



StyleGAN2: Improve the quality of StyleGAN
Last Updated on April 1, 2023 by Editorial Team
Author(s): Albert Nguyen
Originally published on Towards AI.
This post is in the series StyleGAN architectures.
Recap: StyleGAN achieves style-based image generation by disentangling styles from randomness. It allows us to control the synthesis by scaling the size and localizing the latent codes.
StyleGAN achieves state-of-the-art performance in generating images. However, it carries out a systematic problem with artifacts in generated images. These artifacts often occur at the 64×64 resolution and worsen at higher resolutions. Researchers found that there are two critical reasons cause these artifacts: The flaw in the architecture design of StyleGAN and Progressive Growing.

This article will explore why StyleGAN made these artifacts and how researchers successfully removed them in StyleGAN2.
I have explained the architecture of StyleGAN in my previous post. Therefore, you should have a look for a better experience in this article.
The architecture design — Weight demodulation
When analyzing the behavior of StyleGAN, researchers found a flaw in the architecture design, causing the artifacts. They believe the Adaptive Normalization layers, by controlling the feature map statistics, accidentally create artifacts.
The AdaIN (Adaptive Normalization) layer is a core component in each block of the StyleGAN generator. It allows us to have features localized in each block of the network. But, unfortunately, it puts pressure on the Generator to generate more details, and the Generator ends up trying to leak some information to the next block by creating a spike that dominates the statistic of the feature map.
It is like a rebellion of the Generator when we mistreat it and abuse it, and it starts to stand up for its own sake: “I won’t give you all these within a block.” I know this may go far from an AI perspective, but the experiments support the idea.
The original StyleBlock consists of 3 components: modulation, convolution, and normalization. StyleGAN2 bakes three modules into a single convolution.
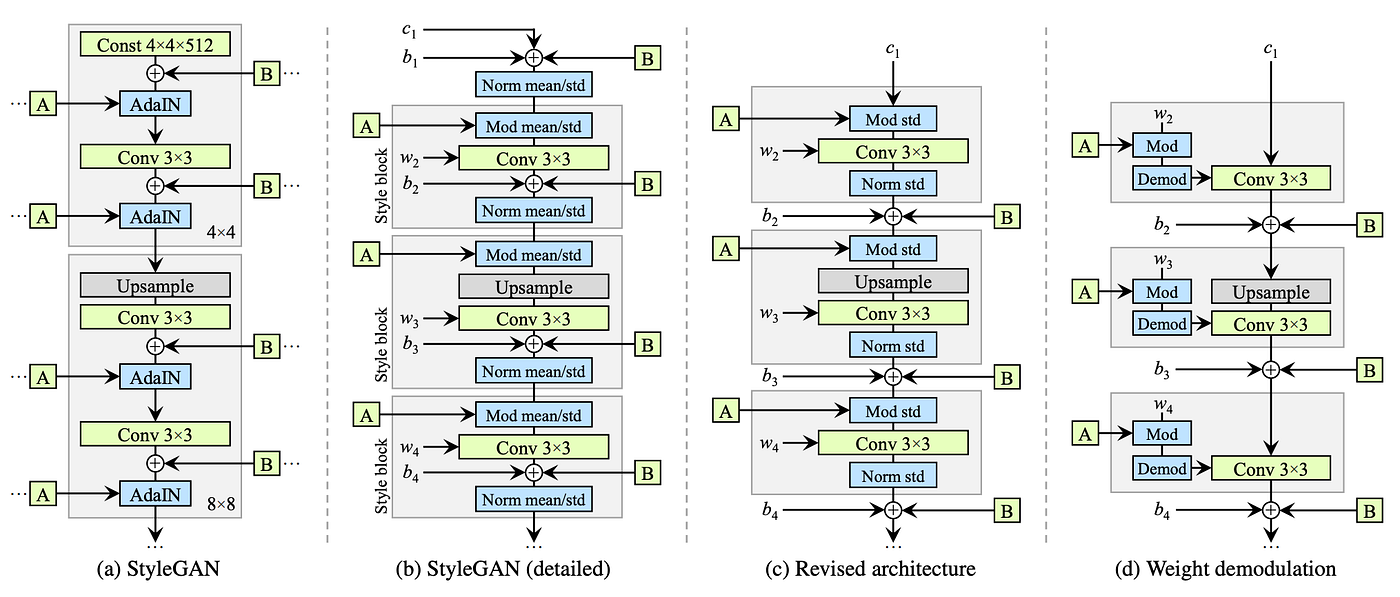
The modulation scales the input feature maps of the convolution based on the incoming style. The normalization attempts to remove the effect of the input on the statistic of the output feature maps. In fact, we can implement the modulation and normalization by scaling the weight of the convolution layer. Therefore, StyleGAN2 bakes the whole block into a single convolutional layer and offers a relaxed statistic restriction. Doing this does not affect FID while the artifacts are removed:

What are the statistics of the feature map?
