diffusion model, and cascaded diffusion model.
So what is the best model? Let me say, all these models I googled for 2 days reading about them from research papers and blogs etc.
Before continuing to discuss our intuition, I want you to pause reading for a few minutes and read about the above models. Believe me, you can come up with an intuition easily after that.
If you have covered till now, then you sure understand why Sora is built on Diffusion transformer architecture. It helps in reducing unnecessary upsampling and downsampling tasks. So we got with the foundation, that we are going to use Diffusion Transformer architecture.
Now, is there a way we can optimize and improve the performance of this base model? If you are from the machine learning community, I’m sure you heard about Ensemble learning.
Let’s say that, if somehow you could use a group of diffusion transformer models to form a golden model, it sure will increase the model’s performance. Yes, if you have read about the models I mentioned before, then you could tell cascade diffusion models do a similar thing.
I came across the paper ImaGen Video by Google in the technical report that discusses the Cascade of diffusion models, which is a highly effective method for scaling diffusion models to produce high-resolution outputs. This technique involves generating an image or video at low resolution and then increasing the resolution sequentially through a series of super-resolution diffusion models.
The cascade of diffusion models is a useful approach for generating high-quality videos or images that require high resolution. By using a series of super-resolution diffusion models, this technique can produce excellent results while maintaining the model’s ability to scale and work with large datasets.
And now, in the diffusion module what kind of diffusion model would you like to use. And let’s say diffusion probabilistic models. These models work by adding noise to training data and then learning to recover the data by reversing the noise process. They are parameterized Markov chains trained using variational inference to produce samples that match the data after a finite time. You may sure think it is the perfect choice for our use case since we are also trying to generate videos from the noise. But do you know latent diffusion models are designed to reduce the computational complexity of diffusion probabilistic models (DPM)?
Considering that Sora generates high-resolution videos with great visuals, it’s likely that it incorporates a similar architecture. It should replace the U-Net backbone with a transformer architecture for all the diffusion models in the cascade. By using a group of diffusion transformer models, its performance is likely to be increased, similar to the concept of ensemble learning in machine learning. Furthermore, an attention mechanism at each diffusion model would help maintain the relationship between the text prompt and the visual it generates.
GPT for Language Understanding
Now discussing another aspect of the architecture, which is its ability to understand human language, resulting in its great performance. According to the technical report, Sora uses a caption generator with GPT as its backbone to turn smaller captions into detailed and descriptive ones. One advantage of Sora is that GPT can process and understand human instructions very well. Similar to DALLE, OpenAI trained a highly descriptive captioner model and then used it to produce text captions for all training videos. By adding an internal captioner, Sora AI can generate high-quality videos that accurately follow user prompts.
To sum up, the user prompt is sent to the GPT module, which converts it into a detailed and descriptive prompt. At the same time, the patch grid should have been passed to the diffusion transformer model, which is a cascade of diffusion models. The diffusion transformer iteratively denoises the 3D patches and introduces specific details according to the recaptioned prompt. In essence, the generated video emerges through a multi-step refinement process, with each step refining the video to be more aligned with the desired content and quality.

Finally, we covered most of the part, we made a few intuitions, and brainstormed. Now, let’s read through the information mentioned everywhere online.
Capabilities of Sora AI
- Video generation: Can generate high-fidelity videos, including time-extended videos, and videos with multiple characters
- Video editing: Can transform the styles and environments of input videos according to text prompts
- Image generation: Can generate images
- Simulate virtual worlds: Can simulate virtual worlds and games, such as Minecraft
- Interacting with still images: Can transform a single frame into a fluid, dynamic video
Limitations of Sora AI
- Short video length: Sora can create videos only up to one minute in length.
- Simulations: Sora may find it difficult to understand the physics of complex scenes and cause-and-effect relationships.
- Spatial details and time: Sora may get confused between left and right and may find it challenging to provide accurate descriptions of events over time.
- Lack of implicit understanding of physics: Sora may not follow the “real-world” physical rules.
- Complex prompts: Sora may struggle with complex prompts.
- Narrative coherence: Sora may have difficulty maintaining narrative coherence.
- Abstract concepts: Sora may not be able to understand abstract concepts.
Conclusion
In conclusion, Sora AI by OpenAI is an exciting new model that takes text-to-video generation to a whole new level. With its diffusion transformer architecture, visual data diversity, and patch-based approach, Sora has the potential to revolutionize the way we create and consume videos.
I have done my best to present the intuitions. Please correct me where you think I may be mistaken. I would appreciate any feedback, and I’m open to suggestions for the topic you want to know.
Finally, thank you for taking the time to read my blog!
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

