



Inside DBRX: Databricks’ Impressive Open Source LLM
Last Updated on April 1, 2024 by Editorial Team
Author(s): Jesus Rodriguez
Originally published on Towards AI.
I recently started an AI-focused educational newsletter, that already has over 165,000 subscribers. TheSequence is a no-BS (meaning no hype, no news, etc) ML-oriented newsletter that takes 5 minutes to read. The goal is to keep you up to date with machine learning projects, research papers, and concepts. Please give it a try by subscribing below:
TheSequence U+007C Jesus Rodriguez U+007C Substack
The best source to stay up-to-date with the developments in the machine learning, artificial intelligence, and data…
thesequence.substack.com
The open-source generative AI landscape is experiencing tremendous momentum. Innovation comes not only from startups like HuggingFace, Mistral, or AI21 but also from large AI labs such as Meta. Databricks has been one of the tech incumbents exploring different angles in open source generative AI, mainly after the acquisition of MosaicML. A few days ago, Databricks open sourced DBRX, a massive general-purpose LLM that show incredible performance across different benchmarks.

DBRX builds on the mixture-of-experts(MoE) approach used by Mixtral which seems to be more and more the standard to follow in transformer based architecutures. Databricks released both the baseline model DBRX Base as well as the intstruction fine-tuned one DBRX Instruct. From the initial reports, it seems that Databricks’ edge was the quality of the dataset and training process although there are few details in those.
Architecture
DRRX is a large language model that operates on a transformer-based, decoder-only framework, specifically designed to predict the next token in a sequence. It is built upon a sophisticated mixture-of-experts (MoE) structure that boasts a total of 132 billion parameters, though it only engages 36 billion parameters for any given input. This model was enriched through training on a dataset comprising 12 trillion tokens, which includes both text and code. DBRX distinguishes itself by employing a more nuanced approach with 16 smaller experts, out of which 4 are selected for a task, unlike its contemporaries, Mixtral and Grok-1, which utilize 8 experts and choose 2. This approach results in a vastly increased number of potential expert combinations — 65 times more, to be precise — enhancing the model’s quality. Base incorporates advanced techniques such as rotary position encodings, gated linear units, and grouped query attention for improved performance, and it utilizes the GPT-4 tokenizer.
The dataset for DBRX’s training was meticulously compiled and is believed to be twice as effective, token-for-token, compared to the data used in previous models developed by the organization. This new dataset benefited from comprehensive data processing and management tools, facilitating an optimized training regimen that notably enhanced model quality through strategic adjustments in the data mix.
Training
DBRX’s development spanned three months, relying on 3072 NVIDIA H100 GPUs connected via a 3.2Tbps Infiniband network. This period marked the culmination of extensive preparatory work, including dataset research and scaling experiments, all part of the ongoing evolution of language model development. Notably, training the MoE variant of Base proved significantly more compute-efficient compared to traditional models.
This efficiency breakthrough was a part of an overarching advancement in the model’s training pipeline, now nearly four times more compute-efficient compared to ten months prior. Such efficiency gains were achieved through a combination of architectural innovations, optimization techniques, and, critically, the use of higher-quality training data.
Throughout the development of DBRX, a suite of proprietary tools was utilized for data management, processing, and model training, ensuring a seamless and integrated workflow. These tools allowed for extensive exploration, cleaning of data, and efficient model training across a vast array of GPUs, culminating in a streamlined process for model refinement and deployment.
Inference
The architecture of DBRX enables a delicate balance between model quality and inference efficiency, outperforming dense models in this regard. For instance, despite its size, DBRX achieves double the inference throughput of comparable models due to its efficient use of active parameters. The model offers enhanced performance metrics across a variety of benchmarks, setting new standards for both quality and efficiency.
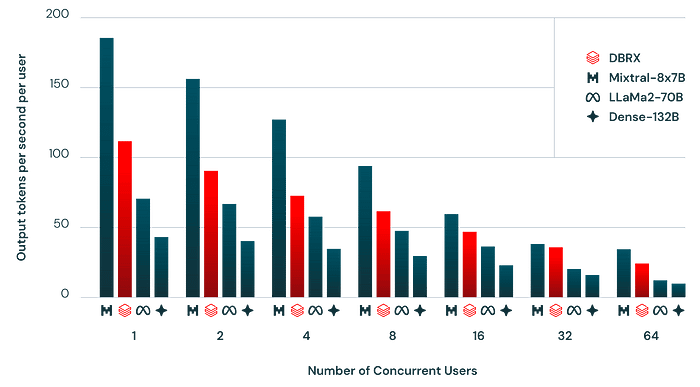
DBRX Instruct
DBRX also comes in a specialized version designed for instruction-following tasks, known as DBRX Instruct. This variant shares the MoE architecture, utilizing a targeted training approach to excel in applications requiring brief interactions.
Evaluation
DBRX and its instruction-following variant were rigorously evaluated against both open source and commercial models, showcasing superior performance across a range of metrics, including general knowledge, commonsense reasoning, and specialized domains such as programming and mathematics.

The model demonstrates remarkable proficiency in handling long-context inquiries, providing insights into its capabilities and the potential applications in various fields.

RAG is another area in which DBRX excels

Using DBRX
DBRX and DBRX Instruct are accessible for implementation via the HuggingFace platform, ensuring a straightforward integration process for users. The models require significant memory for operation but promise a powerful toolset for addressing complex language understanding and generation tasks, as demonstrated through practical examples.
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("databricks/dbrx-instruct", trust_remote_code=True, token="hf_YOUR_TOKEN")
model = AutoModelForCausalLM.from_pretrained("databricks/dbrx-instruct", device_map="cpu", torch_dtype=torch.bfloat16, trust_remote_code=True, token="hf_YOUR_TOKEN")
input_text = "What does it take to build a great LLM?"
messages = [{"role": "user", "content": input_text}]
input_ids = tokenizer.apply_chat_template(messages, return_dict=True, tokenize=True, add_generation_prompt=True, return_tensors="pt")
outputs = model.generate(**input_ids, max_new_tokens=200)
print(tokenizer.decode(outputs[0]))
DBRX represents a major upgrade in Databricks’ LLM stack. Together with their enterprise distribution, it can become one of the most important open source LLM models in the new wave of generative AI.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