The statistics of the feature map tell us the distribution of the feature vector at each location of the map. These vectors’ size and direction decide the image’s content. For example, we have a 1-dimensional vector [x], and the Generator will give us a photo of a man when x < 0 and a woman when x > 0. The distributions control the probabilities of such outcomes. And the normalization turns the distributions into zero mean and standard deviation and makes the probabilities of such outcomes equal.
Progressive Growing — Alternative Generator Architecture
The progressive growing success in stabilizing high-resolution image synthesis. But it introduces another type of artifact— phases artifacts.
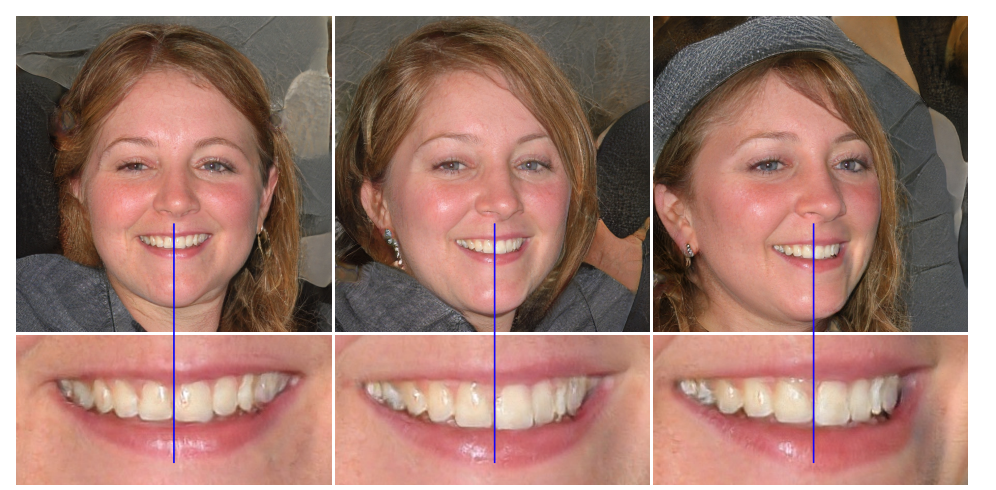
The image above shows that the teeth remain unchanged while the head is moving. You can also spot the eyes looking in the same direction.
Researchers believe the problem is that in progressive growing, each resolution serves momentarily as the output resolution, forcing it to generate maximal frequency detail. A property of high-frequency details is that they are shift invariance, causing teeth or eyes to stay the same even when the features shift. StyleGAN2 removes the progressive growing by simplifying the MSG-GAN architecture:
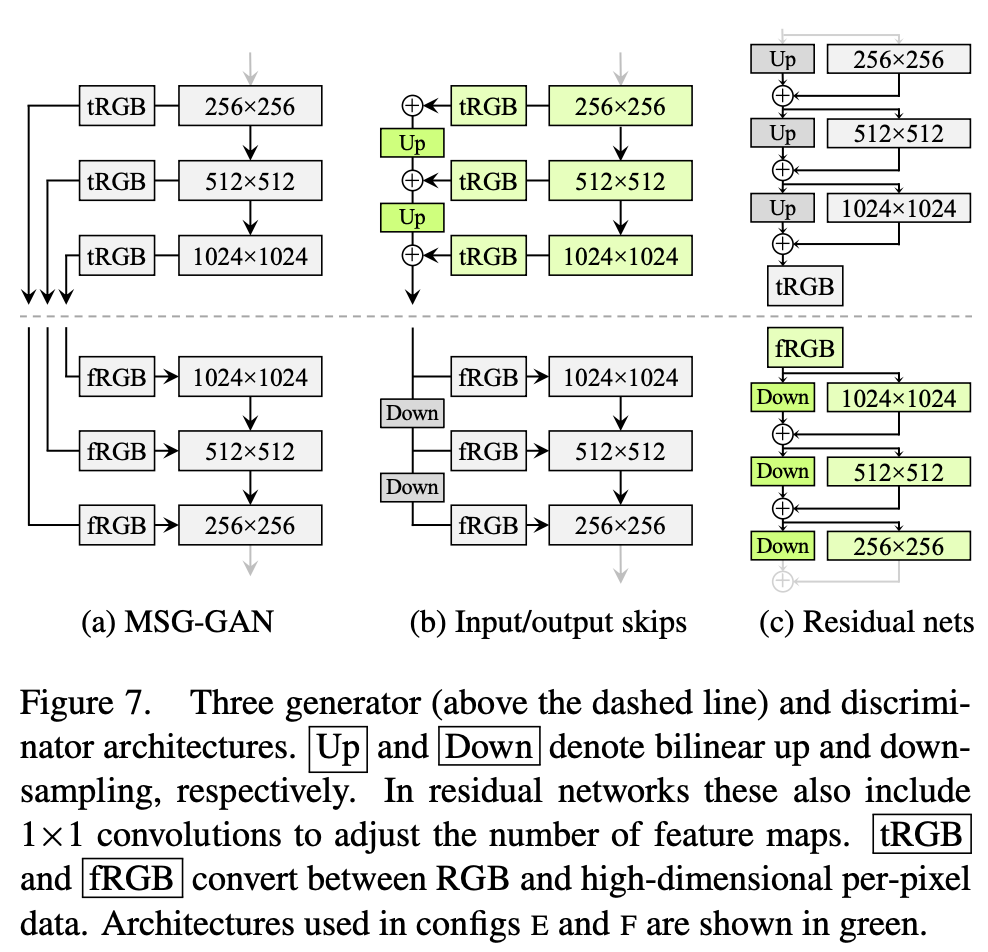
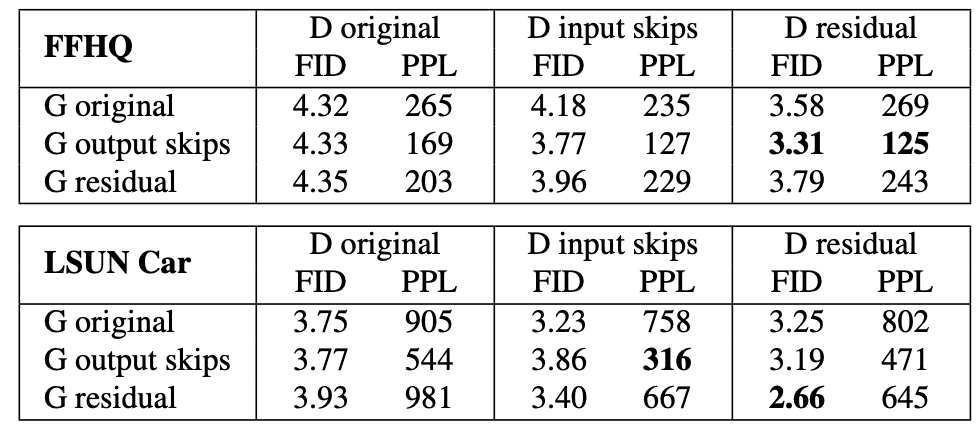
While trained without progressive growth, this architecture remains a desirable property because the Generator will initially focus on low-resolution features and slowly shift its attention to finer details. The result shows that adding skip-connection helps improve the FID. While the residual only improves on LSUN CAR but hurts the model performance on FFHQ.
