



Predicting Multiple Tokens at the Same Time: Inside Meta AI’s Technique for Faster and More Optimal LLMs
Last Updated on May 7, 2024 by Editorial Team
Author(s): Jesus Rodriguez
Originally published on Towards AI.
I recently started an AI-focused educational newsletter, that already has over 165,000 subscribers. TheSequence is a no-BS (meaning no hype, no news, etc) ML-oriented newsletter that takes 5 minutes to read. The goal is to keep you up to date with machine learning projects, research papers, and concepts. Please give it a try by subscribing below:
TheSequence | Jesus Rodriguez | Substack
The best source to stay up-to-date with the developments in the machine learning, artificial intelligence, and data…
thesequence.substack.com
Next token prediction has long been associated with the magic of LLMs. The idea that models trained to “predict the next word” could show such incredible capabilities at scale is nothing short of formidable. However, next token prediction also represents one of the major limitations of LLMs. Scale is one of the obvious limitation of the next toke prediction model as there is only so much you can do one token at a time. Probably the more interesting limitation is related to cost as LLMs assign the same computation costs to tokens regardless of their importance for a given task. Finally, single-token prediction methods predominantly captures local patterns and neglects complex decision-making, requiring significantly more data than human children to achieve comparable fluency levels. Recently, a collaboration from researchers from Meta AI Research, CERMICS, Ecole des Ponts ParisTech and LISN Université Paris-Saclay produced a paper proposing a technique for multi-token prediction which aims to address some of the aforementioned limitations in LLMs.
Multi-Token Prediction
The core of the research paper is based on a multi-token prediction task as an alternative to the single token prediction model. During training, this approach requires the model to predict multiple future tokens simultaneously — specifically, four tokens using a shared core and four distinct output heads. In the testing phase, typically only the next-token prediction head is used. Optionally, the other heads can assist in accelerating the inference process. This method has demonstrated notable improvements in code-based tasks, especially as model sizes increase.

The multi-token prediction approach outlined in the paper excels in two key areas:
1) Memory-Efficient Implementation
A major challenge in training multi-token predictors is managing GPU memory usage effectively. Modern large language models (LLMs) face a bottleneck due to the large size of their vocabulary compared to the dimensions of latent representations. By sequentially processing each output head and accumulating gradients at the trunk, researchers have devised a method to optimize memory usage during both the forward and backward operations.
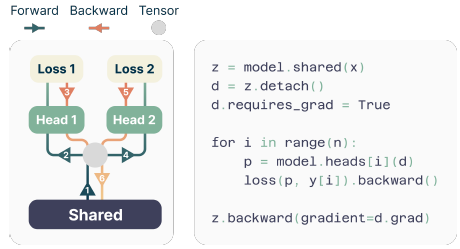
2) Fast Inference
For inference, the basic application involves using the next-token prediction head for autoregressive predictions and discarding the rest. However, additional output heads can be utilized to enhance the speed of decoding, employing methods such as blockwise parallel decoding. These methods allow for faster and potentially more efficient text generation.
The Results
Researchers tested models ranging from 300 million to 13 billion parameters on programming-related tasks, evaluating their performance on various benchmarks. While smaller models underperformed compared to baselines, larger models showed superior performance. The studies highlighted the potential of multi-token prediction to improve performance significantly across various model sizes and applications.

Why Does Multi-Token Prediction Work?
The effectiveness of multi-token prediction in programming and small-scale reasoning tasks can be attributed to its ability to reduce the gap between training and real-time generation. This method assigns implicit weights to tokens based on their relevance, helping to maintain the text’s continuity and relevance during generation. By focusing on critical decision points in text generation, multi-token prediction aids in producing more coherent and contextually appropriate outputs.
Challenges and Possibilities
The multi-token prediction approach seems like a trivial step in the evolution of LLMs but also has major limitations. For starters, the technique hasn’t been tested across major models which opens the door to all sorts of unexpected challenges. Additionally, the initial results suggest that the multi-token prediction approach is only effective in super large model which leaves out an entire universe of LLMs. Despite those limitations, the multi-token prediction approach seems like a technique worth exploring that can unlock new possibilities in the scale of LLMs.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