Path Length — Lazy regularizer
According to the paper, the gradients should have close to an equal length regardless of latent w or the image-space direction, indicating that the mapping from the latent space into image space is well conditioned. Therefore, we have a regularization to encourage fixed magnitude gradient:
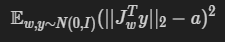
For single latent code w, by minimizing this term, we obtain an orthogonal Jacobian matrix J_w, which gives us fixed-magnitude gradients. This regularizer improves model consistency and reliability.
Bonus: Spectral Normalization is a widely used technique in the training of GANs. The work in the paper also explored its effects on StyleGAN2:
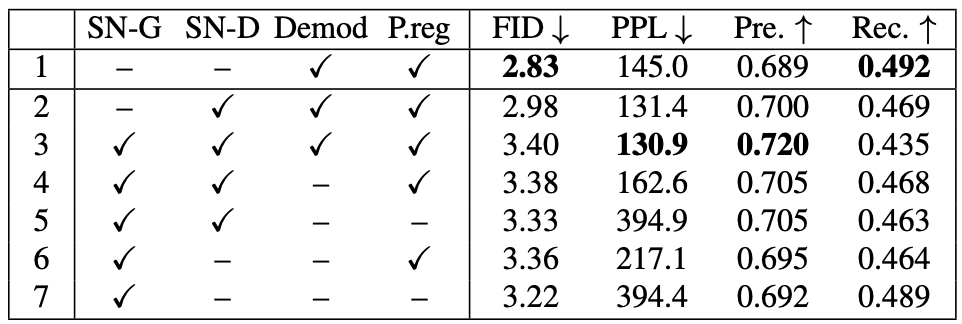
The demodulation already removes the effects of Spectral Norm (SN) from StyleGAN2 blocks but not in the tRGB layers. Also, applying SN to the discriminator resulted in increasing in FID. Therefore, StyleGAN2 works better without Spectral Normalization.
Conclusion
StyleGAN2 identified and fixed the image quality issue of the original StyleGAN. By using demodulation and removing the Progressive Groding with MSG-GAN, StyleGAN2 successfully removes the artifacts in generated images. Furthermore, the Path Length regularizer help improve the quality of generated images and make StyleGAN2 state-of-the-art in image generation on several datasets like LSUN, FFHQ, etc.
The source code of StyleGAN2 can be found at https://github.com/NVlabs/stylegan2
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


